
Интересное сегодня
Введение
Последние исследования выявили, что человеческие эмоции обладают исключительно сложной и высокоразмерной структурой. Традиционно исследования эмоций были сосредоточены на упрощении эмоций до низкоразмерных моделей, чтобы сделать их более управляемыми. Например, теория базовых эмоций предполагает, что человеческие эмоции можно categorizedровать в шесть фундаментальных типов, в то время как размерный подход отображает эмоции в двумерное пространство, определяемое возбуждением (активное-неактивное) и валентностью (положительное-отрицательное). Эти модели широко применялись в таких областях, как распознавание facial expressions, и продолжают оказывать значительное влияние в психологии и искусственном интеллекте.
Однако недавние исследования, использующие подходы, управляемые данными, предполагают, что человеческие эмоции не могут быть полностью captured в таких низкоразмерных framework, но вместо этого проявляют более сложную, высокоразмерную структуру. Например, используя самоотчеты при просмотре видео, Cowen & Keltner идентифицировали 27 различных эмоциональных измерений на основе крупномасштабных данных самоотчетов, а Koide-Majima et al. идентифицировали 18–36 измерений эмоций, correlated с мозгом, на participant, используя функциональную магнитно-резонансную томографию (фМРТ) и 80 эмоциональных категорий, highlighting тонкие различия и сложные взаимосвязи между эмоциями. Это свидетельство указывает на то, что точное modeling и понимание человеческих эмоций требует более sophisticated подхода, который явно учитывает высокоразмерную природу эмоциональных переживаний.
Мультимодальные языковые модели и эмоции
На этом фоне emerging подход заключается в использовании больших языковых моделей (LLM), особенно мультимодальных LLM (MLLM), для понимания человеческих эмоций. MLLM, integrating возможности обработки текста, изображений и audio в LLM, быстро развивались в последние годы и теперь обладают способностью обрабатывать multiple modalities, не только текст, но также изображения и audio. Они уже продемонстрировали высокую производительность в задачах inference эмоций на основе external expressions, таких как распознавание facial expressions, анализ sentiment на основе текста и распознавание эмоций из речи, текстового содержания и facial expressions.
