Интересное сегодня
Автоматизация анализа разговорных данных: Инструмент Autoscribe
Современные технологические достижения постоянно меняют методы проведения исследований. В области исследований коммуникации — охватывающей такие дисциплины, как лингвистика, психология, бизнес и речевая патология — появилось множество новых инструментов для автоматизации задач кодирования и анализа данных, которые ранее выполнялись вручную. Например, инструменты обработки естественного языка (Natural Language Processing, NLP) используются для таких задач, как разметка частей речи (например, Chiche & Yitagesu, 2022), сегментация тем (например, Arnold et al., 2019) или анализ тональности (например, Wankhade et al., 2022). Другие инструменты, такие как Autoscore (Barrett et al., 2019; Borrie et al., 2019) и ALIGN (Duran et al., 2019), помогают преобразовывать лингвистические данные в количественные показатели, которые могут использоваться в статистическом анализе. Преимущество этих инструментов заключается в их эффективности и воспроизводимости. Задачи, которые требуют много времени и ресурсов при ручном выполнении, могут быть выполнены быстро, с минимальными затратами и часто полностью воспроизводимы. В некоторых случаях инструменты работают в значительной степени автоматически, но из-за текущих технологических ограничений все еще требуют человеческого труда или надзора для выполнения определенных задач (например, Pfeifer et al., 2024). Например, инструменты могут требовать проверки и исправления человеком для обеспечения более высокой точности (как в случае с разработанным здесь инструментом). Даже в этих случаях объем данных, который может быть проанализирован и обработан, значительно превышает то, что может быть сделано только человеческими усилиями.
Автоматическое распознавание речи (ASR) и его ограничения в исследовании разговоров
Одной из технологий, которая оказалась особенно полезной как для исследований речи, так и языка, является технология автоматического распознавания речи (Automatic Speech Recognition, ASR). Она позволяет преобразовывать произнесенную речь из аудиофайла в читаемый текст. Эта технология открывает значительные возможности для лингвистических исследований. Например, ASR позволила исследователям масштабировать исследования до гораздо больших корпусов и проводить более быстрый анализ устной речи, что было бы непрактично при ручной транскрипции. Однако одной из основных проблем инструментов ASR является то, что они, как правило, ориентированы на монологическую речь (то есть речь одного говорящего; Lopez et al., 2022). Соответственно, хотя некоторые инструменты способны транскрибировать записи разговоров, они часто плохо подходят для исследований интерактивной речи и языка. Это делает необходимым разработку инструментов, лучше приспособленных для обработки транскрипции и кодирования разговоров для последующего анализа.
Ключевые особенности и вызовы при разработке инструментов для анализа разговоров
Адекватная разработка инструментария для анализа разговоров должна сосредоточиться на ключевых различиях между монологами и диалогами и на том, как эти различия могут быть эффективно устранены. Наиболее очевидное отличие разговорной речи от монологов заключается в том, что разговор всегда включает в себя как минимум двух собеседников. Таким образом, метки должны четко обозначать, кто говорит и когда. Далее, в разговорах происходит смена реплик (turn-taking). Собеседники чередуют роли говорящего и слушающего. Реплики в разговоре должны быть аннотированы (то есть сегменты речи и не-речи для каждого должны быть разделены), а анализ фонетических и просодических особенностей речи, а также динамики смены реплик (например, задержек между репликами) требует точного и прецизионного выравнивания этих сегментов по времени. Более того, хотя простые модели смены реплик (и большинство автоматизированных инструментов, используемых в настоящее время для транскрипции речи) предполагают, что одновременно говорит только один собеседник, в реальных устных диалогах это не всегда так. Скорее, разговор характеризуется частыми прерываниями, перекрытием реплик и вставками (Brusco et al., 2020; Yuan et al., 2007). Следовательно, одновременные сигналы должны эффективно управляться. Наконец, лингвистические конвенции разговора отличаются от тех, которые часто используются в монологах. Разговоры содержат обратную связь (backchannels, например, «ммм», «угу»), а также больше неполноты, слов-паразитов и разговорных выражений, чем монологи (например, Fox Tree, 1999). Таким образом, поскольку инструменты ASR часто обучаются на монологической речи (например, Ardila et al., 2020; Panayotov et al., 2015), они не способны улавливать эти типы слов. Фактически, некоторые инструменты используют читабельность, намеренно отфильтровывая эти элементы (например, Chen et al., 2022; Jamshid Lou & Johnson, 2020). Однако эти типы слов часто намеренно используются говорящими для различных целей (например, сигнализирование вовлеченности, содействие поддержанию хода разговора, выражение неуверенности, управление дискурсом), что требует их включения во многие типы анализа (например, Clark & Fox Tree, 2002; Knudsen et al., 2020).
