Интересное сегодня
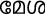
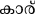
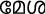
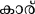
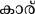
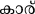
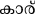
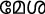

Роль фонетики в визуальной обработке слов у билингвов: исследование с использованием ERP и маскированного прайминг-предъявления
В данном исследовании мы экспериментально манипулировали фонетику пар "прайм-цель" в условиях кросс-скриптового (разные системы письма) маскированного прайминг-предъявления с применением метода событийных связанных потенциалов (ERP), чтобы исследовать роль фонетики в визуальной обработке слов. Письменные символы определенных билингвальных пар редко демонстрируют визуальную/орфографическую схожесть, однако имеют одинаковое фонетическое представление. В то время как модель билингвальной интерактивной активации (BIA) основывается на орфографической схожести между языками в билингвальной паре, ее пересмотренная версия (модель BIA+) дополнительно опирается на фонетическую (и семантическую) схожесть между словами в таких парах. Таким образом, существует необходимость исследовать роль фонетической (и семантической) схожести между словами билингвальной пары, особенно при отсутствии орфографической схожести. Заимствованные слова из одного языка в другой предоставляют подходящий путь для изучения этого вопроса. Участники данного исследования, являющиеся кросс-орфографическими (или кросс-скриптовыми) билингвами, выполняли семантическую оценку визуально предъявляемых слов в парадигме маскированного прайминг-предъявления на каждом из своих языков, в то время как мы одновременно регистрировали события, связанные с потенциалами (ERP). Праймы были либо переводами (разная фонетика и орфография: P–O–; фонетически несоответствующие), либо транслитерациями (одинаковая фонетика и разная орфография: P+O–; фонетически соответствующие) целевого слова. В целом, результаты не показали различий между двумя условиями праймов. Мы обсуждаем наши выводы в свете моделей BIA и BIA+ билингвальной визуальной обработки слов и рассматриваем релевантность первой модели для билингвальных пар с орфографически различными языками.
Введение
Большой объем исследований предполагает, что билингвы активируют свой нецелевой язык при обработке целевого языка 1,2,3,4,5. Несколько исследований подчеркивают роль фонетики в билингвальной обработке слов 1. Однако некоторые работы акцентируют внимание на важности письменности в билингвальной визуальной обработке слов, особенно в парах с орфографически различными языками 6,7. В текущем исследовании мы экспериментально манипулировали фонетику пар "прайм-цель" в парадигме билингвального маскированного прайминг-предъявления (в сочетании с событиями, связанными с потенциалами), где два языка не имеют никакой визуальной или орфографической схожести. Мы обсуждаем наши выводы в свете моделей билингвальной интерактивной активации (BIA 8,9 и BIA+ 10) (см. ниже), которые предполагают начало визуальной обработки слов с буквенных признаков.
Модели билингвальной интерактивной активации (BIA и BIA+)
Модели BIA 8,9 и ее пересмотренная версия BIA+ 10 являются двумя влиятельными моделями, объясняющими визуальную обработку слов у билингвов. Эти модели предлагают интегрированный билингвальный лексикон, в котором слова на одном языке обрабатываются неселективно 10. Модели BIA следуют восходящей схеме обработки, начиная с буквенных признаков, затем к буквам с их уникальными позициями в словах и, таким образом, к конкретным словам. Активированные слова на уровне слов передают активацию к языковым узлам, которые, в свою очередь, служат языковыми метками. Эти метки подавляют активированные слова в нецелевом языке на предыдущем (словесном) уровне через ингибиторные связи. Однако языковые узлы не имеют механизма для облегчения доступа к языково-специфическим лексическим единицам на ранних стадиях визуальной обработки слов 11.
Модели BIA в первую очередь полагаются на орфографическую схожесть между языками билингвальных носителей. В пересмотренной версии (BIA+) модели Dijkstra и van Heuven 10 внедрили фонетическую (звуковой уровень) и семантическую (значение) схожесть и предположили, что в дополнение к орфографической схожести, фонетическая и семантическая схожесть между языками также вносят вклад в билингвальную визуальную обработку слов. Фонетическая и семантическая схожесть между словами в основном опосредуется орфографическим перекрытием. Несколько исследований 12,13,14 показали такое влияние на различных уровнях (орфографическое перекрытие, фонетическое перекрытие и семантическое перекрытие), тем самым подтверждая модели BIA и BIA+.
Проблема кросс-скриптовой обработки
Хотя модели BIA и BIA+ предполагают орфографически-ориентированную визуальную обработку слов у билингвов, где языковые узлы активируются значительно позже в процессе, как происходит визуальная обработка слов в случае кросс-скриптовых билингвальных контекстов, особенно когда два письма не имеют никакого визуального сходства?
Недавнее исследование Peleg et al. 15 сообщило о фонетической медиации у кросс-скриптовых (арабский-иврит) билингвов. Носители арабского языка, относительно владеющие ивритом, смогли отвергнуть слова на разговорном арабском языке (которые не имеют письменности; следовательно, написаны на иврите и служили не-словами на этом языке) в задаче лексического решения на иврите (LDT) по сравнению с не-словами на обоих языках. Авторы пришли к выводу, что такое раннее отвержение слов разговорного арабского языка в LDT на иврите было связано с подлексической фонетической медиацией от иврита к разговорному арабскому. В свете моделей BIA остается неясным, как ивритские буквы и их позиции активировали слова разговорного арабского языка, особенно когда последние не имели письменности. Кроме того, следует отметить, что участники в исследовании Peleg et al. 15 имели достаточно времени, чтобы вывести всю фонетику слова (и, возможно, семантику) не-слов (т. е. слов разговорного арабского языка) из ивритских букв. Методологически, чтобы облегчить вывод всей фонетики слова или любой подобной стратегической обработки, рекомендуется парадигма маскированного прайминг-предъявления 16.
Парадигма маскированного прайминг-предъявления и ERP
В парадигме маскированного прайминг-предъявления праймы предъявляются подсознательно, часто обрамленные последовательностью '#' или случайной строкой букв 16, чтобы ограничить их сознательную обработку 17. Даже такие маскированные и кратковременно предъявляемые праймы влияют на цели в визуальной обработке слов. В межъязыковых экспериментах с маскированным прайминг-предъявлением праймы, манипулированные на различных уровнях (например, орфографическом 12, фонетическом 18 и переводах 19), все показали влияние на обработку цели. Хотя большинство этих исследований проводилось у билингвов с одинаковой письменностью, даже исследования у кросс-скриптовых билингвов показали такое влияние на визуальную обработку слов 20. Однако присущий парадигме маскированного прайминг-предъявления недостаток заключается в том, что поведенческие показатели исходов (например, время реакции и точность) получаются только в конце каждого испытания и, таким образом, не отражают истинно только экспериментально контролируемые (например, орфографические или фонетические) процессы. Другими словами, эти показатели исходов также будут включать определенные зависящие от задачи затраты на обработку, такие как процесс принятия решений и время ручного ответа 12,21. Чтобы преодолеть эти присущие ограничения, исследователи использовали дополнительные методы, позволяющие отслеживать текущие процессы в режиме реального времени. Одним из таких методов являются события, связанные с потенциалами (ERP).