Если эти MLLM могут выйти за пределы таких ограничений и точно воспроизводить сложность человеческих affective responses, они могут служить ценным новым инструментом для исследования эмоций. Однако вопрос о том, могут ли MLLM точно infer высокоразмерные структуры эмоций, а также эмоции, переживаемые internally людьми, например, при просмотре видео, остается без ответа, и его решение является challenging. Это связано с тем, что эти задачи требуют multi-step процесса inference, который выходит за рамки простого extraction признаков.
Методология исследования
В этом исследовании мы investigated, в какой степени современные MLLM могут accurately предсказывать эмоции, которые люди испытывают при просмотре видео. Для этого мы использовали два набора данных из предыдущих исследований, в которых participants сообщали об эмоциональных оценках, которые они испытывали при просмотре video clips. Затем мы instructed MLLM, включая Gemini и GPT, сообщать эмоциональные оценки для этих видео и оценивали, насколько хорошо predicted эмоции моделей соответствовали человеческим оценкам.
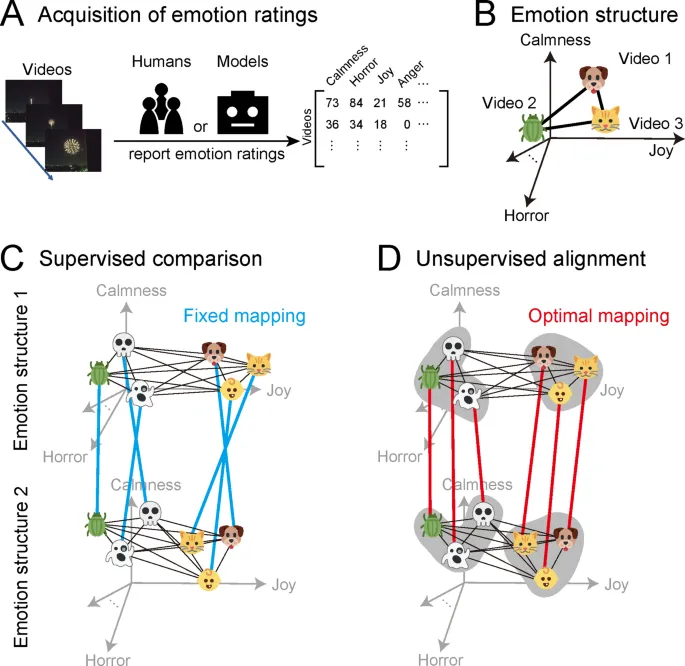
Эмоциональная структура и ее значение
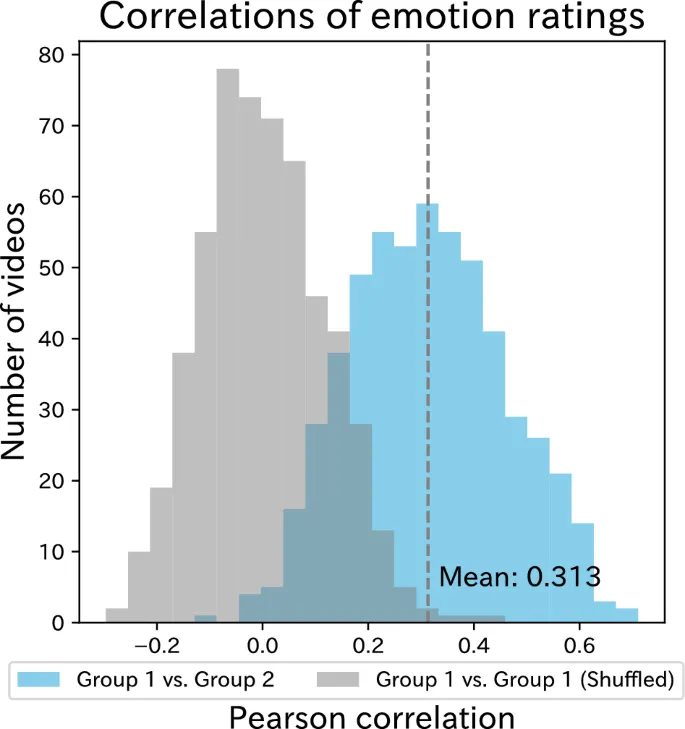
При оценке этих оценок от людей и моделей мы не только examined согласие в эмоциональных оценках для каждого видео, но также focused на patterns и relationships across multiple видео – то есть на эмоциональную структуру. Эмоциональная структура refers к relational структурам эмоций, вызываемых видео. В этом исследовании relationships specifically являются similarity или dissimilarity среди multidimensional эмоциональных responses, evoked различными видео.
Причина, по которой мы focused на сравнении эмоциональных структур across multiple видео, а не на прямых, one-to-one сравнениях эмоциональных оценок, заключается в том, что люди и модели могут differ в том, как они interpret и используют эмоциональные термины. Например, даже seemingly straightforward эмоция, такая как "радость", может использоваться по-разному для эмоциональных оценок разными людьми или computational моделями. Действительно, предыдущие исследования показали, что эмоциональные оценки influenced индивидуальными cognitive tendencies и model-specific biases, leading к considerable variability среди людей и среди computational моделей.
Результаты исследования
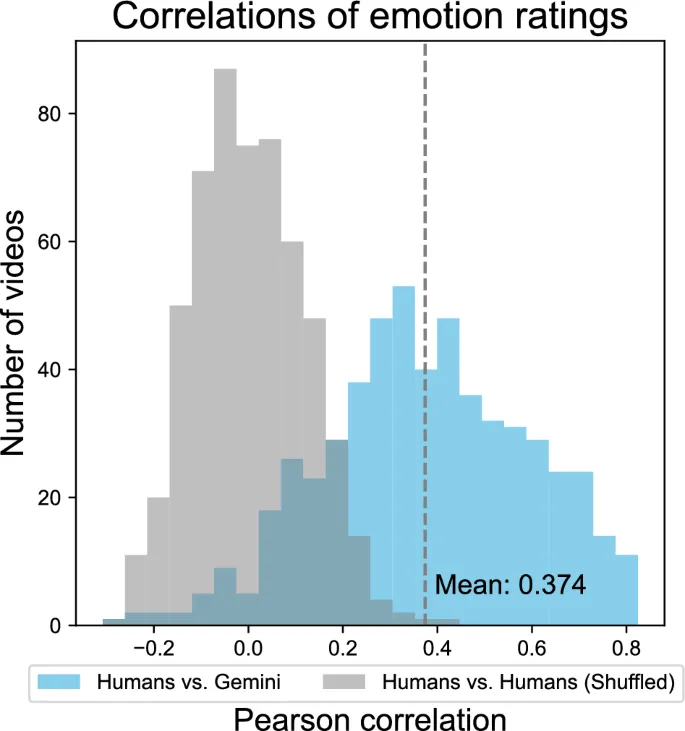
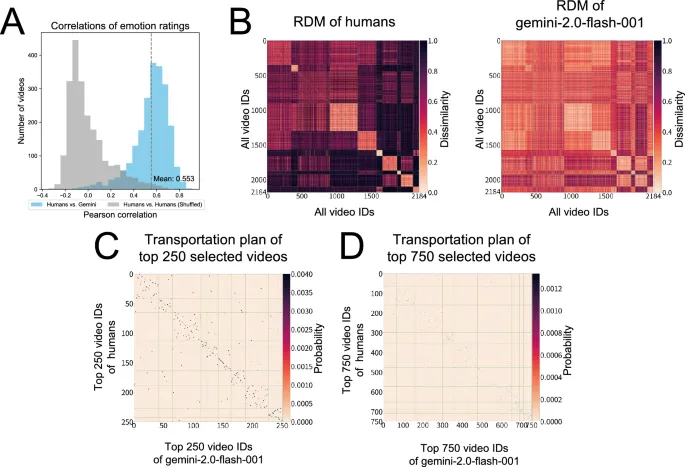
Наше исследование выявило несколько четких findings. Во-первых, в supervised подходе с использованием Analysis репрезентационного сходства (RSA) современные модели, такие как Gemini и GPT, показали высокое структурное similarity с человеческими эмоциональными representations. Это suggests, что MLLM способны accurately captured общие patterns эмоциональных responses, вызываемых у людей во время просмотра видео.