Praat TextGrid как формат для аннотации разговорных данных
Учитывая эти факторы, становится важным рассмотреть формат, в котором автоматизированный инструмент мог бы наилучшим образом кодировать разговорные данные, обеспечивая при этом эффективную обработку сложности и глубины информации. Одним из особо эффективных форматов является Praat TextGrid. Praat — это доступное и открытое программное обеспечение, предлагающее ряд функций для лингвистического анализа (Boersma & Weenink, 2024). Этот инструмент широко используется в исследованиях речи и языка. По данным Google Scholar, он был процитирован более 32 000 раз. Ключевой для данной статьи функцией является TextGrid, которая может использоваться для сегментации, аннотирования и транскрипции разговорных данных. Praat TextGrids позволяют создавать несколько слоев (tiers), каждый из которых содержит различную информацию. Таким образом, разговорные данные от каждого собеседника могут быть аннотированы на отдельном слое, что обеспечивает простое разграничение нескольких (и часто одновременно говорящих) собеседников. Внутри слоя каждого собеседника могут быть добавлены границы для разграничения сегментов речи и не-речи, а речевые сегменты могут быть транскрибированы. Это обеспечивает точную информацию относительно времени реплик в разговоре, что может быть важно для анализа разговоров (например, при исследовании задержек между репликами). Более того, поскольку транскрипты каждого собеседника содержатся на разных слоях, одновременные речевые сигналы обрабатываются более эффективно, чем это может быть охвачено простой линейной транскрипцией разговора. Praat TextGrids позволяют интегрировать аудио, визуализации аудио (то есть звуковые волны и спектрограммы) и лингвистические аннотации в одном месте, что позволяет использовать разговорные данные для различных анализов как в области речи, так и языка. Поскольку разговор включает в себя взаимодействие и координацию нескольких уровней языка (например, фонетического, синтаксического и семантического) в тандеме, эта интеграция информации особенно выгодна для исследований в этой области. Следовательно, Praat TextGrids предлагают функциональный и универсальный формат для разговорных данных, который может использоваться для множества различных типов анализа.
Представление инструмента Autoscribe
Хотя Praat TextGrids отличаются практичностью и полезностью, их ручное создание является утомительным и трудоемким процессом. По опыту наших лабораторий, этот процесс, который включает создание оболочки TextGrid с правильными параметрами, аннотирование границ между сегментами речи и не-речи, а также транскрипцию речи, занимает в среднем около 15 минут на каждую минуту разговорной речи. Хотя существуют инструменты, автоматизирующие отдельные шаги в этом процессе, существует мало автоматизированных инструментов, способных завершить весь процесс создания TextGrid. Лю и коллеги (Liu et al., 2023) создали автоматизированный инструмент транскрипции, способный преобразовывать транскрипты в TextGrids, и показали, что этот инструмент эффективно работает с высокой степенью точности. Однако формат транскрипции этого инструмента (то есть формат транскрипции «Codes for the Human Analysis of Talk» [CHAT]; MacWhinney, 2000) содержит многие особенности, которые не способствуют определенным типам анализа. Например, высказывания делятся на Cunit (то есть главные предложения с соответствующими зависимыми), а не на межпаузальные единицы (единицы речи без пауз), что делает невозможным анализ границ реплик. Кроме того, этот инструмент является программой командной строки, что делает его недоступным для тех, кто не имеет хотя бы базового понимания компьютерного программирования. Ма и коллеги (Ma et al., 2024) также создали аналогичный инструмент. Однако этот инструмент не является бесплатным или открытым исходным кодом и не гарантирует конфиденциальность участников (то есть аудиозаписи отправляются третьей стороне).
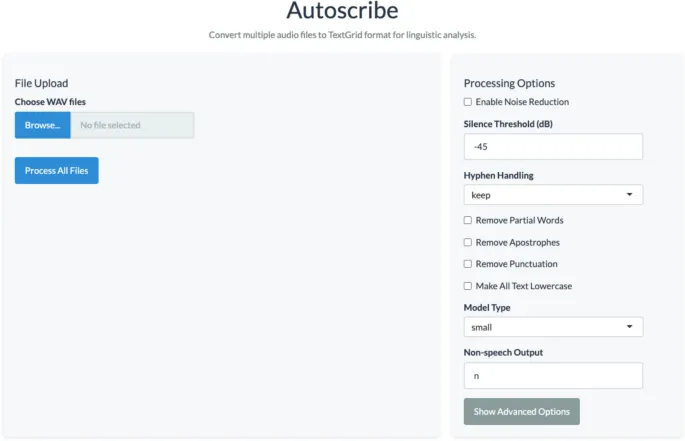
Соответственно, целью данного проекта было разработать и валидировать удобный для пользователя автоматизированный инструмент (доступный как в виде настольного приложения, так и в виде пакета R) для сегментации и транскрипции разговоров. Скриншот настольного приложения можно увидеть на рис. 1. Этот инструмент, Autoscribe, преобразует записи двусторонних разговоров (с записью каждого собеседника на отдельный канал) в Praat TextGrids с выровненными по времени границами реплик между сегментами речи и не-речи, а также транскрипцией всего произнесенного диалога. Учитывая ограничения автоматического распознавания речи и инструментов выравнивания границ, нашей целью здесь было не полностью устранить необходимость человеческого надзора в процессе создания TextGrid. Скорее, мы стремились ограничить участие человека-кодировщика проверкой и исправлением автоматически сгенерированных TextGrids и, таким образом, значительно сократить время, необходимое для создания точных TextGrids. Важно отметить, что Autoscribe является открытым исходным кодом, прост в использовании и легко доступен для людей с минимальным опытом или без опыта программирования. Кроме того, инструмент соответствует этическим стандартам защиты данных и конфиденциальности участников (например, соответствует HIPAA). В этой статье мы начнем с объяснения разработки инструмента. Затем мы опишем методы и результаты процесса валидации нашего инструмента. Это включает тщательную оценку эффективности и точности создания TextGrid для двух корпусов разговоров с несколькими различиями (например, возраст участников, диалект участников, среда записи). Наконец, мы завершим инструкциями для исследователей и клиницистов, заинтересованных в применении и использовании инструмента.

