
Интересное сегодня
Введение в проблему распознавания голоса
Распознавание отдельных индивидуумов является ключевым фактором социального поведения многих видов. Люди используют голоса для распознавания личности. Анатомические сигналы от формы и размера гортани, глотки и надгортанного голосового тракта (далее именуемого голосовым трактом) обеспечивают distinct акустическую сигнатуру для разных людей, которая в некоторой степени последовательна across различных типов высказываний. В то время как большие изменения в акустических характеристиках, таких как высота голоса и формантные частоты, могут изменить точность vocal identity, familiarity с идентичностью говорящего позволяет более гибкие акустические изменения в пределах одной идентичности. Это, в свою очередь, повышает точность в задачах дискриминации.
Роль языка в распознавании голоса
Распознавание голоса основано не только на акустических особенностях, высоте тона и формантных частотах. Обучение определенному языку повышает точность распознавания голоса. Эффекты обучения переносятся между похожими языками (например, английским и немецким), но не across dissimilar языков (например, английского и мандаринского китайского), что демонстрирует, что familiarity с фонемами языка дает преимущество в идентификации голоса независимо от понимания. Более того, люди с дислексией испытывают относительно большие трудности с различением речи от неречевых звуков. Как взрослые, так и дети с дислексией демонстрируют более низкую точность идентификации голоса, чем люди без дислексии. Таким образом, язык вносит вклад в распознавание голоса на multiple уровнях.
Влияние раннего опыта и ожиданий
Кроме того, раннее воздействие monolingual speakers против bilingual speakers создает разные наборы ожиданий о статистической регулярности людей, говорящих более чем на одном языке. Это ожидание распространяется на акценты. Исследования с использованием ИИ-клонирования голоса поддерживают идею о том, что мы можем быть предвзяты к ложному различению одного и того же человека как разных людей, когда этот индивидуум говорит с двумя акцентами. Эта предвзятость также может быть замечена в исследованиях младенцев. Mulak et al. обнаружили, что младенцы чувствительны к лингвистическим и indexical изменениям в речи, особенно в гласных звуках. Наше исследование взрослых похоже, но вместо использования высоты гласных в качестве маркера акцента мы используем полные предложения для акцентированных стимулов.
Методология исследования
Все экспериментальные протоколы были одобрены и проведены в соответствии с протоколом Совета по этике исследований Университета Макмастера (MREB) 6187. Информированное согласие было получено от каждого участника до сбора данных. Все данные, код анализа и полные результаты всех анализов для каждого исследования общедоступны на Платформе открытой науки (Open Science Framework).
Стимулы и создание голосов
Мы использовали Retrieval-Based Voice Cloning (RVC) - метод клонирования голоса на основе извлечения признаков, чтобы применять акценты к разным идентичностям. Мы изолировали и извлекли акцентированные речевые паттерны из записей людей с британским, мандаринским и польским акцентами из Архива речевых акцентов английского языка. Далее мы наложили акцентированную речь на 4 мужских и 4 женских голоса из корпуса CSTR VCTK, чьи речевые паттерны были сначала отделены от их идентичностей.
В результате получился набор стимулов, в котором несколько людей говорят своим собственным голосом с речевыми паттернами двух разных людей, которые говорят с британским, мандаринским или польским акцентами. Восемь разных клонированных идентичностей (4 мужчины и 4 женщины) говорили с мандаринским акцентом другого человека, польским акцентом и акцентом британского английского. Мы создали 192 уникальных стимула (4 целевые идентичности × 4 исходные идентичности × 2 пола × 3 акцента × 2 предложения).
Участники исследования
Мы использовали G*Power - программное обеспечение для анализа статистической мощности, чтобы рассчитать количество участников, необходимое для обнаружения наименьшего эффекта, о котором сообщалось в Wester and Karhila. Хотя это был дисперсионный анализ (ANOVA), и мы использовали linear mixed effects regression - линейную регрессию со смешанными эффектами, учитывая, что наша выборка была намного больше, чем у Wester and Karhila, мы уверены в нашей способности обнаружить hypothesized effects. Анализ показал, что для воспроизведения их выводов потребуется всего шесть оценщиков для каждой пары стимулов. Чтобы повысить уверенность в нашей способности обнаружить эффекты, которые мы ищем, мы набрали 1000 участников, чтобы комфортно иметь 10 оценок для каждой из 9710 пар стимулов.
