
Интересное сегодня


Введение в машинное обучение для классификации звуков
Машинное обучение рассматривается как подраздел искусственного интеллекта, поскольку оно позволяет идентифицировать значимые паттерны из примеров, предоставленных во время обучения. За последнее десятилетие использование методов машинного обучения было расширено для предсказания паттернов восприятия неродной речи слушателями. Это основано на прямых или косвенных предположениях нескольких речевых моделей (например, Модель речевого обучения/SLM, Модель перцептивной ассимиляции/PAM, Модель лингвистического восприятия второго языка, Универсальная перцептивная модель), что акустическое/артикуляционно-фонетическое сходство между звуками первого языка (L1) и второго языка (L2) может предсказать восприятие звуков L2.
Например, Георгиу сообщил, что классификация английских /ɪ/ и /iː/ в терминах кипрско-греческого /i/ и слабое различение этого контраста были успешно предсказаны классификатором машинного обучения. Слабое различение также отразилось в паттернах производства речи говорящими. Таким образом, обучая алгоритмы машинного обучения акустическим характеристикам L1 и предоставляя им те же характеристики неродного языка, исследователи могут оценить перцептивные и потенциально продукционные паттерны неродной речи.
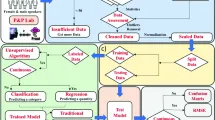
Методы машинного обучения в лингвистике
Линейный дискриминантный анализ (LDA)
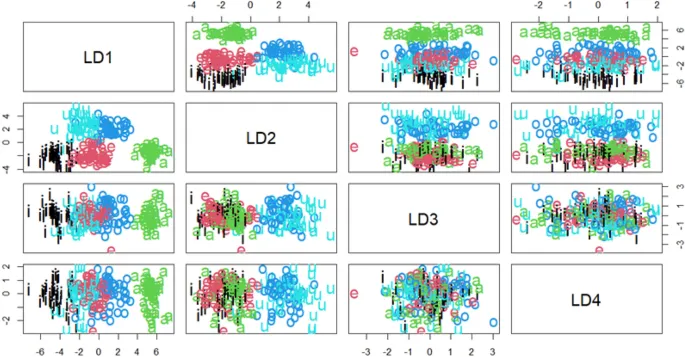
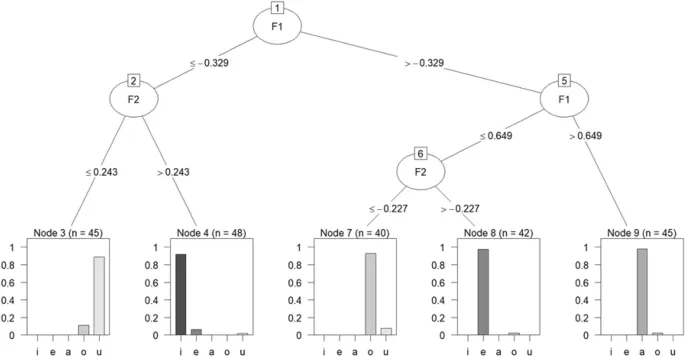
Линейный дискриминантный анализ (LDA) — это классификатор, целью которого является обнаружение линейного преобразования, которое усиливает различимость между различными классами в уменьшенном пространстве измерений. Если предположения о нормальности и гомоскедастичности выполняются, LDA служит наиболее эффективным байесовским классификатором для бинарной классификации. LDA использовался в качестве инструмента для предсказания отображения звуков неродного языка в терминах категорий L1 слушателей в ряде исследований.
Например, Гиличинская и Стрэндж исследовали перцептивную ассимиляцию гласных американского английского к категориям гласных L1 неопытных русских слушателей. Предсказания, проведенные с использованием парадигмы LDA, успешно оценили ассимиляцию всех гласных, кроме одной. В более recentнем исследовании, после обучения алгоритма LDA с F1, F2 и длительностью кипрско-греческих гласных, Георгиу обнаружил, что алгоритм точно предсказал классификацию большинства английских гласных с наивысшей долей в терминах категорий гласных L1. Однако мощность модели значительно снизилась в терминах предсказания полного диапазона ответов выше случайного уровня.
Алгоритм дерева решений C5.0
C5.0 — это еще один алгоритм классификации машинного обучения, appearing как расширение C4.5, который emerged из алгоритма Iterative Dichotomiser 3. Классификатор смоделирован на структуре, напоминающей дерево, и seeks найти лучший признак тренировочного теста, leading к разделению набора данных на подмножества. Процесс terminates в определенной ветви и produces конечный узел, который представляет классификацию, thereby позволяя исследователю оценить quality параметров и contribution входных признаков.