ERP использовались в исследованиях визуальной обработки слов для мониторинга нейронной динамики во время обработки визуально предъявляемых целей. Этот метод позволяет отслеживать активность мозга в миллисекундном масштабе. Три компонента ERP, обычно изучаемые в визуальной обработке слов, — это N/P150, N250 и N400. Ранний ответ ERP P150 (или N150, в зависимости от расположения электрода) понимается как указание на низкоуровневую визуальную обработку стимулов. В поддержку этого мнения N/P150 модулируется характером стимулов (орфографические против неорфографических 22), размером и типом шрифта 23, а также положением буквы 24. Когнитивный процесс, отраженный компонентом N/P150, — это отображение визуальных признаков на долексические орфографические представления 25. Эффект N250, с другой стороны, приписывается различным долексическим процессам, таким как подлексическая обработка напечатанных буквенных строк 26, отображение долексических представлений формы на представления целых слов и отображение орфографии на фонетику 27. Этот эффект также сообщался как результат орфографического несоответствия между праймами и целями 28. Однако влияние фонетической схожести между словами, особенно в кросс-скриптовой билингвальной паре, остается неизвестным. N400, поздний компонент ERP, рассматривается как показатель семантической обработки во многих исследованиях ERP с маскированным прайминг-предъявлением 29,30,31.
Предыдущие исследования кросс-скриптовой обработки
В кросс-скриптовом исследовании, сочетавшем ERP с подсознательным прайминг-предъявлением переводов не-когнатов, Hoshino и коллеги 29 сообщили об эффекте N250 от японских праймов (L1) к английским целям (L2), но не в обратном порядке. Хотя такого эффекта не ожидалось в обоих направлениях из-за несоответствия форм слов (т. е. японский и английский), авторы приписали наблюдаемый эффект в направлении L1–L2 обратной связи от семантических представлений, активированных более сильными L1 праймами, к более слабым L2 целям. Таким образом, Hoshino et al. утверждали, что эффект N250 возникает из семантической обратной связи в контексте кросс-скриптового прайминг-предъявления переводов не-когнатов.
Chauncey et al. 31 изучали билингвов, говорящих на французском (L1) и английском (L2), в парадигме маскированного прайминг-предъявления, где пары "прайм-цель" состояли из несвязанных слов, принадлежащих либо одному, либо разным языкам. В ERP, в окнах времени N250 (175–300 мс) и N400 (375–550 мс), они обнаружили эффект целевого языка (L1 цели имели более высокие N250 и N400). Когда цели были на L2, а праймы на L1, N250 был больше, а N400 слабее. Последнее наблюдение было интерпретировано как затраты на переключение кода. В свете модели BIA авторы утверждали, что прайм активирует соответствующий языковой узел, и эта активация посылает ингибирование лексическим представлениям на другом языке. Поскольку L1 праймы обрабатываются быстрее, чем L2 праймы, они оказывают более раннее влияние на обработку цели, тем самым генерируя более сильные эффекты переключения кода для L2 целей в временном окне N250.
Хотя рассмотренные выше исследования показывают, что фонетика нецелевого языка активна при обработке слов на целевом языке 15 или что фонетическая активация слабее, когда праймы на L2 29, несколько других исследований предполагают влиятельную роль орфографии в кросс-скриптовых билингвальных парах. Например, Gollan et al. 6 предположили, что различия в письме могут давать мощные сигналы для поиска в соответствующем лексиконе билингвов. То есть, прайм на иврите будет давать более сильные сигналы для последующих целей на иврите, чем на английском. ERP-свидетельства в поддержку этого утверждения были недавно представлены у испано-английских билингвов 32. Hoversten и коллеги 32 использовали парадигму "oddball" (необычное предъявление), в которой участникам требовалось нажать одну кнопку для редких целей на L1 и другую кнопку для похожих целей на их L2. Пока участники выполняли эту задачу, регистрировались ERP, связанные с не-словами (не-целями), которые, в свою очередь, выглядели как цели. Они предположили, что ERP-индексы редких стимулов в парадигме "oddball" (например, компоненты N2 и P3) будут присутствовать только на похожих на цели не-словах, если их орфографические сигналы обрабатываются в задаче лексического решения. Как поведенческие, так и ERP-данные из этого исследования предоставили доказательства раннего (т. е. долексического) использования орфографических сигналов. Похожие на цели не-слова (т. е. орфографически схожие с целями) получали больше ложных срабатываний по сравнению с теми, которые не демонстрировали такой схожести с целями. Как и предсказывалось, они наблюдали компоненты N2 и P3, свидетельствующие о ранней обработке орфографических сигналов. Наконец, очень недавнее исследование 7, сравнивавшее кросс-скриптовых (японско-английских) и односкриптовых (испано-английских) билингвов в парадигме "picture-word interference" (интерференция "картинка-слово"), предоставило дополнительные доказательства перцептивных различий между орфографиями как языкового сигнала, который может способствовать более быстрой обработке слов на целевом языке.
Текущее исследование
Как было сказано ранее, согласно моделям BIA, визуальная обработка слов начинается с ранней идентификации буквенных признаков 8,9,10. В свете этих моделей, те кросс-скриптовые исследования, которые предполагали активацию фонетики нецелевого языка при обработке слов на целевом языке, указывают на то, что орфография первого языка активируется целевым языком. Однако другие исследования утверждают, что кросс-скриптовые праймы удобно ограничивают визуальную обработку слов соответствующим (целевым) языком. Главный вопрос согласно моделям BIA здесь заключается в том, как признаки букв целевого языка, которые не имеют никакой визуальной схожести с буквами нецелевого языка, активируют последний. Один из способов изучить этот вопрос — использовать кросс-скриптовые когнатные переводы (например, заимствованные слова: далее транслитерация) и кросс-скриптовые не-когнатные переводы (далее перевод) праймы во время визуальной обработки слов. Транслитерации фонетически схожи, но орфографически различны друг с другом (P+O–). Заимствованные слова из одного языка в другой (которые не имеют уникального перевода в последнем языке) подпадают под эти условия. Такие слова пишутся с использованием орфографии принимающего языка, однако произносятся подобно языку-источнику. Переводы, с другой стороны, не являются ни фонетически, ни орфографически схожими (P–O–). То есть, такие слова имеют уникальную форму слова в каждом языке. Оба типа: транслитерации и переводы, разделяют одинаковую семантику (S+) между языками.
Гипотезы
В текущем исследовании мы администрировали парадигму маскированного прайминг-предъявления в сочетании с ERP группе малаялам-английских билингвов. Малаялам (основной язык, на котором говорят в Керале, южном штате Индии) относится к алфасиллабической (или семисиллабической) орфографии, как и большинство других индийских языков. Согласные графемы в этом языке всегда слоговые, в то время как канонические гласные графемы являются фонемическими в произношении. Кроме того, визуально-пространственная организация графем в этом языке сложна по сравнению с английским (алфавитной орфографией) 33. Что более важно, из-за исторических причин малаялам, как и многие языки Индии, заимствовал несколько слов из английского языка, что дает нам возможность сравнить транслитерации (т. е. семантически и фонетически схожие, но орфографически различные) и переводы слов в качестве праймов для изучения релевантности орфографии в кросс-орфографически различных языковых парах.
В этом исследовании мы предполагаем, что если фонетика влияла на визуальную обработку слов в кросс-скриптовых билингвальных контекстах, то испытания с транслитерацией (P+O–, например, CAR {ka:r}) дадут более быструю реакцию (RT) по сравнению с испытаниями с переводом (P–O–, например, TABLE– {me:ʃa}). Это, в свою очередь, подтвердит модель BIA+ 10. С другой стороны, отсутствие различий в RT между двумя условиями подтвердит модель BIA 8,9 и вызовет обеспокоенность по поводу влияния фонетики (и, следовательно, модели BIA+ 10) в кросс-скриптовых билингвальных контекстах визуальной обработки слов. Кроме того, такое отсутствие различий может усилить аргументы о роли орфографии в кросс-скриптовых билингвальных контекстах визуальной обработки слов.