Описание инструмента Autoscribe
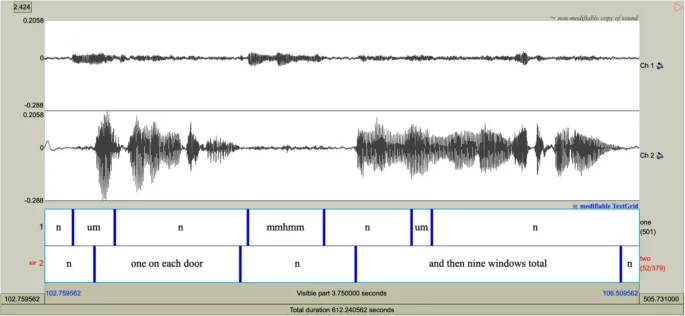
Autoscribe разработан для приема двухканального файла .wav с речью (один канал для каждого собеседника) и создания транскрибированной TextGrid. Пример фрагмента заполненной TextGrid показан на рис. 2. Инструмент использует языки программирования R, Python и Praat совместно для подготовки файла, оценки реплик, разделения файла .wav на реплики, транскрипции каждой реплики, объединения временных меток и транскрипции, а также создания TextGrid, которая может быть импортирована в Praat. Разговоры разделяются путем разметки границ между единицами речи (с паузами не более 0,5 секунд, хотя это может быть отрегулировано; см. опцию «minimum silent interval» в Таблице 1) и не-речью. Внутри каждой границы вся речь транскрибируется слово в слово, а сегменты не-речи обозначаются строчной буквой «n» (хотя конкретная строка, обозначающая не-речь, может контролироваться конечным пользователем).
Таблица 1: Настройки, контролируемые пользователем Autoscribe
| Опция | Значение по умолчанию | Альтернативы |
|---|---|---|
| Минимальный интервал тишины (секунды) | 0.5 | [настраиваемый пользователем] |
| Строка для обозначения не-речи | "n" | [настраиваемая пользователем] |
| Модель Whisper | base | small, medium, large |
| Пользовательский промпт Whisper | (предназначен для обработки слов-паразитов и неполноты) | [настраиваемый пользователем] |
| Шумоподавление | False | True |
| Пороговое значение для разделения каналов (dB) | -30 | [настраиваемый пользователем] |
| Удаление пунктуации | False | True |
| Замена дефисов на пробелы | False | True |
| Удаление частичных слов | False | True |
Транскрипция использует модель OpenAI Whisper, модель обработки речи, обученную на более чем 680 000 часов многоязычного аудио. Модель, открыто выпущенная OpenAI, лучше всего подходит для транскрипции английского языка, но также хорошо показала себя для других языков, таких как испанский и немецкий. Существует несколько опций для использования моделей разных размеров (например, base, small, medium, large); точность транскрипции, как правило, увеличивается с увеличением размера моделей, но время вычислений также увеличивается. По умолчанию Autoscribe использует пользовательский промпт, предназначенный для помощи Whisper в транскрипции слов-паразитов и неполноты. Важно отметить, что, как и многие функции, пользовательский промпт может быть настроен пользователем в соответствии с потребностями каждой ситуации. Помимо промпта, Autoscribe предлагает несколько других опций в зависимости от потребностей пользователя. Таблица 1 освещает эти опции. Кроме того, описание того, когда определенные опции могут быть наиболее подходящими, включено в руководство по адресу https://humaninteractionlab.com/tools/autoscribemanual.
Важно отметить, что поскольку все расчеты происходят локально (то есть не рассчитываются на сервере, а на собственном компьютере пользователя), инструмент соответствует стандартам конфиденциальности данных и конфиденциальности участников. Никакие данные не передаются внешним организациям. Это означает, однако, что характеристики компьютера пользователя определяют скорость и возможные размеры моделей, доступных для запуска.
Валидация инструмента Autoscribe
Производительность Autoscribe была оценена с использованием двух корпусов разговоров. Эти корпуса были выбраны потому, что они контрастируют друг с другом по ряду параметров (см. Таблицу 2). Более подробная информация о каждом корпусе приведена ниже.
Таблица 2: Характеристики корпусов разговоров
| Характеристика | Корпус #1 | Корпус #2 |
|---|---|---|
| Количество разговоров | 28 | 30 |
| Возраст участников | 46–84 года | 9–14 лет |
| Тип речи | обычная речь | обычная речь |
| Диалект | General American English | Southern British English |
| Тип разговора | основанные на задаче (Diapix Task), построение отношений (Relationship Closeness Induction Task) | основанные на задаче (Diapix Task) |
| Метод записи | Shure SM35, Zoom H4N; одновременная запись в одном помещении | Beyerdynamic DT297, EMU 0404 USB; отдельные комнаты, гарнитуры |
| Продолжительность (мин) | 10 | 4–11 (M = 8.45, SD = 1.88) |
Корпус #1
Наш первый корпус включал 28 разговоров, собранных исследователями из Университета штата Юта1. Этот корпус включает как разговоры, основанные на задаче, так и разговоры по построению отношений между обычно общающимися взрослыми собеседниками в возрасте от 46 до 84 лет. Все говорящие были носителями General American English. Разговоры, основанные на задаче, были вызваны с помощью Diapix Task (Baker & Hazan, 2011) — совместной игры «найди отличия», в которой пары участников работают вместе, чтобы определить 12 отличий между наборами изображений. Разговоры по построению отношений были вызваны с помощью адаптированной версии Relationship Closeness Induction Task (Sedikides et al., 1999). В этой задаче участникам дается список вопросов, которые они должны обсудить со своим собеседником. Все разговоры для этого корпуса были записаны с использованием гарнитурных конденсаторных микрофонов Shure SM35 и рекордеров Zoom H4N. Разговоры проводились в различных тихих местах, включая исследовательские лаборатории, дома участников, общественные библиотеки или общественные центры. Собеседники общались, сидя лицом к лицу на расстоянии примерно двух метров друг от друга. Все разговоры длились 10 минут.