Помимо деревьев решений, алгоритм включает модели на основе правил. C5.0 также использует технику boosting для улучшения производительности модели. Boosting involves повторное применение модели C5.0 к тренировочному набору данных, с акцентом на неправильно классифицированные записи в последующих итерациях. Этот итеративный процесс может помочь уменьшить ошибки предсказания, связанные с bias и variance. C5.0 тестировался только в нескольких акустических исследованиях.
Нейронные сети (NNET)
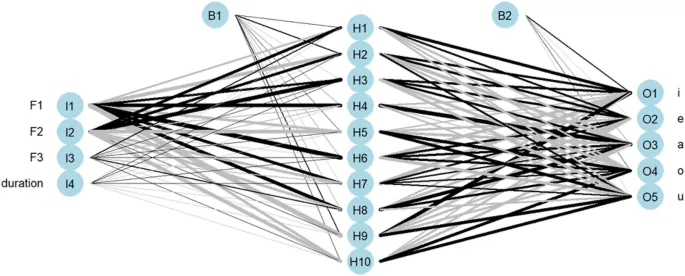
Искусственные нейронные сети — это алгоритмы машинного обучения, имитирующие структуру мозга. Каждый нейрон в сети имеет возможность receive и process входной сигнал и transmit выходной сигнал. Прямые нейронные сети являются одним из самых популярных типов нейронных сетей и отличаются тем, что поток информации является однонаправленным, так как нет петель или циклов.
Обрабатывающие элементы organized в separate слои, где каждый из них receives входные данные из предыдущего слоя и transmits свои выходные данные к subsequent слою. Первый слой — это входной слой, который receives сырые входные данные, последний слой — это выходной слой, который produces предсказанный выход, а между слоями находятся скрытые слои, которые responsible за преобразование входных данных в более meaningful представление.
Методология исследования
Участники и материалы
Все экспериментальные протоколы были одобрены Этическим комитетом Департамента языков и литературы Университета Никосии. Все методы проводились в соответствии с этическими стандартами, изложенными в Хельсинкской декларации 1964 года и ее последующих поправках. Участие было добровольным, и участники могли покинуть эксперимент на любом этапе. Собранные данные оставались в распоряжении исследователя и не разглашались. Каждый участник идентифицировался с использованием кодов для обеспечения анонимности. Информированное согласие было получено от всех испытуемых.
Извлечение речевых характеристик
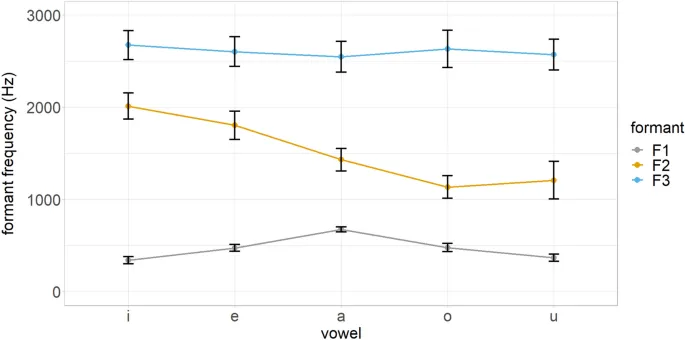
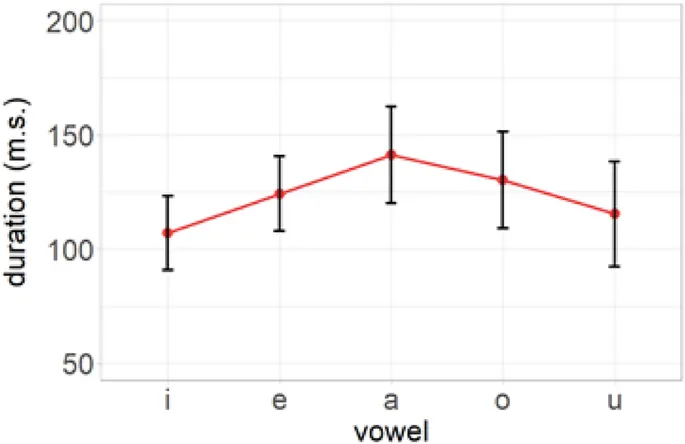
Обучающие данные включали F1, F2, F3 и длительность кипрско-греческих гласных /i e a o u/, произведенных 22 взрослыми кипрско-греческими говорящими. Гласные были встроены в контекст /pVs/ (где V — целевая гласная) и были частью фразы-носителя «Léne tóra» («Они говорят сейчас»).
