Интересное сегодня

Введение: вопрос о равной сложности языков
Язык является одной из самых сложных характеристик человека. Но насколько сложен язык? И являются ли примерно 7000 различных языков на Земле одинаково сложными? Количественная оценка статистической структуры и сложности человеческого языка необходима для понимания разнообразных явлений в лингвистике, изучении человеческой культуры и обработке естественного языка — от изучения языка до эволюции языка, от роли культуры в формировании когнитивных навыков до создания искусственного интеллекта.
Гипотеза равной сложности
Гипотеза равной сложности, то есть идея принципа «инвариантности языковой сложности», долгое время была общепринятым и в значительной степени неоспоримым предположением в современной лингвистике. Однако в последнее время исследователи начали оспаривать и scrutinize эту «аксиому». Хотя в настоящее время существует больше консенсуса в том, что сложность языков (и языковых разновидностей) может варьироваться как в различных поддоменах лингвистического описания, так и в целом, не было, насколько нам известно, крупномасштабной количественной оценки гипотезы равной сложности.
Информационно-теоретический подход к сложности
В данном исследовании мы опираемся на теорию информации — область математики, которая связывает вероятность и коммуникацию и предоставляет понятия сложности, которые являются как объективными, так и теоретически нейтральными. Для измерения сложности мы используем статистический подход кодирования, в котором соответствующие условные распределения вероятностей изучаются на основе данных письменного текста, так называемых корпусов.
Энтропия Шеннона становится ключевой мерой для оценки предсказательной сложности языков, измеряя неопределенность при прогнозировании последующих символов в последовательности.
Предсказательная сложность и энтропия
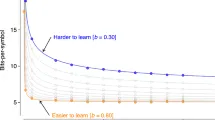
Нечеткое понятие сложности как своего рода вектора отдельных значений, каждое из которых измеряет сложность в различных лингвистических поддоменах, заменяется мерой, связанной с предсказуемостью — чем лучше можно предсказать следующий символ в последовательности из языка, тем ниже сложность этого языка. Одной из ключевых величин в теории информации является средняя информация на символ или скорость энтропии h: поскольку из-за грамматических, фонологических, лексических и других закономерностей, регулирующих использование языка, разрешены не все последовательности символов, h одновременно (i) измеряет, насколько большой выбор есть у писателя при выборе последовательных символов, и (ii) количественно определяет неопределенность читателя при прогнозировании предстоящих символов.
Методология исследования
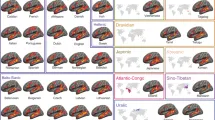
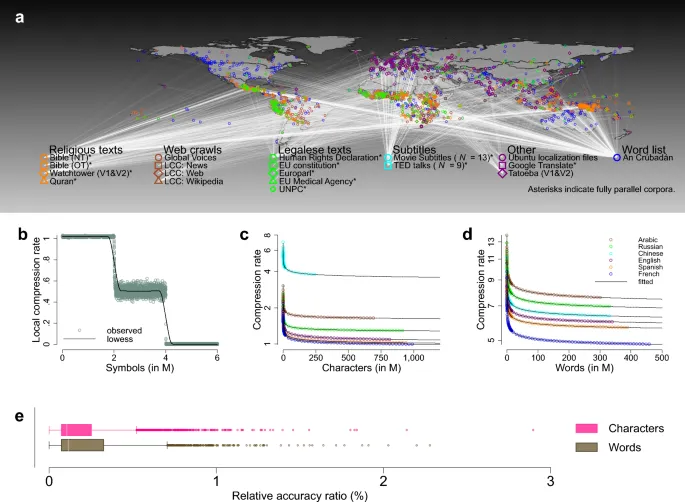
Мы представляем крупномасштабный количественный кросс-лингвистический анализ письменного языка, обучая языковую модель на более чем 6500 различных документах, представленных в 41 многоязычной текстовой коллекции, состоящей из примерно 3,5 миллиардов слов или примерно 9,0 миллиардов символов и охватывающей 2069 различных языков, на которых говорят как на родном более 90% населения мира.
Использование параллельных корпусов
Параллельные корпуса предлагают интригующий источник данных, поскольку они могут считаться переводными эквивалентами: параллельные тексты — это basically тексты на разных языках, содержащие одно и то же сообщение. Следовательно, потенциальные различия в предсказательной сложности нельзя attributed to различиям в содержании, стиле или регистре.