Корпус #2
Наш второй корпус включал 30 случайно выбранных разговоров из аудиозаписей, собранных и предоставленных исследовательскому сообществу Hazan et al. (2016; см. также Bradlow n.d.) в Университетском колледже Лондона (UCL). Все собеседники были обычно общающимися детьми и подростками в возрасте от 9 до 14 лет, и все были носителями Southern British English. В этом корпусе разговоры, основанные на задаче, были вызваны с помощью Diapix Task. Во время разговоров собеседники сидели в разных комнатах и общались через гарнитуры Beyerdynamic DT297. Разговоры записывались с помощью аудиоинтерфейса EMU 0404 USB (EMU; Дублин, Ирландия) и программного обеспечения Adobe Audition. Длительность разговоров для 30 бесед варьировалась от 4 до 11 минут (M = 8,45, SD = 1,88).
Процедура валидации
Для создания TextGrids для валидации использовалось большинство настроек по умолчанию Autoscribe (см. Таблицу 1). Однако был принят ряд модификаций:
- Для первого корпуса использовались различные пороговые значения, от –40 дБ (где каналы имели мало или совсем не пересекались в шуме) до –25 дБ (присутствовало некоторое пересечение, например, говорящий на канале 1 был четко слышен на канале 2). Второй корпус не имел пересечения между каналами, поэтому для всех записей использовалось значение –45 дБ.
- Использовалось шумоподавление для уменьшения влияния шумов (например, фонового шума из других каналов, внешних шумов в среде) на транскрипцию.
- Мы выбрали модель Whisper «small», которая является несколько большей моделью, чем «base» по умолчанию.
- Мы также удалили пунктуацию, заменили все дефисы пробелами и удалили все частичные слова из транскрипта.
Для запуска в среде программирования R использовался следующий общий синтаксис:
auto_textgrid(
file,
noise_reduction = TRUE,
threshold = -30,
model_type = "small",
remove_punct = TRUE,
hyphen = "space",
remove_partial = TRUE
)
Анализ данных
Эффективность
После создания TextGrids обученные ассистенты-исследователи вручную проверили каждую из них, исправляя неправильно транскрибированные слова и корректируя неточные границы TextGrid. В ходе этого процесса ассистенты-исследователи записывали время (в минутах), необходимое для проверки и исправления каждой TextGrid. Ассистенты-исследователи также аннотировали (то есть создавали границы между сегментами речи и не-речи) и транскрибировали 28 TextGrids из первого корпуса и 30 TextGrids2 из второго корпуса полностью вручную и записывали время, необходимое для завершения этого процесса. Эффективность Autoscribe затем определялась путем расчета процента сэкономленного времени при использовании Autoscribe по сравнению с ручным созданием TextGrid.
Точность
Для определения точности автоматизированного инструмента мы сравнили TextGrids, созданные Autoscribe (то есть исходные, непроверенные TextGrids), с теми, которые были проверены и исправлены ассистентами-исследователями. Затем мы оценили как точность транскрипции, так и точность размещения границ. Точность транскрипции определялась тремя методами: анализ частоты ошибок в словах (Word Error Rate, WER), процент правильных слов в непроверенных транскриптах с использованием Autoscore (Borrie et al., 2019) и сходство с использованием косинусного расстояния. WER рассчитывался как сумма замен, удалений и вставок, деленная на общее количество слов. Для сходства мы использовали метрику, известную как косинусное расстояние между профилями q-грамм (Pikies & Ali, 2019; van der Loo, 2014), для количественной оценки различий между исправленными и непроверенными TextGrids. Эта метрика варьируется от 0 (идеальное совпадение) до 1 (полностью отличается). Затем мы сообщаем о наиболее распространенных словах, которые отличались от непроверенных к исправленным TextGrids. Во всех анализах слова, транскрибированные на неправильный слой собеседника (например, из-за утечки микрофона), считались ошибочными. Точность выравнивания границ высказываний определялась путем расчета доли границ в непроверенных и исправленных TextGrids, которые находились в пределах 0,10, 0,20 и 0,50 секунды друг от друга.
Воспроизводимость
Для определения воспроизводимости TextGrids с использованием этого инструмента мы повторно запустили подвыборку из десяти транскриптов. Затем мы проанализировали процент транскрипции и границ, которые идентичны между исходными и новыми TextGrids.