Что касается ERP, поскольку праймы и цели всегда были на разных языках, сравнение между испытаниями с переводом и транслитерацией в раннем временном окне (100–200 мс), где извлекаются визуальные/орфографические признаки, не даст никаких различий (т. е. без эффекта N/P150). Что более важно, если фонетика влияла на отображение орфографии на фонетику в билингвальной визуальной обработке слов, эффект N250 мог бы быть ожидаем (в пределах 200–350 мс) из-за фонетического несоответствия между испытаниями с транслитерацией (P+O–) и испытаниями с переводом (P–O–). Наконец, поскольку и транслитерационные, и переводные испытания разделяют одинаковые семантические концепции, мы не ожидаем различий между испытаниями с переводом и транслитерацией в более позднем временном окне (т. е. без эффекта N400).
Результаты
Поведенческие меры
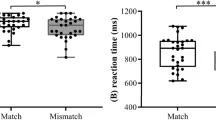
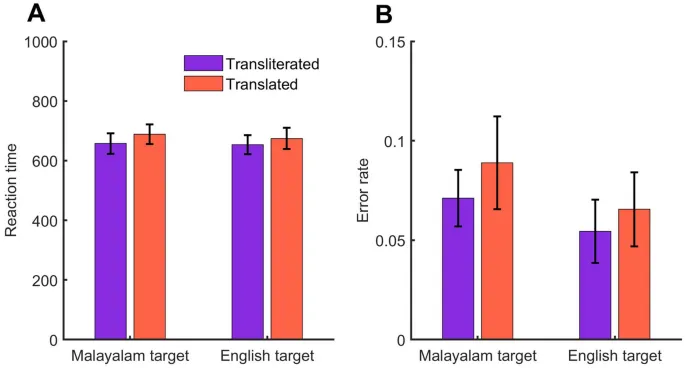
Время реакции и частота ошибок показаны на Рис. 1. Мы провели отдельные ANOVA с повторными измерениями по времени реакции и частоте ошибок. Хотя испытания с транслитерацией дали более быстрое время реакции (средняя разница = 26 мс) по сравнению с испытаниями с переводом, эта разница не была статистически значимой (F(1, 17) = 3.46, p = 0.08, ŋp2 = 0.16). Аналогично, мы не наблюдали значимого основного эффекта целевого языка (F(1, 17) = 0.26, p = 0.61, ŋp2 = 0.01), хотя участники были на 9 мс быстрее при обработке английских целей по сравнению с малаяламскими целями. И взаимодействие между конгруэнтностью прайма и целевым языком не было значимым (F(1, 17) = 0.2, p = 0.66, ŋp2 = 0.01).
Результаты анализа данных об ошибках отличались от результатов RT. Участники совершали больше ошибок в испытаниях с переводом по сравнению с испытаниями с транслитерацией (F(1, 17) = 5.42, p = 0.03, ŋp2 = 0.24). Однако ни основной эффект целевого языка (p = 0.16), ни взаимодействие между конгруэнтностью прайма и целевым языком (p = 0.64) не были статистически значимыми.
ERP меры
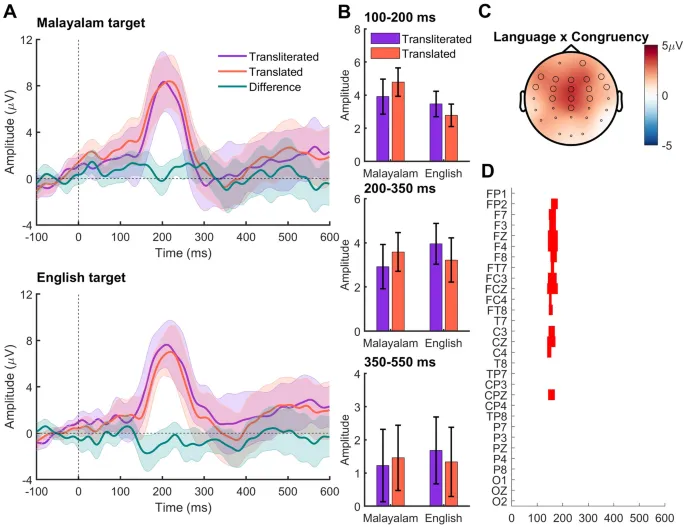
Усредненные ERP для каждого условия и стимула показаны на Рис. 2. Как и ожидалось для визуальных стимулов, ERP показали положительный пик около 200 мс для всех стимулов в центральном положении.
Анализ, основанный на литературе
N/P150 (100–200 мс эпоха)
ANOVA с повторными измерениями 2×2, вычисленная с факторами "Целевой язык" (английский, малаялам) и "Конгруэнтность" (транслитерация, перевод) по амплитуде между 100 и 200 мс, не выявила значимого основного эффекта "Целевого языка" (F(1,17) = 3.80, p = 0.068, ŋp2 = 0.18) или "Конгруэнтности прайма" (F(1,17) = 0.150, p = 0.70, ŋp2 = 0.01). Однако взаимодействие между языком и конгруэнтностью было значимым (F(1,17) = 5.59, p = 0.03, ŋp2 = 0.25). Для дальнейшего понимания взаимодействия были проведены отдельные однофакторные ANOVA для каждого языка с фактором "конгруэнтность". Эти ANOVA выявили основной эффект конгруэнтности для малаяламских целей (F(1,17) = 5.12, p = 0.037, ŋp2 = 0.23), где испытания с переводом дали статистически значимо большую положительную реакцию (M = 4.78, SE = 0.86) по сравнению с испытаниями с транслитерацией (M = 3.90, SE = 1.06). Эффект конгруэнтности для английских целей не был значимым (F(1,17) = 2.57, p = 0.13, ŋp2 = 0.13). Далее, признавая, что переводы имеют две фонетические формы слова (одну на каждом языке) в отличие от транслитераций (которые имеют только одну форму в исходном языке: здесь английский), мы вычислили две отдельные ANOVA для каждого уровня конгруэнтности с языком в качестве фактора. Эти результаты выявили основной эффект языка только в испытаниях с переводом (F(1,17) = 14.02, p = 0.002, ŋp2 = 0.45), где малаяламские переводы снова показали статистически значимо большую положительную амплитуду (M = 4.78, SE = 0.86) по сравнению с их английскими аналогами (M = 2.77, SE = 0.67). Средняя амплитуда ERP в этом временном окне не отличалась между малаяламскими и английскими транслитерациями (F(1,17) = 0.27, p = 0.61, ŋp2 = 0.02). Таким образом, ERP показали независимые эффекты языка и конгруэнтности, в основном из-за малаяламских переводов в эпохе 100–200 мс.
N250 (200–350 мс эпоха)
ANOVA 2×2 с повторными измерениями по амплитуде между 200 и 300 мс не выявила значимых основных эффектов (Целевой язык: F(1,17) = 0.25, p = 0.62, ŋp2 = 0.01; Конгруэнтность: F(1,17) = 0.02, p = 0.92, ŋp2 = 0.001). Однако взаимодействие между целевым языком и конгруэнтностью было значимым (F(1,17) = 4.84, p = 0.04, ŋp2 = 0.22). Но последующая однофакторная ANOVA, проведенная для каждого целевого языка, не показала значимых эффектов для фактора "Конгруэнтность" (Малаялам: F(1,17) = 1.86, p = 0.19, ŋp2 = 0.10; Английский: F(1,17) = 3.23, p = 0.09, ŋp2 = 0.16). Опять же, как и в предыдущей эпохе, мы рассчитали две отдельные однофакторные ANOVA для каждого уровня конгруэнтности с языком в качестве фактора. Однако оба анализа не выявили значимых основных эффектов языка (Транслитерация: F(1,17) = 1.61, p = 0.22, ŋp2 = 0.08; Перевод: F(1,17) = 0.33, p = 0.57, ŋp2 = 0.02). Следовательно, амплитуда ERP между 200 и 350 мс была одинаковой для переводных и транслитерированных стимулов на обоих языках.
