Интересное сегодня
Введение в гибкость внимания
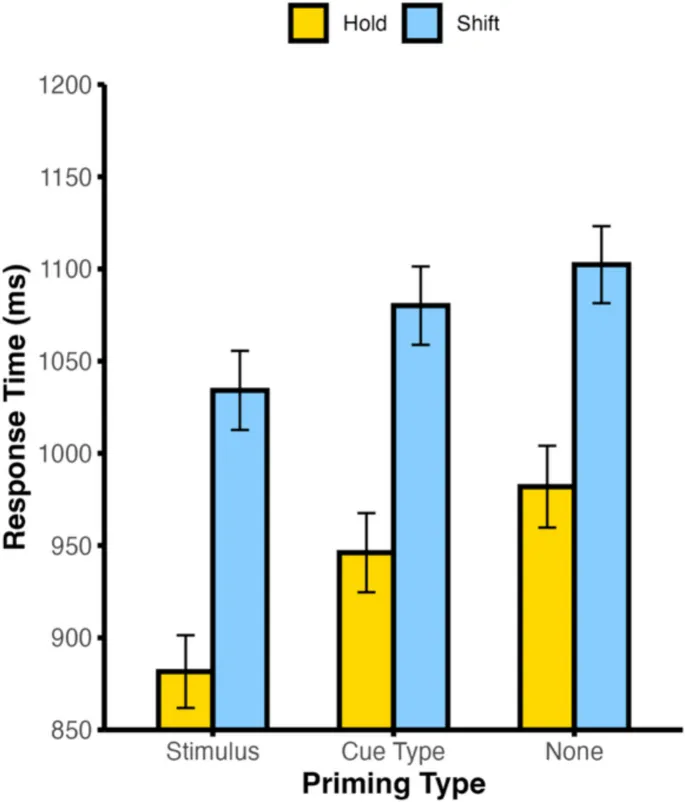
Важным аспектом когнитивного контроля является способность обновлять фокус внимания в ответ на изменяющиеся цели. Люди регулярно сталкиваются с колебаниями готовности к смене внимания, что здесь называется гибкостью внимания. Эти колебания приводят к изменению поведенческих затрат, связанных с переключением (Sali et al., 2016).
Роль обучения в адаптации внимания
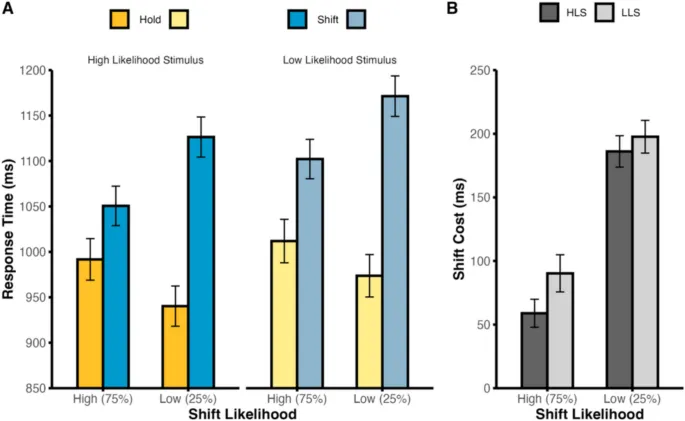
Помимо спонтанных колебаний, люди могут использовать приобретённые ожидания для корректировки готовности к смене внимания в соответствии с текущими требованиями среды (Sali et al., 2015). Однако предыдущие исследования часто смешивали прогнозы о смене внимания и идентичности стимулов, что ограничивало понимание реальных сценариев, где множество сигналов могут указывать на необходимость смены или удержания внимания.
Методология исследования
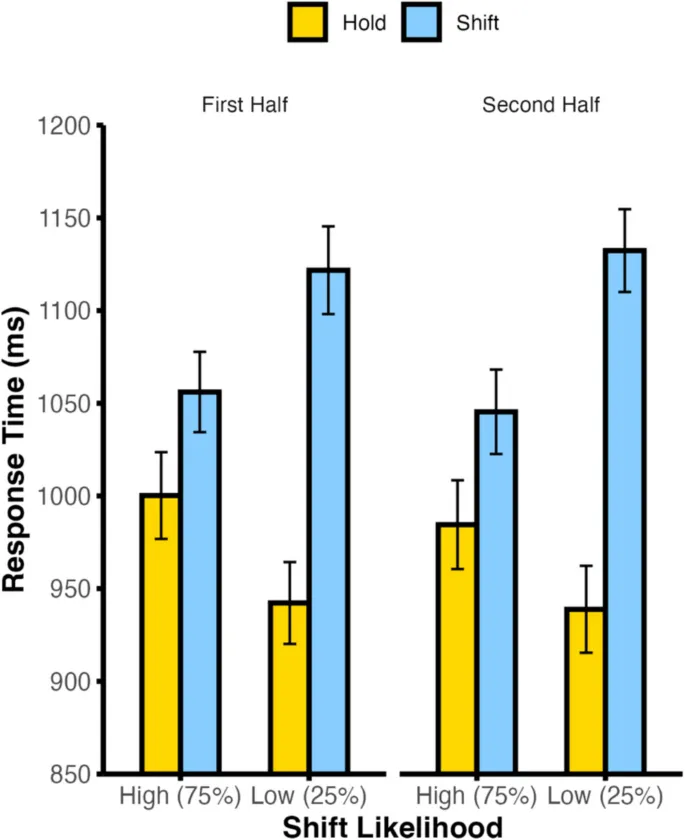
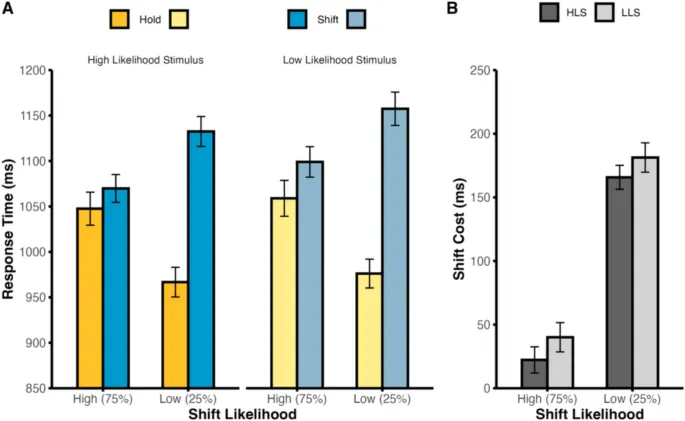
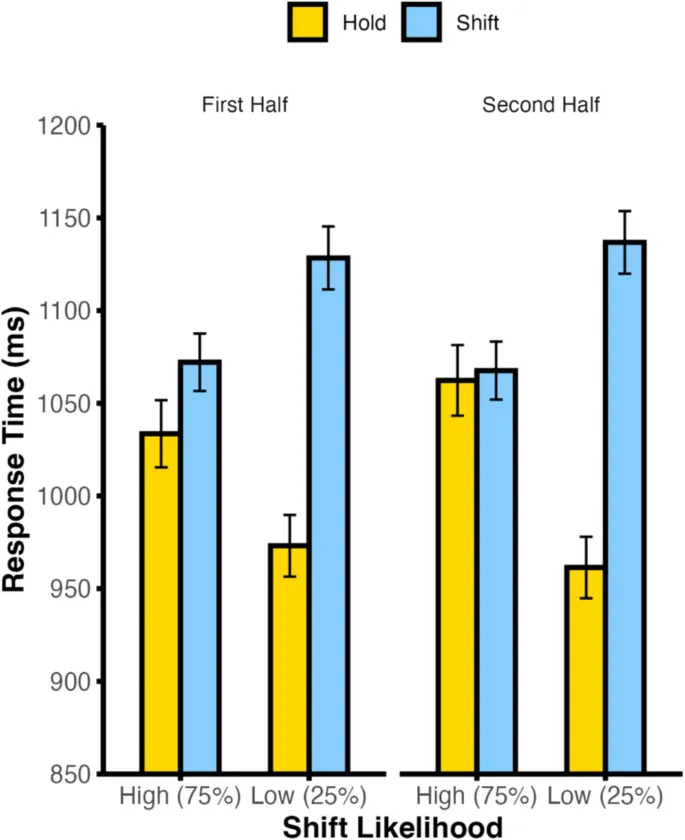
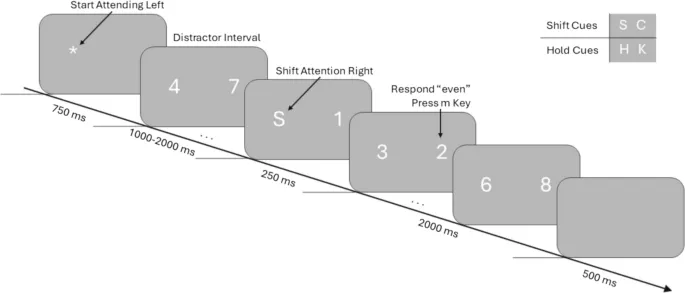
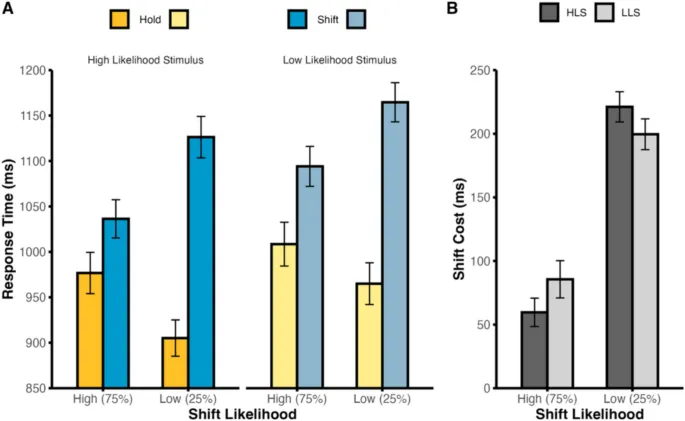
В текущем исследовании мы независимо манипулировали ожиданиями смены внимания и идентичностью стимулов, что позволило разделить ошибки прогнозирования типа сигнала (например, ожидание смены внимания при получении сигнала удержания) от ошибок идентичности стимула (например, ожидание стимула A при получении стимула B).
Роль обучения с подкреплением
Обучение с подкреплением (Reinforcement Learning, RL) рассматривается как механизм, с помощью которого люди формируют и обновляют прогнозы относительно оптимальных состояний когнитивного контроля. Даже без явного вознаграждения точное выполнение задач само по себе является внутренней наградой, а постоянная корректировка состояний контроля позволяет лучше подготовиться к предстоящим когнитивным требованиям (Braem & Egner, 2018).
Результаты и их интерпретация
Наши результаты показали, что нарушения ожиданий как смены внимания, так и идентичности стимулов связаны с замедлением времени реакции. Это указывает на то, что обновление прогнозов может происходить последовательно, а не параллельно.
Практические последствия
Понимание того, как мозг обрабатывает неожиданные события, важно для разработки методов улучшения когнитивного контроля в таких областях, как образование, управление стрессом и реабилитация после неврологических расстройств.