Статистический анализ проводился в R версии 4.5.1 с использованием пакетов tidyverse (Wickham et al., 2019), stringdist (van der Loo, 2014), readTextGrid (Mahr, 2024), data.table (Barrett et al., 2024), gtsummary (Sjoberg et al., 2021), wersim (Proksch et al., 2019), quanteda (Benoit et al., 2018) и tidytext (Silge & Robinson, 2016). Код, выходные данные анализа и примеры заполненных TextGrid, файлов .txt и .csv доступны по адресу https://osf.io/sqh52.
Результаты
Эффективность
Для первого корпуса разговоров ручное создание TextGrid занимало в среднем 133 минуты на TextGrid (SD = 19 минут, диапазон = 102–205 минут). Напротив, исправление автоматизированных TextGrids занимало в среднем 38 минут на TextGrid (SD = 10 минут, диапазон = 30–78 минут). Для второго корпуса разговоров ручное создание TextGrid занимало в среднем 156 минут на TextGrid (SD = 67 минут, диапазон = 58–401 минут). Напротив, исправление автоматизированных TextGrids занимало в среднем 45 минут на TextGrid (SD = 15 минут, диапазон = 24–89 минут). Таким образом, для обоих корпусов использование автоматизированного инструмента сократило время, необходимое для создания TextGrid, в среднем на 71%.
Точность
Точность транскрипции
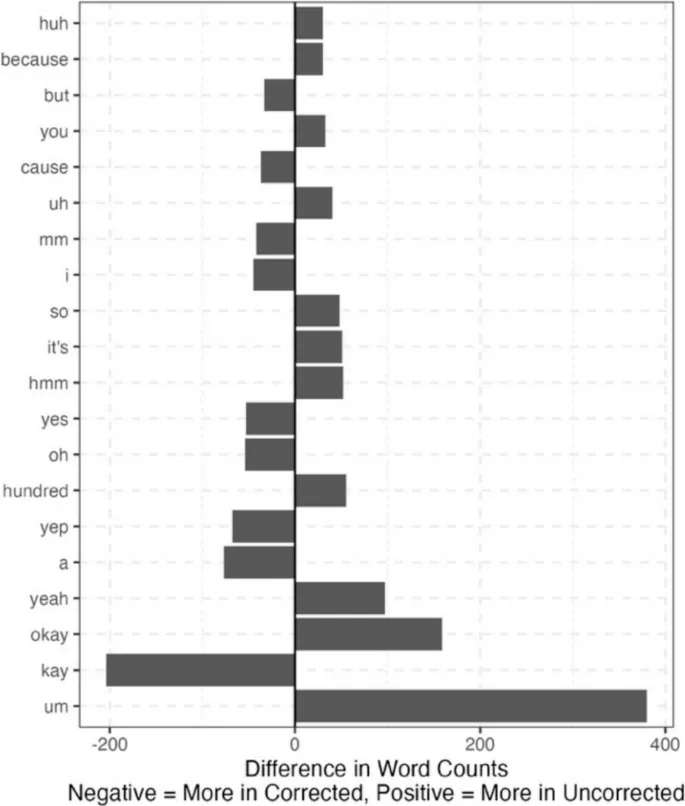
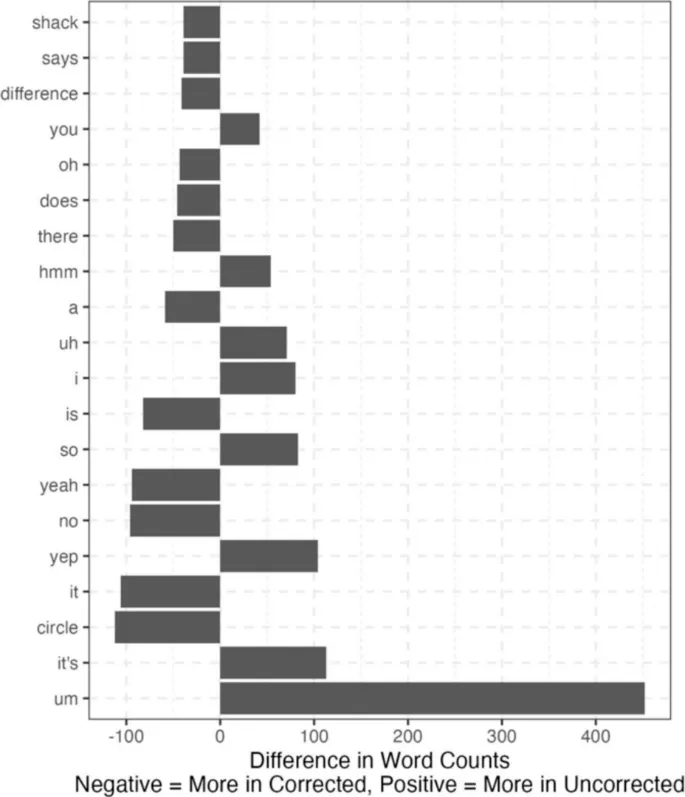
Средний WER на разговор составил 0,16 (SD = 0,11) для первого корпуса и 0,18 (SD = 0,10) для второго. В первом корпусе 60% ошибок составили замены, 6% — вставки и 34% — удаления. Во втором корпусе 74% ошибок составили замены, 8% — вставки и 18% — удаления. Средний процент правильных слов на разговор составил 92% (SD = 4%) для первого корпуса и 89% (SD = 5%) для второго корпуса. Косинусное расстояние составило в среднем 0,0004 (SD = 0,0006) для первого корпуса и в среднем 0,0008 (SD = 0,0009) для второго корпуса. Оба этих значения близки к 0 с очень небольшой вариативностью, что свидетельствует о близком соответствии между непроверенными и исправленными транскриптами. Наиболее распространенные различия в словах для первого корпуса показаны на рис. 3. Это подчеркивает текущее чрезмерное использование инструмента слова «um» и то, как часто он пропускает «kay». Эти два слова составляют 584 из общего количества 4325 различий по частоте в этом корпусе. Наиболее распространенные различия в словах показаны на рис. 4. Как и прежде, это показывает текущее чрезмерное использование инструмента слова «um», а также то, что он использует «it's» вместо «it is».