Языковые модели и сжатие данных
Вместо использования человеческих субъектов для оценки энтропии, что было бы highly непрактично, мы используем вычислительные языковые модели (LM). Обучение таких моделей aims минимизировать предсказательную сложность, генерируя наиболее точный и вероятный следующий символ на основе контекста, предоставленного предыдущими символами. Для оценки h(κ) на основе данных корпуса мы используем тот факт, что машинное обучение естественным языкам можно рассматривать как эквивалентное сжатию текста.
Мы используем Prediction by partial matching (PPM), вычислительную LM, первоначально разработанную для сжатия данных, для расчета скорости сжатия r (сжатый размер, деленный на длину сообщения L в символах) как индекса средней предсказательной сложности как для слов, так и для символов как единиц кодирования информации.
Результаты исследования
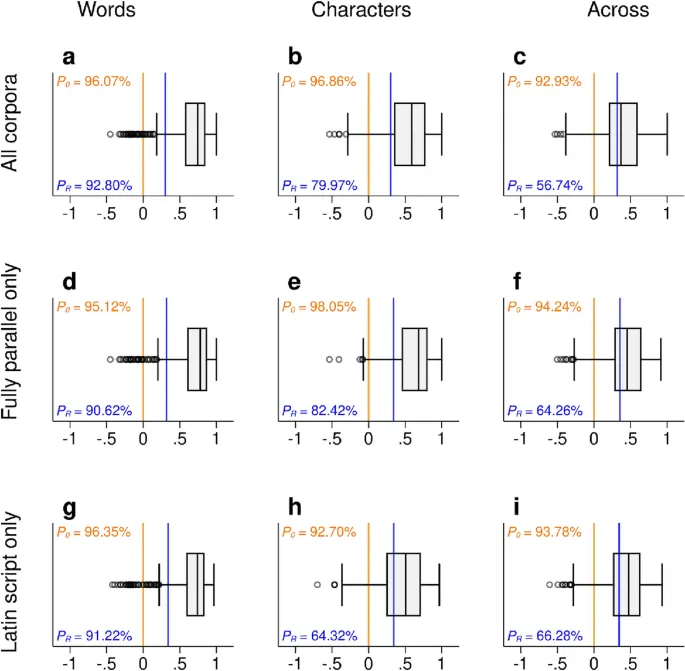
Мы статистически выводим энтропию каждой языковой модели как индекс того, что мы называем средней предсказательной сложностью. Мы сравниваем рейтинги сложности across корпусов и показываем, что язык, который tends быть более сложным, чем другой язык в одном корпусе, также tends быть более сложным в другом корпусе.
Корреляция сложности across корпусов
На уровне слов как единиц кодирования информации средний коэффициент корреляции составляет ρmean = 0,67, медианная корреляция across корпусов составляет ρmed = 0,74. Процент коэффициентов ρ, которые above нуля, составляет Ρ0 = 96,07%. Чтобы put это в perspective, просто by chance мы would expect около 50% всех коэффициентов ρ быть above нуля.
Влияние размера популяции носителей
В addition, мы показываем, что размер популяции носителей predicts энтропию. Контролируя потенциальную не independence точек данных due to филогенетического и географического родства языков в mixed effects modeling подходе, мы показали, что как параметрические p-значения, так и information-theoretic различия в AIC поддерживают идею, что размер популяции носителей является значимым предиктором h.
Обсуждение и выводы
Мы утверждаем, что оба результата представляют собой evidence against гипотезы равной сложности с information-theoretic perspective. Наше исследование подчеркивает potential крупномасштабных кросс-лингвистических анализов в enhancing нашего понимания различных явлений в областях человеческих языков, cognition и культуры.
Ограничения и будущие исследования
Степень, в которой кто-то finds наши результаты убедительными, certainly зависит от степени, в которой кто-то considers наши information-theoretical меры подходящим proxy для общей сложности языка. Было бы highly beneficial выяснить, насколько хорошо наша information-theoretic операционализация сложности relates к более традиционным понятиям языковой сложности.
Кроме того, было бы worthwhile провести более comprehensive examination, чтобы определить, распространяются ли наши findings beyond письменного языка и применимы ли к spoken language. Предварительные результаты, которые мы представили, основанные на корпусе VoxClamantis, могут служить только starting point в этом направлении.
Заключение
В summary, наше исследование challenges давнюю лингвистическую гипотезу о равной сложности всех языков. Используя методы теории информации и машинного обучения, мы продемонстрировали существование устойчивых различий в предсказательной сложности между языками и обнаружили связь между сложностью языка и размером популяции его носителей. Эти результаты открывают новые направления для будущих исследований в области языковой сложности, эволюции языка и когнитивной науки.