N400 (350–550 мс эпоха)
ANOVA с повторными измерениями 2×2 в временном окне N400 (350–550 мс) не выявила никаких значимых основных эффектов (Целевой язык: (F(1,17) = 0.44, p = 0.83, ŋp2 = 0.003; Конгруэнтность: (F(1,17) = 0.12, p = 0.92, ŋp2 = 0.001) или взаимодействий (F(1,17) = 0.23, p = 0.64, ŋp2 = 0.013), что указывает на одинаковую амплитуду ERP между языками и конгруэнтностью праймов в этом временном окне.
Анализ, основанный на данных
Кластерная ANOVA, включающая все 30 электродов и все временные точки от 0 до 600 мс, не выявила никаких значимых основных эффектов. Однако взаимодействие между целевым языком и конгруэнтностью было значимым между 140 и 180 мс (p-значение кластера = 0.041; d Коэна = 0.83). Разница в ERP между переводными и транслитерированными испытаниями была более положительной для малаяламских целей, чем для английских целей, в период с 140 до 180 мс (Рис. 2).
Обсуждение
В настоящем исследовании мы сравнили поведенческие и электрофизиологические данные группы малаялам-английских билингвов, пока они обрабатывали пары "прайм-цель", которые были либо переводами, либо транслитерациями. Участники выполняли семантическую оценку маскированных праймами целевых слов отдельно на каждом языке. Два рассматриваемых языка принадлежали к совершенно разным орфографиям, имеющим минимальную или нулевую визуальную/орфографическую схожесть между ними. Как упоминалось во Введении, в то время как транслитерации разделяют одинаковую фонетику и семантику между языками, но не орфографию, переводы разделяют только семантику, но не фонетику и орфографию. Таким образом, основное различие между этими двумя типами слов заключается в их фонетике, и это позволило нам точно манипулировать фонетикой между праймами и целями.
Поведенческие и ERP результаты
Время реакции целевых слов, предшествующих транслитерированным (т. е. конгруэнтным: P+O–) праймам, было короче (т. е. быстрее) на 26 мс по сравнению с целями, которым предшествовали переводные (т. е. инконгруэнтные: P–O–) праймы. Однако разница не была значимой. Это в основном указывает на то, что фонетическая схожесть в случае транслитерированных праймов не оказала влияния на обработку целевого слова. Этот результат противоречит предыдущим сообщениям о фонетической фасилитации 15,18. Обратите внимание, что в текущем исследовании орфография праймов всегда отличалась от орфографии целей. Кроме того, прайм и цель имели одинаковое семантическое представление (т. е. перевод и транслитерация). В то время как транслитерированные праймы были фонетически конгруэнтны целевому слову, переводные праймы были фонетически инконгруэнтны целевым словам. Следовательно, поведенческие данные текущего исследования показывают, что при отсутствии орфографической схожести фонетическая схожесть между праймами и целями не оказала влияния на обработку целевого слова. То есть, возможный эффект фонетической фасилитации, сообщенный в других местах 34, может быть аннулирован при времени предъявления подсознательного прайма, когда орфография прайма отличается от орфографии цели. Таким образом, результаты данного исследования могут укрепить аргументы о вероятной роли орфографии в билингвальной визуальной обработке слов, по крайней мере, в орфографически различных языках 6.
ERP-данные этого исследования в основном подтвердили поведенческие данные. Единственный наблюдаемый ERP-эффект был между 100 и 200 мс, где (1) конгруэнтность прайма оказала влияние на малаяламские цели, но не на английские цели, и (2) целевой язык оказал влияние на испытания с переводом (P–O–), но не на испытания с транслитерацией (P+O–). Более детальный анализ этих результатов показывает, что оба эффекта возникли из-за статистически более высокой амплитуды ERP малаяламских переводов (4.78 мкВ) по сравнению с малаяламскими транслитерациями (3.9 мкВ) и английскими переводами (2.78 мкВ). Эти эффекты также присутствовали в полностью основанном на данных кластерном пермутационном анализе. Мы не предсказывали эффект в этом временном окне, так как различия между праймом и целью были эквивалентны. Что могло вызвать увеличение амплитуды в испытаниях с малаяламскими переводами? Является ли это эффектом фонетики?
Интерпретация ранних ERP эффектов
Эффект N/P150, наблюдаемый в временном окне 100–200 мс, может быть приписан эффекту фонетики, поскольку мы манипулировали этой переменной в текущем исследовании. Хотя эффект N/P150 наблюдался в кросс-скриптовых билингвальных парах 29, существуют некоторые оговорки относительно отнесения этого эффекта к фонетике в текущем исследовании, как мы излагаем здесь. Во-первых, мы наблюдали этот эффект только в одном направлении, то есть, когда английские праймы предшествовали малаяламским целям, а не в обратном порядке. Во-вторых, этот эффект наблюдался в основном из-за большей амплитуды ERP малаяламских переводных целей по сравнению с малаяламскими транслитерационными и английскими переводными целями (см. Результаты: ERP эпоха 100–200 мс). Если бы фонетическое перекрытие между праймами и целями было основополагающим механизмом, такой эффект должен был бы наблюдаться, когда малаяламские транслитерационные праймы предшествовали английским целям. Однако этого не наблюдалось в текущем исследовании. Следует отметить, что фонетические эффекты в ERP наблюдаются в более поздних временных окнах (250–350 мс и 350–450 мс 35), а более раннее временное окно показывает (например, 150–250 мс) орфографические эффекты 25,35,36. Однонаправленная разница в амплитуде ERP от англо-малаяламских пар "прайм-цель" перевода указывает на то, что определенные дополнительные факторы могли повлиять на амплитуду ERP в этом временном окне. В следующем разделе мы обсудим возможные причины этих наблюдений.
Одно из возможных объяснений этого эффекта заключается в том, что в текущем исследовании язык-заимствователь всегда был английским. То есть, заимствованные слова всегда были малаяламскими транслитерациями английских слов, но не в обратном направлении (поскольку таких слов очень мало в этой билингвальной паре). Таким образом, малаяламские переводы имели уникальную лексическую форму в каждом языке (например, /me:ʃa/—TABLE). Однако это не относилось к малаяламским транслитерациям, поскольку эти слова имели только одну форму слова (в исходном языке: здесь английском), общую с заимствующим языком (например, CAR {ka:r}). Кроме того, малаяламские цели всегда предшествовали английские праймы. Таким образом, в случае переводных малаяламских целей, английские праймы предварительно активировали бы свои формы слов (например, TABLE), за которыми следовали бы формы слов на малаяламском языке (например, /me:ʃa/—table) целями через 500 мс (т. е. длительность обратного маскирования). Эти две различные формы слова привели бы к определенному конфликту, вызывая увеличение амплитуды ERP (обратите внимание, что существуют ERP-доказательства раннего доступа к лексическим признакам (т. е. 100–200 мс), таким как частота слова и лексичность, при обработке визуально предъявляемых буквенных строк 37). С другой стороны, в случае транслитерационных испытаний, и прайм, и цель активируют одну и ту же форму слова, не вызывая такого конфликта, что приводит к отсутствию разницы в амплитуде ERP. Однако такое увеличение амплитуды ERP произошло только с переводными малаяламскими целями, но не тогда, когда они предъявлялись в качестве праймов (с последующими английскими уникальными целями). Это указывает на то, что разница в схожести форм слов между транслитерационными и переводными испытаниями сама по себе не может объяснить наблюдаемый ERP-эффект в временном окне 100–200 мс. Ниже мы обсудим дополнительные факторы, которые могли повлиять на амплитуду ERP в этом временном окне.