Точность размещения границ
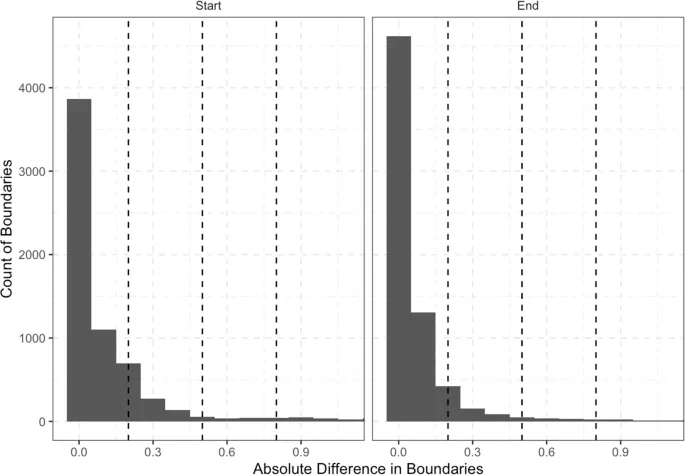
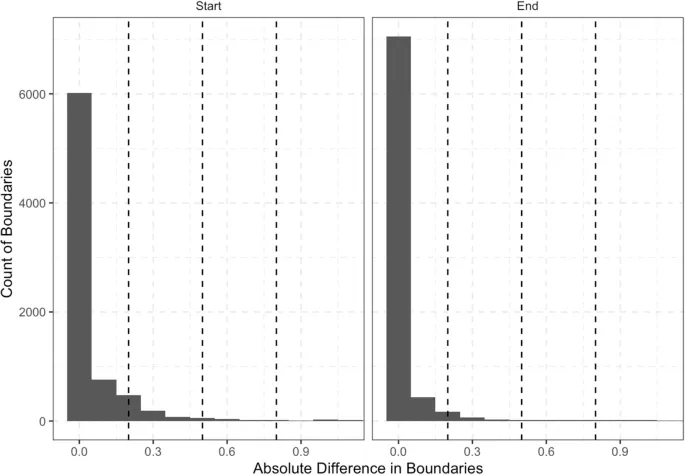
Для первого корпуса 86% границ были идентифицированы правильно (то есть 14% границ были лишними и требовали удаления). Из правильно идентифицированных границ медианные значения 96% начальных границ (межквартильный диапазон = 93%–98%) и 89% конечных границ (межквартильный диапазон = 85%–94%) находились в пределах 0,50 секунды от исправленной границы (см. рис. 5). Это включало 91% начальных границ и 79% конечных границ, которые находились в пределах 0,20 секунды от исправленной границы, и 83% начальных границ и 69% конечных границ, которые находились в пределах 0,10 секунды от исправленной границы.
Для второго корпуса 99% границ были идентифицированы правильно (то есть 1% границ были лишними и требовали удаления). Из правильно идентифицированных границ медианные значения 98% начальных границ (межквартильный диапазон = 96%–99%) и 96% конечных границ (межквартильный диапазон = 93%–98%) находились в пределах 0,50 секунды от исправленной границы в непроверенных и исправленных TextGrids (см. рис. 6). Это включало 96% начальных границ и 90% конечных границ, которые находились в пределах 0,20 секунды от исправленной границы, и 93% начальных границ и 83% конечных границ, которые находились в пределах 0,10 секунды от исправленной границы.
Воспроизводимость
Тест-ретестовая надежность показала, что границы были идентичны в 100% случаев. Транскрипты были идентичны на 91% от одного запуска к другому, при этом большинство различий составляли вставки/удаления. Это ожидаемое поведение связано с дизайном базовой модели Whisper и может быть вызвано использованием различных префиксов и суффиксов, различными написаниями слов и другими причинами.
Обсуждение
Эффективность
С самого начала этого проекта мы знали, что на данном этапе достижение точности на уровне, сопоставимом с человеческим, нереалистично, и что TextGrids потребуют проверки и ручной коррекции после их первоначального создания. Соответственно, нашей конечной целью было создание инструмента, процесс проверки которого был бы значительно быстрее, чем ручное создание TextGrid. Достижение этой цели отражено в том факте, что время активной работы, необходимое для создания TextGrid, сократилось более чем на 70% для обоих корпусов при использовании автоматизированного инструмента. Чтобы понять это, скажем, что время, сэкономленное на создании TextGrid для этих 58 разговоров, составило почти 100 человеко-часов. Здесь мы отмечаем, что, хотя наш протокол ручной коррекции был обширным, и ассистенты-исследователи уделяли внимание точным корректировкам точности транскрипции и выравнивания границ, степень необходимой ручной коррекции будет зависеть от причин использования инструмента и типа проводимого анализа. Например, хотя некоторые типы анализа требуют чрезвычайно точного выравнивания границ, другие — нет. Следовательно, в некоторых случаях время, необходимое для исправления TextGrids, будет еще быстрее, чем сообщается здесь.