Сравнение на уровне категорий и отдельных элементов
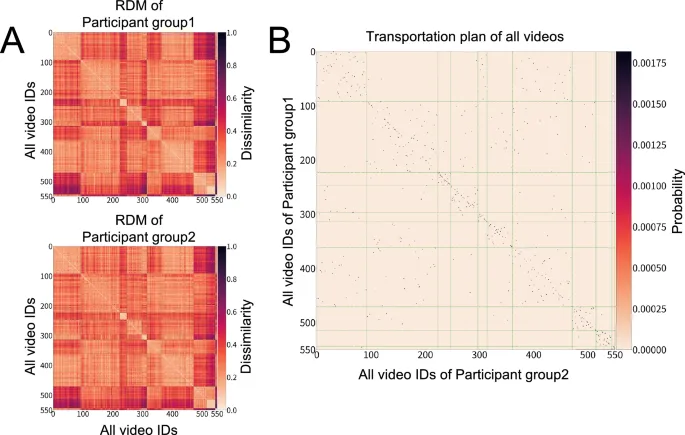
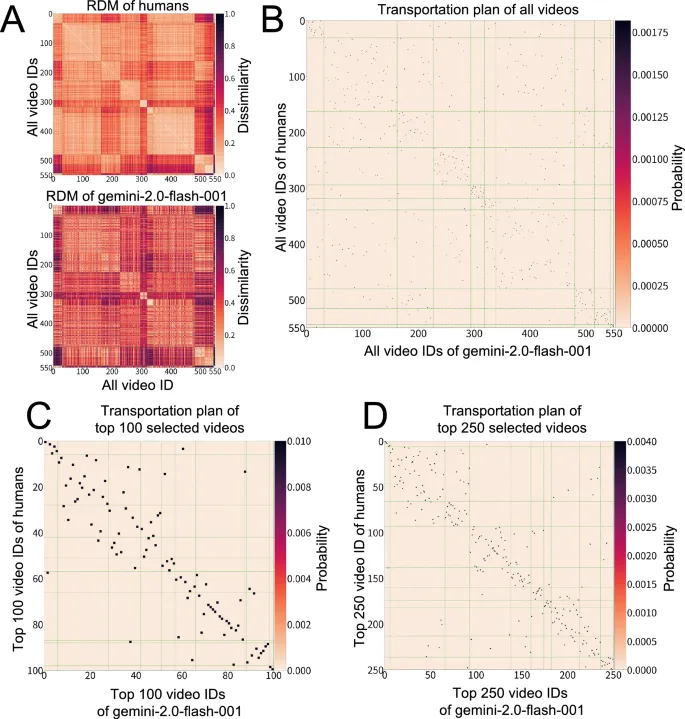
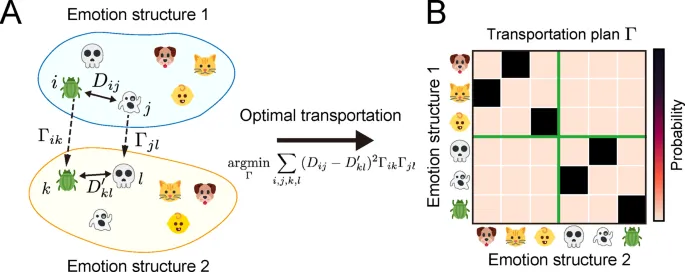
Во-вторых, unsupervised подход с использованием транспортного расстояния Громова-Вассерштейна (GWOT) revealed важные characteristics того, как эмоциональные структуры align между людьми и моделями. В частности, в то время как модели struggled достичь strict one-to-one matching across всех видео, они demonstrated высокую степень alignment на уровне categories. Этот результат underscores значимость использования GWOT в настоящем исследовании.