Во-первых, следует отметить, что поведенчески малаяламские цели показали несущественно более длительное RT по сравнению с английскими целями. Во-вторых, малаяламский язык орфографически (и визуально) более сложен по сравнению с английским 33. Наконец, участники данного исследования (применимо к большинству молодых людей в Индии, обучающихся в англоязычных школах), несмотря на их родную беглость в разговорной речи и чтении на малаялам, имели ограниченное представление о письменной форме этого языка по сравнению с письменным английским с раннего детского сада. Обратите внимание, что на момент их привлечения к этому исследованию участники погрузились в полностью доминирующую английскую (академическую) среду в течение минимум 2–6 лет, где формальное знакомство с письменным малаялам отсутствовало. Увеличение частоты ошибок с малаяламскими целями у наших участников (см. Результаты) подтверждает это рассуждение. Учитывая все эти моменты, мы полагаем, что кратковременно предъявляемые английские праймы могли обрабатываться более эффективно, по сравнению с малаяламскими праймами, на подсознательном уровне, что привело к ERP-эффекту в случае переводных англо-малаяламских пар "прайм-цель" в этом временном окне. Однако это требует подтверждения с помощью дополнительных исследований.
ERP в последующих временных окнах (т. е. 200–350 мс и 350–550 мс) также не выявили никакого значимого эффекта ни конгруэнтности прайма, ни целевого языка. То есть, ERP не показали ни эффекта N250, ни эффекта N400. Первый эффект считается показателем обработки отображения орфографии на фонетику, в то время как последний считается отражением семантической обработки 25. В текущем исследовании мы предположили, что, поскольку как переводные, так и транслитерационные пары "прайм-цель" разделяют одинаковое семантическое представление, сравнение даст нулевую разницу, и, следовательно, отсутствие эффекта N400. ERP в последнем временном окне (350–550 мс) подтвердили наш прогноз. Однако более интересны ERP-данные в среднем временном окне (200–350 мс), где ожидался эффект N250. Важно отметить, что в соответствии с поведенческими данными этого исследования, среднее временное окно не показало никакого значимого эффекта (т. е. отсутствие эффекта N250), таким образом, не показав никакого влияния фонетической схожести между праймами и целями в транслитерациях по сравнению с переводами на каждом языке. В то время как более ранние исследования 26,27 приписывали эффект N250 подлексической обработке орфографических стимулов, результат из временного окна 200–350 мс в текущем исследовании указывает на нефонетическую природу этого эффекта. Кроме того, следует отметить, что те исследования, которые показали эффект N250, либо сравнивали семантически конгруэнтные и инконгруэнтные пары "прайм-цель" 28,29, либо использовали только семантически инконгруэнтные пары "прайм-цель" 31. Следовательно, возможно, что семантическая (а не фонетическая) конгруэнтность должна была быть манипулирована, чтобы наблюдать эффект N250.
Выводы
Обобщая наблюдения, до сих пор становится очевидным, что RT не показал никакого влияния фонетики, что, в свою очередь, было подтверждено отсутствующим эффектом N250 ERP. Эти выводы, в целом, не подтвердили влияние фонетики в контексте билингвальной визуальной обработки слов. Основываясь на поведенческих и электрофизиологических данных текущего исследования, мы утверждаем, что при отсутствии орфографического перекрытия между праймами и целями, фонетическая (или комбинированная фонетико-семантическая) схожесть может не влиять на визуальную обработку слов, по крайней мере, в орфографически различных билингвальных парах, таких как в текущем исследовании. Эти выводы могут усилить аргументы о том, что ранние орфографические сигналы могут направлять визуальную обработку слов экономичным, языково-селективным образом 6,7,32. Наконец, разница в ERP в раннем временном окне (100–200 мс) с переводными малаяламскими целями и общая повышенная частота ошибок с малаяламскими целями в этом исследовании могут быть связаны с различием в представленности участников письменных форм малаялам и английского языков. В свете этих наблюдений мы рекомендуем, чтобы будущие исследования визуальной обработки слов у билингвов учитывали представление участников о письменных формах рассматриваемых языков.
Импликации для моделей BIA
Результаты данного исследования предоставляют некоторые инсайты в модели BIA. Как было изложено во Введении, модель BIA 8,9 полагалась в первую очередь на орфографическую схожесть между языками в билингвальном лексиконе. Результаты текущего исследования объяснимы на основе этой модели. Например, орфографические признаки целевого языка идентифицируются на начальном этапе. Согласно модели BIA 8,9, орфографические признаки целевого языка подавляют соседние, менее активированные единицы нецелевого языка, а активация первого продвигается к словам, а затем к языковым узлам. Эти языковые узлы затем подавляют нецелевые слова в билингвальном лексиконе. Поведенчески, отсутствие основного эффекта конгруэнтности прайма подтверждает предсказание модели, поскольку ни транслитерированные, ни переводные праймы (оба в разных орфографиях относительно целевого слова) не повлияли на обработку целевого слова. Однако это наблюдение из текущего исследования вызывает определенные опасения по поводу фонетической схожести между прайм-словом и целевым словом, как это предложено в модели BIA+ 10. То есть, согласно модели BIA+, в дополнение к орфографическому перекрытию, фонетическая и семантическая схожесть между языками также вносят вклад в билингвальную визуальную обработку слов. Поведенческие результаты текущего исследования показывают, что при отсутствии орфографической схожести, фонетическая схожесть между праймом и целью может не оказывать влияния на билингвальную визуальную обработку слов. Например, в случае пары "прайм-цель" транслитерации (P+O–), как прайм, так и цель разделяли одинаковую фонетику и семантику, отличаясь только орфографией. Однако такие пары "прайм-цель" не показали никакого преимущества в скорости реакции (RT) по сравнению с парами перевода (P–O–), тем самым вызывая сомнения относительно роли фонетики в билингвальной визуальной обработке слов, особенно в кросс-скриптовых контекстах. Аналогично, из данных ERP мы ожидали эффект N250, возникающий из-за разницы в фонетике между двумя типами пар "прайм-цель", использованных в этом исследовании. Однако такой эффект не наблюдался. Таким образом, на основе как поведенческих, так и электрофизиологических данных, мы считаем, что при отсутствии орфографического перекрытия (как в текущем исследовании), фонетическая (и семантическая) схожесть между праймами и целями не демонстрирует никакого преимущества в обработке. Результаты данного исследования, таким образом, подтверждают модель BIA 8,9, но не модель BIA+ 10 в контексте кросс-скриптовой визуальной обработки слов.
Метод
Участники
В исследовании приняли участие восемнадцать взрослых малаялам-английских билингвов в возрасте от 18 до 25 лет (средний возраст = 21.4 года). Малаялам был их родным языком (L1), а английский — вторым языком (L2). Все участники начали изучать английский язык до 5 лет с началом детского сада и оценивали свой уровень владения этим языком от 5 до 7 по шкале от 1 до 7, указывая на "хорошее" до "почти родное" владение в разговорной речи, слушании, чтении и письме. Ни у кого не было истории или жалоб на неврологические, слуховые или языковые расстройства. У всех было нормальное или скорректированное до нормального зрение. Размер выборки сопоставим с исследованиями, в которых использовалась аналогичная методология для изучения фонетической обработки с использованием ЭЭГ 5,14,15,23,29,37. Размер выборки также был достаточен для выявления различий в ERP между двумя условиями в дизайне внутри субъектов с 80% мощностью (с использованием симуляции данных для кластерных пермутационных тестов 38). Исследование было одобрено этическим комитетом Колледжа медицинских профессий Манипальской академии высшего образования. Информированное согласие было получено от всех участников. Все методы выполнялись в соответствии с соответствующими руководящими принципами и правилами.