Тестовые данные включали те же акустические параметры для гласных стандартного южно-британского английского /ɪ iː e ɜː æ ɑː ʌ ɒ ɔː uː ʊ/, произведенных 20 взрослыми английскими говорящими. Они были включены в контекст /hVd/ и были частью фразы-носителя "They say now". Все участники были проинструктированы произносить фразы с нормальной скоростью речи, и их productions были записаны с использованием профессионального аудиорекордера с частотой дискретизации 44,1 кГц.
Акустический анализ
Выходные данные говорящих были отправлены в Praat для речевого анализа. Были сделаны следующие adjustments: длина окна: 0,025 мс, предварительное emphasis: 50 Гц, и диапазон просмотра спектрограммы: 5500 Гц. Для извлечения частот формант начальная точка акустического анализа гласных рассматривалась как конец квазипериодичности предшествующего согласного /p/ для кипрского греческого и /h/ для английского и начальная точка гласной (V), в то время как конечная точка акустического анализа гласных рассматривалась как конец квазипериодичности гласной (V) и начальная точка второго согласного /s/ для кипрского греческого и /d/ для английского.
Результаты и обсуждение
Сравнительная точность алгоритмов
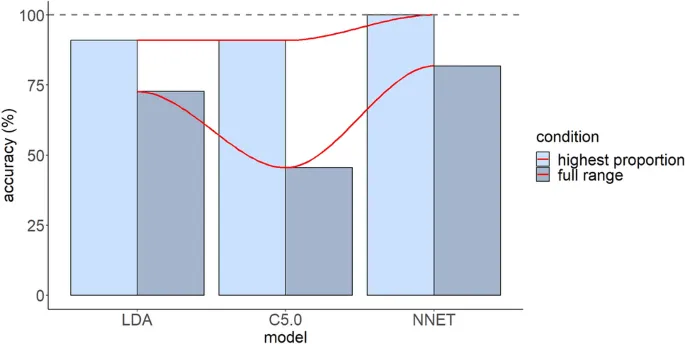
Результаты продемонстрировали хорошую общую производительность для LDA и NNET и плохую для C5.0. Хорошая точность LDA также подтверждается предыдущими evidence. Например, несколько кросс-лингвистических исследований found, что этот алгоритм может quite успешно предсказать mapping звуков L2 к категориям L1. Однако точность предсказания reduced в терминах предсказания полного диапазона ответов выше случайного уровня.
Таким образом, когда demands растут с расчетом диапазона ответов, мощность классификаторов diminished. Это согласуется с результатами данного исследования, поскольку точность предсказания всех моделей dropped в этом condition. Наименьшее decrease было reported для NNET, followed by LDA и C5.0. В addition, в alignment с результатами этого исследования, литература suggests, что NNET demonstrates лучшую производительность в group prediction по сравнению с другими traditional подходами.
Практическое значение исследования
Результаты могут предложить важные insights для формулирования predictions в исследованиях восприятия речи. Более specifically, более sophisticated алгоритмы могут быть employed, такие как нейронные сети, для estimation классификации звуков L2 и development исследовательских hypotheses. Это потому, что они comprise более powerful инструменты по сравнению с traditional методами LDA, которые extensively использовались в past.
Кроме того, findings могут inform педагогику. Выбирая классификатор, который demonstrates оптимальную predictive производительность, educators смогут map трудности learners с разным L1 background в отношении восприятия звуков L2 и therefore develop appropriate образовательные tools и platforms для облегчения изучения L2. Educators могут предложить adaptive и personalized instruction на основе needs отдельных learners, которые могут receive tailored feedback, иметь доступ к customized materials и отслеживать их progress в изучении произношения L2.
Заключение и выводы
Способность моделирования искусственного интеллекта в предсказании классификации звуков L2 в терминах категорий L1 слушателей была точной в алгоритмах NNET и LDA. Это может иметь значительные implications для кросс-лингвистических исследований acquisition речи, которые base их predictions на классификаторах машинного обучения. Помимо традиционных парадигм LDA, парадигмы нейронных сетей, такие как NNET, могут быть использованы для кросс-лингвистической классификации звуков, которые могут быть даже более мощными, чем LDA.
Результаты этого исследования также могут внести ценный вклад в улучшение изучения языков и систем речевых технологий. Будущие исследования могут использовать larger samples и compare точность различных sets классификаторов. Это направление исследований представляет significant interest для развития как theoretical, так и practical аспектов speech processing и language acquisition.