Точность
Точность транскрипции была высокой. В нашем первом корпусе, включавшем взрослых собеседников, общающихся на General American English, слова были транскрибированы с точностью 92% (в широком смысле — процент правильных слов). Во втором корпусе, включавшем детей и подростков, общающихся на Southern British English, точность транскрипции составила 89%. Следует отметить, что Autoscribe способен с такой высокой степенью точности улавливать речь детей/подростков из этого корпуса. Кроме того, благодаря тонкой настройке, нам удалось достичь такого уровня точности транскрипции в разговорной речи, которая включает частые повторения, слова-паразиты, обратную связь и прерывания.
Точность размещения границ высказываний также была высокой. Во втором корпусе, где разговоры записывались в высококачественной среде записи, границы были идентифицированы правильно в 99% случаев, а примерно в 97% случаев были точно размещены (в пределах 0,5 с). Точность границ для нашего первого корпуса была немного ниже (то есть правильно идентифицированы в 86% случаев и примерно в 93% случаев точно размещены), вероятно, из-за того, что этот корпус включал разговоры, записанные в менее идеальных условиях. Таким образом, хотя использовались высококачественные микрофоны и записывающее оборудование, фоновый шум снизил точность выравнивания границ. Кроме того, поскольку участники находились в одной комнате, перекрестное загрязнение микрофонов между собеседниками привело к некоторым из этих неточностей. Тем не менее, несмотря на препятствия, связанные с более экологически валидными средами записи, точность оставалась высокой, что указывает на то, что этот инструмент может использоваться в различных условиях.
Применение
Autoscribe доступен в двух различных форматах. Самый простой вариант — настольное приложение (в настоящее время доступно для macOS с Apple Silicon) по адресу http://www.humaninteractionlab.com/tools. На этом веб-сайте представлено руководство, содержащее пошаговые инструкции по загрузке и использованию инструмента. Кроме того, это руководство содержит более подробную информацию о параметрах для исследователей, предложения по улучшению точности инструмента и руководства по устранению неполадок. Инструмент может быть установлен стандартным способом на macOS. После установки первое использование инструмента потребует дополнительной настройки, которая происходит автоматически (то есть создается отдельный экземпляр R и среда Python, чтобы держать инструмент отдельно от программы R пользователя и любых сред Python, уже имеющихся на его машине). Эта настройка займет несколько минут, но после первого использования инструмент будет запускаться быстро. Затем приложение сможет принимать один файл .wav или несколько файлов .wav и обрабатывать их. По окончании обработки в выбранной пользователем папке будет доступна TextGrid (для отдельного файла .wav) или zip-архив (для нескольких файлов .wav).
Для людей, имеющих опыт работы с R, этот инструмент также можно загрузить в виде пакета R с GitHub по адресу https://github.com/HumanInteractionLab/wav2textgrid. Основная функция — auto_textgrid(), с основными аргументами, показанными в примере кода в разделе «Методы». Существует несколько других аргументов, которые можно просмотреть в меню справки в R. При использовании версии R пакета этого инструмента существует ряд зависимостей пакетов, включая reticulate (для взаимодействия между R и Python), tidyverse, furniture, readtextgrid, English, некоторые инструменты форматирования (например, cli, scales) и несколько инструментов обработки аудио (например, seewave, speakr, tuner) (Ushey et al., 2025; Wickham et al., 2019; Barrett & Brignone, 2017; Mahr, 2024; Fox et al., 2021; Csárdi, 2025; Wickham et al., 2025; Sueur et al., 2008; Coretta, 2024; Ligges et al., 2023; Hester et al., 2025; Hester & Bryan, 2024). Для запуска кода в виде пакета R рекомендуется настроить среду Python с помощью reticulate для загрузки и запуска модели Whisper (см. https://github.com/HumanInteractionLab/wav2textgrid/blob/master/README.md). Все зависимости будут загружены автоматически (либо как часть установки пакета, либо во время выполнения). Примечание: временные файлы появятся в папке, где находится файл .wav, во время создания TextGrid. Они будут удалены по окончании расчета, но являются необходимой частью процесса. Готовый продукт — это файл с тем же именем, что и файл .wav, с добавлением «_output.TextGrid», и он может быть открыт в Praat, а также в любых текстовых редакторах.
Независимо от формата, инструмент будет предоставлять уведомления в процессе обработки, чтобы информировать пользователей о ходе работы. Независимо от формата, основная вычислительная нагрузка связана с использованием моделей Whisper. Важно убедиться, что компьютер, используемый для запуска Autoscribe, соответствует рекомендациям. Для модели «small» (используемой во всем отчете) достаточно 4 ГБ ОЗУ и 4–8 ядер ЦП. Для модели «base» достаточно 2–3 ГБ ОЗУ и 4 ядер ЦП. Для более крупных моделей (medium, large) может потребоваться более 8 ГБ ОЗУ и более восьми ядер ЦП.