Стимулы
Для этого исследования был выбран набор из 100 английских слов (названия объектов/предметов), из которых 50 имели уникальные эквиваленты перевода на малаялам (например, Table– /me:ʃa/), а остальные не имели таких переводов на малаялам (например, CAR/car/). То есть, последний набор английских слов был заимствован в малаялам таким образом, что он был написан на малаяламской орфографии, хотя и произносился подобно английскому произношению (т. е. транслитерированные слова: например, CAR). Английские слова имели длину от 3 до 11 букв, а их транслитерированные и переведенные малаяламские эквиваленты — от 2 до 5 букв. Эта разница в длине символов ожидаема, поскольку английский язык является алфавитным, в то время как малаялам — алфасиллабарий (больше похожий на слоговую орфографию). Переведенные и транслитерированные английские слова (на малаялам) не отличались по частоте (t = -0.38, p = 0.7), длине слова (t = -0.97, p = 0.33), частоте биграмм (t = -1.3, p = 0.19), а также по плотности орфографического соседства (t = -1.01, p = 0.31) (English Lexicon Project). Поскольку малаяламские слова не содержали информации по этим переменным, мы получили оценку узнаваемости (по шкале от 1 до 5: 1 — очень знакомый, 2 — знакомый, 3 — незнакомый, 4 — очень незнакомый, и 5 — никогда не слышал) первоначального корпуса из 170 малаяламских слов от пяти носителей языка. На основе их оценок мы выбрали по 50 слов для испытаний с переводом и транслитерацией, которые получили рейтинг "очень знакомый" или "знакомый" от всех участников (кто оценивал). Эти два набора малаяламских слов не отличались друг от друга по рейтингу узнаваемости (t = -0.8, p = 0.42). Стимулы, использованные в этом исследовании, а также их детали приведены в Дополнительных материалах.
В этом исследовании мы специально исследовали влияние фонетической схожести/несхожести праймов на обработку целевых слов. Поэтому мы не вводили никаких семантических контролей (например, не-слов). Таким образом, все праймы и цели были настоящими словами. Мы использовали четыре типа отношений "прайм-стимул", такие как: a) L2L1 фонетически конгруэнтные (т. е. английское заимствованное слово-прайм — малаяламское транслитерированное слово-цель: например, car{ka:r}), b) L2L1 фонетически инконгруэнтные (т. е. английское уникальное слово-прайм — малаяламское переводное слово-цель: например, table—{me:ʃa}), c) L1L2 фонетически конгруэнтные (т. е. малаяламское транслитерированное слово-прайм — английское заимствованное слово-цель: например, {ka:r}CAR), и d) L1L2 фонетически инконгруэнтные (т. е. малаяламское переводное слово-прайм — английское уникальное слово-цель: например, {me:ʃa}—TABLE). Таким образом, следует отметить, что и прайм, и цель всегда представляли одно и то же понятие во всех условиях, тем самым нивелируя любой эффект семантики. Кроме того, орфография прайма и цели всегда отличалась во всех условиях. Только фонетика различалась между праймом и целью. В испытаниях с транслитерацией фонетика прайма и цели совпадала, в то время как в условии перевода — нет.
Процедура
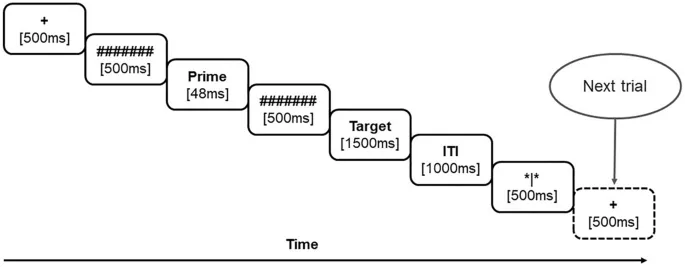
Участники сидели примерно в 100 см от монитора компьютера (с частотой обновления 60 Гц) в удобном кресле. Оба прайм- и целевые слова отображались в центре 24-дюймового монитора в виде черных букв на белом фоне шрифтом Baraha (Baraha 7.0). Схема предъявления испытания показана на Рис. 3. Каждое испытание начиналось с предъявления фиксационного креста (+) в центре экрана в течение 500 мс, за которым следовал прямой маскирующий символ (######) в течение 500 мс. Прайм предъявлялся в течение 48 мс, после чего его заменял обратный маскирующий символ (######) на 500 мс. Цель следовала за обратным маскированием и оставалась на экране в течение 1500 мс или до тех пор, пока участник не давал ответ. Английские слова в позиции прайма были в нижнем регистре (Блок 1), а в позиции цели — в верхнем регистре (Блок 2). После того, как целевое слово исчезало, следовал межстимульный интервал в виде пустого экрана продолжительностью 1000 мс, за которым следовал "мигающий экран" (*|*) в течение 500 мс, в течение которого участникам разрешалось моргать, если они желали. Их задачей было нажать "1" для названий природных объектов (например, земля), и "2" для искусственных объектов (например, компьютер) на правых цифровых клавишах стандартной компьютерной клавиатуры. Все участники выполняли семантическую оценку переводных и транслитерированных пар "прайм-цель" (N = 50 каждая) на обоих языках (общее количество испытаний = 200). Половина участников сначала получала малаяламские слова в качестве целей (с английскими праймами), а другая половина — английские цели первыми (с малаяламскими праймами). Эксперимент был разработан и развернут с использованием программного обеспечения EPrime (Eprime 2.0).
Процедура регистрации ЭЭГ
Непрерывная ЭЭГ регистрировалась с помощью 30 скальповых электродов Ag–AgCl, установленных в электродной шапочке (QuickCap, Compumedics Neuroscan 4.5) в соответствии со стандартной системой 10/20. Заземляющий электрод располагался между FPz и Fz. Электрическая активность с обоих сосцевидных отростков регистрировалась с левым сосцевидным отростком (M1) в качестве референса. Два электрода, расположенные над и под левым глазом, измеряли вертикальные движения глаз (VEOG), а другая пара электродов, расположенная у наружных углов глаз, измеряла горизонтальные движения глаз (HEOG). Сопротивление каждого электрода поддерживалось ниже 5 кОм. Сигнал от скальповых электродов усиливался в 20 000 раз (усилитель SynAmps 2, Compumedics), дискретизировался с частотой 1000 Гц и фильтровался онлайн с верхней границей 100 Гц.