В отличие от RSA, который требует predefined соответствия между items, GWOT automatically searches для optimal mapping гибким manner, позволяя ему reveal meaningful соответствия на более coarse категориальном уровне, даже когда precise item-level alignment является difficult. Другими словами, хотя существуют limitations в captured тонко-grained, item-specific соответствия, findings suggest, что модели начинают captured более широкую категориальную структуру человеческого эмоционального пространства.
Обсуждение результатов
Взятые вместе, современные MLLM evolved до точки, где они могут captured coarse категориальный framework человеческой эмоциональной структуры. Однако они все еще fall short от enabling precise one-to-one alignment с индивидуальными эмоциональными items. Этот mixed профиль производительности, с сильным alignment на категориальном уровне, но limitations на тонко-grained уровне, служит critical starting point для дальнейшего обсуждения.
Технологические прорывы в MLLM как основа для inference эмоций
Основываясь на результатах этого исследования, вместе с benchmarking результатами по various задачам от ранних моделей до последних MLLM, мы首先 подчеркиваем, что быстрый и значительный технологический скачок в общей производительности MLLM от initial моделей, появившихся около 2023 года, до современных моделей 2025 года, впервые позволил достичь уровня accuracy в inference эмоций, demonstrated в этом исследовании.
Ранние MLLM, такие как BLIP2 и LLaVA1.5, которые появились около 2023 года, demonstrated potential мультимодальной обработки, но столкнулись с многочисленными challenges с точки зрения accuracy визуального распознавания, следования инструкциям и контекстного понимания. Последующий выпуск GPT4V marked значительный progress в benchmark. В наших оценках мы начали наблюдать responses, которые highly correlated с человеческими эмоциональными оценками.
Роль контекста: что MLLM могут и не могут предсказать
Чтобы лучше понять природу этих improvements, мы examined случаи, в которых оценка эмоций worked particularly хорошо. Эти analyses revealed, что MLLM exhibit высокую predictive accuracy с структурной perspective, особенно для эмоций, которые не сильно depend от контекстных cues. Например, видео с младенцами или кошками и собаками consistently elicited predictions "миловидности" или "симпатии".
С другой стороны, MLLM struggled оценить эмоции в видео, которые heavily relied на контекстных cues. Например, в одном видео player attempts highfive с teammate и ignored, в то время как другие players на background seen successfully highfiving. Визуально эта сцена might suggest положительную эмоцию, такую как "восхищение". Однако при рассмотрении более широкого context более accurate эмоциональная interpretation would быть "неловкость". Эти findings indicate, что эмоциональное понимание не может быть derived из визуальных features alone; оно требует interpretation ситуационного и социального context.
Заключение и будущие направления
В дополнение к контекстным cues, было бы beneficial designed модели, которые могут integrated не только социальную контекстную информацию, но и interoceptive signals, такие как heart rate и bodily sensations, которые, как известно, essentially affect восприятие эмоций. Наши findings indicate, что в то время как текущие MLLM perform хорошо в оценке эмоций на основе explicit визуальных features, они все еще face limitations в понимании более complex forms контекста, таких как социальные relationships и временная dynamics.
Критически, такое контекстное понимание involves не только external cues, но и internal bodily states. Фактически, некоторые из видео, которые были particularly challenging для моделей, involved эмоции, такие как "заставляющее сердце биться чаще". Эти типы эмоций might не быть fully interpreted через визуальный input alone и require чувствительность к interoceptive signals в combination с environmental и социальными factors.
Перспективы развития
Поэтому будущие advances в MLLM should involved incorporating diverse modalities в процесс training, чтобы enable более human-like, context-sensitive эмоциональное понимание. Однако another possibility заключается в том, что relatively более низкая accuracy, observed для bodily-driven эмоций, могла бы partly stem от insufficient representation в pretrained наборах данных, а не solely от отсутствия integration interoceptive signal.
Эмоции, сильно influenced bodily sensations, могут быть less frequently articulated explicitly в textual form, possibly limiting их prevalence в standard pretrained данных. Следовательно, incorporating прямые interoceptive signals в architecture модели might не быть strictly necessary. Вместо этого могло бы быть beneficial finetuned существующие pretrained модели на новых наборах данных, специально designed чтобы лучше represented эти emotion-scene ассоциации.
Рассматривая promising производительность MLLM, demonstrated нашими zeroshot результатами, finetuning might provide viable path forward. Будущие исследования should investigated, может ли finetuning pretrained моделей lead к improvements в prediction accuracy и unsupervised alignment для этих potentially challenging эмоциональных контекстов.