Полезность Praat TextGrids означает, что данные, сгенерированные Autoscribe, могут использоваться для ответа на множество исследовательских вопросов. В Praat дополнительные функции также могут повысить полезность TextGrids, созданных Autoscribe. Например, в сгенерированную TextGrid можно добавить дополнительные слои для разметки конкретных фонетических, морфосинтаксических или прагматических элементов разговора для дальнейшего анализа. Даже для исследователей, незнакомых с Praat или чьи анализы основаны на других типах программного обеспечения, TextGrids, предоставленные Autoscribe, могут служить полезным целям. Информация, сгенерированная Autoscribe, такая как имя слоя, содержание транскрипта и временные метки каждого высказывания, может быть преобразована в несколько различных типов файлов, включая .csv или .txt, которые затем могут использоваться для последующего анализа. Данные из Autoscribe также могут быть интегрированы с другим программным обеспечением и инструментами, такими как Python, R (R Development Core Team, 2024), ELAN (ELAN, 2024) и MATLAB (The MathWorks Inc., 2024) для дальнейшей обработки. В наших исследованиях Praat TextGrids (аналогичные тем, что получены с помощью Autoscore) использовались для изучения выравнивания разговоров как в акустической (например, Wynn et al., 2022, 2023), так и в лингвистической (Chieng et al., 2024) модальностях; для исследования акустических характеристик речи у разных типов говорящих (например, Borrie et al., 2022; Wynn et al., 2022) и в различных контекстах (Wynn et al., 2024; Borrie et al., 2020); а также для обмена данными из корпусов разговоров с исследовательским сообществом (Eijk et al., 2022). TextGrids не ограничиваются этими целями. Другие исследователи могут найти Autoscribe полезным для генерации TextGrids для изучения динамики смены реплик, использования обратной связи, взаимодействия между различными модальностями коммуникации, паттернов переключения кода, структуры диалога и лингвистических паттернов, возникающих в разговоре.
Ограничения
Хотя Autoscribe предлагает многообещающий путь для развития исследований разговоров, существуют некоторые контексты разговоров, для которых эффективность этого инструмента в настоящее время неизвестна. Мы отмечаем, что корпуса, использованные для валидации инструмента, представляли разговоры, включавшие собеседников из широкого возрастного диапазона и двух разных диалектов. Однако все говорящие были не моложе девяти лет. Поскольку инструменты автоматического распознавания речи обычно обучаются на взрослых, производительность инструмента на разговорах с участием младших детей (чьи лексические, синтаксические и артикуляционные паттерны отличаются от взрослых) может быть менее успешной.
Кроме того, все участники в наших корпусах были обычно общающимися людьми. Неформальное исследование использования инструмента в разговорах у говорящих с легкой и умеренной дизартрией показало хорошие результаты. Однако производительность инструмента на людях с более тяжелыми и/или различными типами речевых расстройств неизвестна. Все валидированные разговоры также проводились на английском языке. Теоретически этот инструмент может использоваться для разговоров с участием других языков. Действительно, в неформальном исследовании использования этого инструмента в (относительно низкокачественных) аудиозаписях разговоров между носителями голландского языка (с легкой дизартрией) авторы обнаружили, что инструмент работал эффективно (хотя инструмент был несколько менее точным, чем с английскими разговорами, иногда транскрибируя речь на других языках). Однако точность транскриптов, вероятно, будет зависеть от используемого языка и диалекта. По мере появления новых моделей мы намерены интегрировать в этот инструмент более производительные открытые модели.
Помимо характеристик говорящего, на этот инструмент также может влиять качество звука. Важно отметить, что этот инструмент может использоваться только в двусторонних разговорах, когда отдельные собеседники записываются на отдельные каналы. Кроме того, хотя этот инструмент был валидирован на разговорах, проходивших в различных условиях, записывающее оборудование, использованное для всех разговоров, было высокого качества, и были реализованы стратегии для максимально возможной оптимизации качества звука. Как упоминалось выше, неформальное исследование производительности этого инструмента показало относительно высокую точность при низкокачественных записях. Однако степень влияния качества звука на точность производительности неизвестна.
Наконец, мы отмечаем, что транскрипты, произведенные этим инструментом, используют конкретную модель транскрипции (то есть модель OpenAI Whisper) и, как таковая, полагаются на точность и обучающие данные этой модели. Исследования продемонстрировали адекватность этих инструментов для исследований в области социальных наук (Naffah et al., 2025), и, учитывая текущий темп развития искусственного интеллекта и транскрипции, это, вероятно, будет только улучшаться со временем. Инструмент был разработан таким образом, чтобы иметь возможность использовать обновленные модели от OpenAI (или другие доступные модели) по мере их появления, и в будущих итерациях может включать другие доступные модели (например, Wav2Vec). Особое внимание будет уделено тому, смогут ли эти модели быть разработаны для лучшего включения речевых расстройств или других инклюзивных контекстов, что обеспечит дополнительную возможность для точной транскрипции.
Заключение
Таким образом, целью данной статьи было представление Autoscribe, открытого инструмента для создания Praat TextGrids из аудиозаписей разговоров. Мы валидировали инструмент с точки зрения точности, эффективности и надежности на двух корпусах разговоров, которые значительно различались, что позволило исследовать применимость инструмента к разговорам, собранным между различными типами собеседников и в различных условиях записи. На обоих наборах данных мы продемонстрировали высокие уровни точности, а также значительное преимущество с точки зрения эффективности по сравнению с традиционными TextGrids, созданными вручную обученными ассистентами-исследователями. Таким образом, Autoscribe предлагает удобный и универсальный инструмент для транскрипции разговоров, который может использоваться для различных последующих анализов.