Анализ данных
Мы использовали тулбоксы EEGLAB 39, ERPLAB 40 и FieldTrip 41, работающие на MATLAB 2020a (Mathworks, Natik, MA, USA), для анализа данных. Непрерывные данные ЭЭГ фильтровались (полосно) с использованием оконного FIR-фильтра с диапазоном от 0,1 до 30 Гц с подавлением 12 дБ/октаву. Затем ЭЭГ разделялась на эпохи продолжительностью от 100 до 800 мс относительно наступления цели с использованием ERPLAB. Было 4 условия: (1) фонетически конгруэнтный английский прайм — малаяламская цель (т. е. малаяламские транслитерированные слова); (2) фонетически инконгруэнтный английский прайм — малаяламская цель (т. е. малаяламские переводные слова); (3) фонетически конгруэнтный малаяламский прайм — английская цель (т. е. английские заимствованные слова); и (4) фонетически инконгруэнтный малаяламский прайм — английская цель (т. е. английские уникальные слова). Эти эпохи были нормализованы по базовой линии в период от 100 до 0 мс. Затем данные ЭЭГ подвергались анализу независимых компонентов с использованием EEGLAB. Впоследствии мы использовали автоматический инструмент классификации (ICLabel 42) для выявления шумных компонентов в данных ЭЭГ. Компоненты с порогом > 80% для "бликов глаз", "мышечной активности" и "шума канала" были исключены из данных ЭЭГ каждого участника. Дополнительно мы удалили все эпохи у всех участников, которые превышали амплитуду ± 80 мкВ в любой момент времени (артефакты). Каждый участник имел по крайней мере 80% эпох без артефактов в каждом условии. Без артефактные эпохи каждого участника, относящиеся к каждому из этих четырех условий, были усреднены. Наконец, мы отдельно усреднили эпохи четырех условий по всем участникам, чтобы получить общее среднее значение для четырех условий.
Статистический анализ данных ERP
Статистический анализ проводился в два этапа. Первый анализ был основан на литературе, где электроды и временные диапазоны интереса выбирались на основе предыдущих исследований 27,28,43,44. ERP усреднялись по 9 электродам вокруг Cz (CP4, C4, CP3, CPz, Cz, FC4, C3, FCz, FC3), и амплитуды рассчитывались в трех временных окнах: 100–200 мс, 200–350 мс и 350–550 мс. Эти амплитуды подвергались дисперсионному анализу (ANOVA) с повторными измерениями 2×2 с факторами "Целевой язык" (английский, малаялам) и "конгруэнтность прайма" (переведенный, транслитерированный).
Второй анализ был полностью основан на данных, поскольку анализ, основанный на литературе на предыдущем этапе, был ограничен только известными эффектами ERP. Для этого использовались непараметрические кластерные пермутационные тесты 45. Мы провели кластерную пермутационную ANOVA с повторными измерениями 2×2 с "Целевым языком" (английский, малаялам) и "конгруэнтностью прайма" (переведенный, транслитерированный) в качестве факторов. Основные эффекты и взаимодействия тестировались отдельно. Анализ включал все временные точки от 0 до 600 мс и все электроды. Сначала проводилась серия t-тестов для каждого электрода и временной точки. Из этих временных точек были определены те, где волновые формы значимо различались друг от друга (p < 0.05, двусторонний) для каждого канала. Затем формировались кластеры путем соединения временных точек, показывающих значительный эффект, на основе временной и пространственной смежности. Это делалось отдельно для точек данных, показывающих положительные и отрицательные t-значения. Статистика на уровне кластера рассчитывалась путем суммирования всех t-значений в пределах кластера (массовый t-оценка). Для контроля ошибок I рода, вызванных множественными сравнениями (30 каналов × 600 временных точек), использовался пермутационный подход. Для этого создавалась нулевая гипотеза на основе данных путем случайного обмена метками стимулов внутри участников 5000 раз и вычисления массовых t-оценок для каждой рандомизации. Массовые t-оценки, полученные на первом этапе, затем сравнивались с нулевой гипотезой. Кластер считался значимым, если он попадал в верхние 2.5% или нижние 2.5% нулевой гипотезы.
Ссылки
[1] De Groot, A. M. B. & Kroll, J. F. (2007). Lexical representation and semantic access. In The handbook of bilingualism: Psychological, social and educational aspects (pp. 159–176). Cambridge University Press.
[2] Kroll, J. F. & Stewart, E. (1994). Category interference in translation and lexical decision: Evidence for asymmetric connections between bilingual memory representations. Journal of Memory and Language, 33(2), 149–174.
[3] Dijkstra, T. & Van Heuven, W. J. B. (2001). Structuralл bilingual lexical access. In Models of cognitive–linguistic processing (pp. 141–161). Springer.
[4] Altarriba, J. (2000). From English to Spanish: Verb aspect and tense in the translation process. Bilingualism: Language and Cognition, 3(3), 137–151.
[5] Hoshino, N., Ueno, M., Okita, S., et al. (2016). Electrophysiological correlates of masked phonological priming in Japanese–English bilinguals. Cognition, 152, 112–122.
[6] Gollan, T. W., Navarro, A. E. & Lupyan, G. (2012). Script effects on lexical processing in bilinguals. Psychological Science, 23(10), 1211–1218.
[7] Shintani, N. & Taylor, L. (2016). The influence of orthography on word processing in cross-script bilinguals: Evidence from a picture-word interference task. Bilingualism: Language and Cognition, 19(1), 223–233.
[8] Dijkstra, T. & Van Heuven, W. J. B. (1998). Structuralл Bilingual Interactive Activation Model. In Bilingualism, Brain and Cognition (pp. 101–111). Elsevier.
[9] Van Heuven, W. J. B., Dijkstra, T. & Schreuder, R. (1998). Orchestration of lexical access in bilingual speech. In Bilingualism, Brain and Cognition (pp. 111–127). Elsevier.
[10] Dijkstra, T. & Van Heuven, W. J. B. (2001). Structuralл Bilingual Interactive Activation + Lexical and Conceptual Representations. In Models of Cognitive–Linguistic Processing (pp. 141–161). Springer.
[11] Lemhofer, M. & Perfetti, C. (2002). Visual word identification in L2: Language-selective versus language-non-selective processing. Journal of Experimental Psychology: Learning, Memory, and Cognition, 28(6), 1045–1057.
[12] Miellet, S., Perani, D., Cappa, S. F., et al. (2009). Orthographic and phonological processing of written words in bilinguals. Brain and Language, 110(3), 129–137.
[13] Pan, S. L., Zhang, Y., Zhang, C., et al. (2020). Phonological mediation in cross-script bilingual word recognition. Journal of Memory and Language, 113, 104113.
[14] Kutas, M. & Hillyard, S. A. (1980). Eventrelated brain potentials (ERPs) in vision: An overview. Psychology of Vision, 1, 129–180.
[15] Peleg, O., Shlomi, R., Durgi, Z., et al. (2018). Phonological mediation in cross-script (Arabic–Hebrew) bilinguals. Journal of Experimental Psychology: Learning, Memory, and Cognition, 44(9), 1434–1447.
[16] Forster, K. I. & Steele, C. M. (1973). Sequential effects in word recognition. Quarterly Journal of Experimental Psychology, 25(1), 144–166.
[17] Snodgrass, J. G. & Levy, J. J. (1975). Visual processing of words and nonwords. Psychonomic Science, 7(4), 316–319.
[18] Hino, Y., Lupyan, G., & Goldrick, M. (2010). Phonological facilitation of word recognition in Mandarin–English bilinguals. Journal of Experimental Psychology: Learning, Memory, and Cognition, 36(2), 443–457.
[19] Jiang, T., Li, P. & Liu, S. (2017). Processing of translated and untranslated words in Chinese–English bilinguals. Journal of Experimental Psychology: Learning, Memory, and Cognition, 43(12), 2087–2100.
[20] Perfetti, C., Tan, L. H. & Zola, D. (2009). The neurocognitive bases of literacy acquisition and its implications for the development of reading and writing. Annals of Dyslexia, 59(2), 145–166.
[21] Neely, J. G. (1977). Semantic priming effects in English and Spanish: A test of the language interdependence hypothesis. Journal of Experimental Psychology: Human Perception and Performance, 3(1), 78–91.