Каждый участник идентифицировал другую случайную выборку из 100 голосовых пар, независимо от их страны происхождения. Участники были случайным образом набраны из людей, проживающих в Великобритании, Китае и Польше. Мы, однако, не балансировали нашу выборку по этим странам, поскольку анализ страны проживания как термина fixed-effects не был целью исследования. Мы также предварительно отсеяли участников, которые самостоятельно сообщали о нарушениях слуха.
Процедура эксперимента
Mulak et al. показывают, что акцентные сигналы влияли на способность младенцев идентифицировать голоса, но только тогда, когда стимулы использовали только гласные звуки для удаления речевых паттернов из идентичности. Таким образом, наше исследование манипулировало как идентичностью, так и акцентом, в полных предложениях. Процедура дала 9 710 комбинаций голосовых пар всех within-sex комбинаций идентичности, акцента и предложения, включая сравнение каждого звука с самим собой.
Каждый участник оценивал случайно выбранное подмножество из 100 пар голосов мужского и женского пола. Порядок пар стимулов и голосов внутри пар был рандомизирован. После предоставления информированного согласия программное обеспечение представляло участникам фиксационный крест, а затем они прослушивали два голоса в паре. После воспроизведения голосов участников спрашивали, считают ли они, что два голоса принадлежат одному и тому же человеку или двум разным людям. Участники должны были нажать «s», если они думали, что голоса принадлежат одному и тому же человеку, или «d», если они думали, что голоса принадлежат разным людям.
Сбор дополнительных данных
После каждого испытания участники оценивали, насколько они уверены в своих ответах, по 3-балльной шкале (1 = Совсем не уверен; 2 = В некоторой степени уверен; 3 = Очень уверен). После завершения всех испытаний участники оценили свою familiarity с каждым из 3 акцентов (мандаринский/польский/британский английский) по той же 3-балльной шкале (1 = Совсем не знаком; 2 = В некоторой степени знаком; 3 = Очень знаком). Наконец, участники повторно дали согласие после того, как им сообщили, что голоса были клонированы, синтезированы и не являются реальными. Участникам платили 9,75 фунтов стерлингов в час пропорционально за 15 минут.
Статистические методы анализа
Мы провели все анализы и построили графики с помощью R и следующих пакетов: dplyr, effects, emmeans, future, ggeffects, ggplot2, ggsci, gridExtra, jtools, kableExtra, knitr, lmerTest, robustHD, scales, sjPlot, tidyr, tidyverse, tools. Все данные, код анализа и полные результаты всех анализов общедоступны на Платформе открытой науки. Мы использовали binary logistic generalized linear mixed effects regression (GLMR) - бинарную логистическую обобщенную линейную регрессию со смешанными эффектами с probit-link function.
GLMER использует partial pooling для уменьшения влияния несбалансированных размеров групп. Нашей переменной ответа было whether (value = 1) or not (value = 0) participants responded что они думали, что голоса принадлежат одному и тому же человеку. Мы effect-coded наши бинарные predictors таким образом, что все условия Different были −0,5 (Different Identity, Different Accent, Different Sentence), а все условия Same были 0,5 (например, Same identity, Same accent, Same sentence). Мы сначала summed familiarity по акцентам, чтобы уменьшить количество random effects terms, а затем z-scored summed familiarity и confidence ratings.
Структура случайных эффектов
Мы использовали maximal random-effects structure, создавая random slopes для всех within-item и within-participant contrast. Наши fixed effects были interactions между voice target identity (same/different), source accent (same/different) и sentence (same/different), а также controlling for confidence и accent familiarity. Для нашего полного кода и вывода см. дополнительные материалы.
Результаты исследования
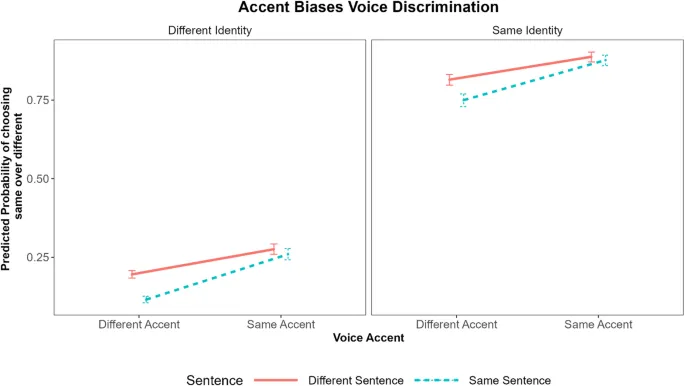
Мы обнаружили three-way interaction между идентичностью, акцентом и предложением. При противопоставлении разницы между одинаковой и разной идентичностью bias пометить кого-то как того же самого увеличился примерно на 62%. Основной эффект идентичности был qualified предложением, что означает, что противопоставление разных и одинаковых предложений уменьшило bias называть людей одинаковыми примерно на 4%. Взаимодействие между идентичностью и предложением было qualified акцентом, в том смысле, что reduction in bias пометить людей как одинаковых, предоставленный разными предложениями, был offset, когда люди использовали разные акценты, примерно на 10%.