[22] Bentin, S., Perry, R. J., McGlennen, K. M., et al. (1999). An event-related potential investigation of orthographic and phonological processing in the Chinese lexicon. Journal of Cognitive Neuroscience, 11(3), 294–303.
[23] Taylor, M. J., & O'Hanlon, C. (1998). The N100m component and visual word processing. Electroencephalography and Clinical Neurophysiology, 106(1), 1–9.
[24] Sereno, S. C. & Rayner, K. (2005). When, and how, do we process visual word form information? Trends in Cognitive Sciences, 9(5), 234–241.
[25] Poldrack, R. A., Waelde, L. C., McMains, S. A., et al. (2001). Neural correlates of semantic and phonological processing during word list learning. Neuroimage, 13(1), 39–47.
[26] Dehaene, S. (2007). The neural basis of reading. Neuron, 53(2), 159–177.
[27] Grainger, J. & Nedergård, T. (2000). Phonological processing of visual words: Evidence from ERPs. Psychonomic Bulletin & Review, 7(2), 306–314.
[28] Barber, H. A., Bekinschtein, T. A., Otten, L. J., et al. (2004). Semantic and phonological influences on lexical access: An ERP study. Brain Research Cognitive Brain Research, 20(2), 161–171.
[29] Hoshino, N., Ueno, M., Okita, S., et al. (2016). Electrophysiological correlates of masked phonological priming in Japanese–English bilinguals. Cognition, 152, 112–122.
[30] Federmeier, C. D., Wlotko, E. W., De B., et al. (2007). Predicting the future from the past: Cross-language semantic priming effects in bilinguals. Journal of Experimental Psychology: Learning, Memory, and Cognition, 33(6), 1035–1046.
[31] Chauncey, K., Holcomb, P. J. & Kutas, M. (2015). Processing of L1 and L2 words by bilinguals: An ERP study. Brain and Language, 146–147, 17–26.
[32] Hoversten, E., Kim, K. H., & Zhang, Y. (2015). Script effects in bilingual visual word processing: ERP evidence. Psychophysiology, 52(S1), S81–S81.
[33] Annamalai, E. & Stein, K. H. (1996). Pragmatics of Hindi and Malayalam numeral systems. The University of Michigan.
[34] Seidenberg, M. S. (1985). Visual word recognition and pronunciation. In Neuroscience and behavior perspectives on reading disorders (pp. 70–92). Little, Brown.
[35] Assadollahi, S. & Al-Jumaily, Z. M. (2012). Phonological processing of pseudowords in Arabic–English bilinguals: An ERP study. Brain Research, 1438, 115–123.
[36] Vrode, A., Szubanik, K., Zwitserlood, P., et al. (2014). Orthographic and phonological processing in bilingual word recognition. Bilingualism: Language and Cognition, 17(2), 309–322.
[37] Kuperberg, G. R., Lovett, M. L., Holcomb, P. J., et al. (1999). Differential ERP effects to pseudohomophones and real words: Evidence for phonological processing of visually presented words. Cognitive Brain Research, 7(4), 337–350.
[38] Maris, E. & Oostenveld, R. (2007). Nonparametric statistical testing of EEG- and MEG-data. Journal of Neuroscience Methods, 164(1), 177–190.
[39] Delorme, A. & Makeig, S. (2004). EEGLAB: An open source toolbox for analysis of single-trial EEG, MEG and other electrophysiological data. Journal of Neuroscience Methods, 134(1), 9–21.
[40] ERPLAB: an open-source toolbox for electrophysiological data analysis. [Online]. Available: https://erpinfo.org/erplab. [Accessed 25 Oct. 2023].
[41] FieldTrip: Open-source software for analysing human neurophysiological data. [Online]. Available: https://www.fieldtriptoolbox.org/. [Accessed 25 Oct. 2023].
[42] ICLabel: an automated electrophysiological data labeling tool. [Online]. Available: https://github.com/rohitkhandwala/ICLabel. [Accessed 25 Oct. 2023].
[43] Hauk, O., Formisano, E., Salmond, C. H., et al. (2006). Brain activations during successful and unsuccessful retrieval of episodic memories. Neuron, 49(4), 617–627.
[44] Pulvermüller, F. (2001). Autonymy and heteronomy of word meaning. Trends in Cognitive Sciences, 5(4), 151–157.
[45] Nichols, T. E. & Holmes, A. P. (2002). Nonparametric permutation tests for functional neuroimaging data: A tutorial and review. Neuroimage, 15(1), 1–25.
Благодарности
Авторы выражают благодарность Исследовательской инициативе когнитивных наук Министерства науки и технологий правительства Индии за исследовательскую поддержку корреспондирующего автора данного исследования. Авторы также хотели бы поблагодарить двух анонимных рецензентов за их полезные комментарии к предыдущей версии рукописи.
Информация об авторах
Авторы и учреждения:
Колледж медицинских профессий, Манипальская академия высшего образования, Манипал, Карнатака, 576104, Индия
Адхвика Шетти, Санджана П. Хеббар, Раджат Шенной и Гопи Кришнан
Школа здравоохранения и поведенческих наук, Университет Саншайн-Кост, Сиппи Даунс, Австралия
Варгезе Питер
Вклад авторов
Г.К. придумал и разработал исследование. А.С., С.П.Х. и Р.С. собрали данные. В.П., Г.К. и А.С. проанализировали данные и подготовили рукопись. Все авторы утвердили окончательную версию рукописи.
Корреспондирующий автор
Переписка с Гопи Кришнаном.
Декларации об этике
Конкурирующие интересы
Авторы заявляют об отсутствии конкурирующих интересов.
Дополнительная информация
Примечание издателя Springer Nature сохраняет нейтралитет в отношении территориальных претензий в опубликованных картах и институциональных принадлежностях.
Дополнительная информация: Дополнительная информация.
Права и разрешения
Открытый доступ Эта статья лицензирована в соответствии с Международной лицензией Creative Commons Attribution 4.0, которая разрешает использование, обмен, адаптацию, распространение и воспроизведение на любом носителе или в любом формате, при условии, что вы должным образом укажете автора (авторов) и источник, предоставите ссылку на лицензию Creative Commons и укажете, были ли внесены изменения. Изображения или другие материалы третьих лиц, включенные в эту статью, включены в лицензию Creative Commons статьи, если иное не указано в подписи к материалу. Если материал не включен в лицензию Creative Commons статьи, и ваше предполагаемое использование не разрешено законодательством или превышает разрешенное использование, вам потребуется получить разрешение напрямую от владельца авторских прав. Чтобы просмотреть копию этой лицензии, посетите http://creativecommons.org/licenses/by/4.0/.
Перепечатки и разрешения
Цитирование этой статьи Shetty, A., Hebbar, S.P., Shenoy, R. et al. A primemasked ERP investigation on phonology in visual word processing among bilingual speakers of alphasyllabic and alphabetic orthographies. Sci Rep 12, 9870 (2022). https://doi.org/10.1038/s41598-022-13654-8
Скачать цитату
Получено: 19 ноября 2021 г. Принято: 17 мая 2022 г. Опубликовано: 14 июня 2022 г. Версия записи: 14 июня 2022 г.
DOI: https://doi.org/10.1038/s41598-022-13654-8
Поделиться этой статьей Любой, с кем вы поделитесь по следующей ссылке, сможет прочитать этот контент: Получить ссылку для совместного использования. К сожалению, в настоящее время ссылка для совместного использования недоступна. Скопируйте ссылку для совместного использования в буфер обмена.
Предоставлено инициативой Springer Nature SharedIt по совместному использованию контента.