Все вышеупомянутые эффекты и взаимодействия присутствовали при controlling for confidence и accent familiarity. Таблица 1 отображает полные details статистического вывода, а Рис. 1 иллюстрирует interactions между идентичностью, акцентом и предложением.
Обсуждение результатов
Мы проверили, влияет ли акцент на дискриминацию голоса, измерив bias объединять людей с разными идентичностями, акцентами и речевым содержанием. Наши результаты позволяют предположить, что акценты влияют на дискриминацию голоса, нарушая существующие когнитивные стратегии для задачи с uninformative biases.
Участники были highly accurate в различении людей по их голосам. Эффекты идентичности на bias объединять людей были very large. Были независимые основные эффекты акцента на дискриминацию голоса, что позволяет предположить, что похожие акценты bias нас объединять разные идентичности. Другими словами, мы предвзяты думать, что люди с разными акцентами - это разные люди.
Влияние акцента на восприятие
Предвзятость к объединению разных людей как одинаковых из-за того, что у них одинаковый акцент, была further qualified тем, что люди говорят одинаковые или разные предложения. Когда идентичность людей была одинаковой, произнесение одинаковых или разных предложений не significantly changed conflation bias в зависимости от акцента. Это может быть связано с тем, что когда люди используют один и тот же акцент, мы лучше able to contrast фонемы друг от друга, а не focusing on larger different across самого акцента.
Однако, когда акценты людей были разными, использование разных предложений увеличивало conflation bias больше, чем когда у них был одинаковый акцент. Использование разных предложений может reduce accent-driven conflation bias, потому что bias от различий между предложениями больше, чем biases различия между одними и теми же словами в разных акцентах. Разница в bias across одинаковых и разных предложений при использовании одинаковых или разных акцентов была slightly more pronounced среди разных идентичностей, чем одинаковых идентичностей. Люди были highly unlikely объединять разные идентичности, говорящие с разными акцентами, если они произносили одно и то же предложение.
Выводы и значение исследования
Если бы результаты здесь были основаны только на familiarity с языком или акцентом, не имело бы значения, кто произносил слова, только то, что они были произнесены с незнакомым акцентом. Кроме того, мы контролировали familiarity с акцентами, включая z-scored ratings как fixed factor. Таким образом, наши выводы являются дополнительными к любым эффектам familiarity, которые могут существовать.
Эффекты акцента на дискриминацию голоса представляли в среднем 10% изменение bias объединять людей как одинаковых. Эти эффекты независимы от familiarity с акцентом. Из-за разницы в размерах выборок across стран мы не анализировали наши данные относительно страны происхождения и рекомендуем будущим исследованиям проверить, имеют ли более dissimilar акценты более сильные эффекты, чем более похожие акценты.
Ограничения исследования
Хотя качество звука и амплитуда во время тестирования могли повлиять на восприятие речи и, следовательно, повлиять на данные, highly unlikely, чтобы это произошло систематическим образом, который мог бы объяснить interactions, о которых мы сообщили. Чтобы решить эту проблему, мы учли variance в ответах due to качество звука и амплитуду, используя participant как random effects term.
В summary, акценты влияют на дискриминацию голоса в addition to другим факторам, таким как familiarity. При различении голосов люди должны быть able to match low-level акустические особенности звуков, экстраполировать и обобщать эту память на новые звуки, которые люди произносят. Наши biases о людях, говорящих с разными акцентами, interfere with этим процессом.
Доступность данных и этические considerations
Все данные, код анализа и полные результаты всех анализов для каждого исследования общедоступны на Платформе открытой науки. Данные, однако, доступны у соответствующего автора по reasonable request. Это исследование было финансировано грантом Discovery Совета по естественным наукам и инженерным исследованиям Канады. Авторы заявляют об отсутствии конкурирующих интересов.





