Интересное сегодня
Контекстуальная стабильность и ошибки прогнозирования в сегм...
Представьте, что вы идете по пляжу, а затем продолжаете прогулку в городе. Хотя изначальный опыт каж...
Убийства-самоубийства в США: статистика, жертвы и меры профи...
Основные факты об убийствах-самоубийствах в США Новое исследование Колумбийского университета (Colum...
Симптомная сеть интернет-зависимости, депрессии и тревожност...
Введение Интернет-зависимость, депрессия и тревожность являются значимыми проблемами среди детей и п...
Преимущество левшей в спорте: научное исследование фехтовани...
Преимущество левшей в спорте: научные доказательства Когда я даю интервью о научных исследованиях л...
Влияние сна матери во время беременности на здоровье ребенка
Введение Написание книги о стрессе и болезнях, Toxic Stress: How Stress is Making Us Ill and What We...
Новый метод МРТ для точной диагностики СДВГ у детей: исследо...
Прорыв в нейровизуализации: новый подход к изучению мозга при СДВГ Более пяти процентов детей и под...
ChatGPT не воспроизводит человеческие моральные суждения: важность изучения метрик помимо корреляции для оценки согласия
Развитие генеративного искусственного интеллекта (ИИ) породило утверждения о том, что большие языковые модели (БЯМ) могут заменить людей-участников, особенно в задачах моральных суждений, где корреляция между ChatGPT и людьми приближается к r = 1.00. В ответ на это мы провели заранее зарегистрированное исследование, в котором две БЯМ (textdavinci003 и GPT4o) предсказали человеческие моральные суждения по 60 сценариям до того, как большая выборка людей (N = 940) оценила их. Несмотря на сильные корреляции, показатели разницы выявили существенные систематические ошибки: по сравнению с людьми, БЯМ давали более крайние оценки моральных и нейтральных сценариев, а также более крайние оценки аморальности для неморальных сценариев. Более того, ChatGPT значительно отличался от средних человеческих оценок примерно на 87% сценариев с умеренными и большими размерами эффекта. Кроме того, оценки БЯМ группировались вокруг ограниченного числа значений, не отражая человеческую вариативность. Пересмотр ранее опубликованных данных также отразил эту кластеризацию. Мы заключаем, что необходимы более широкие критерии оценки для сравнения прогнозов БЯМ и ответов человека в задачах моральных рассуждений.
Резюме
Развитие генеративного искусственного интеллекта (ИИ) породило утверждения о том, что большие языковые модели (БЯМ) могут заменить людей-участников, особенно в задачах моральных суждений, где корреляция между ChatGPT и людьми приближается к r = 1.00. В ответ на это мы провели заранее зарегистрированное исследование, в котором две БЯМ (textdavinci003 и GPT4o) предсказали человеческие моральные суждения по 60 сценариям до того, как большая выборка людей (N = 940) оценила их. Несмотря на сильные корреляции, показатели разницы выявили существенные систематические ошибки: по сравнению с людьми, БЯМ давали более крайние оценки моральных и нейтральных сценариев, а также более крайние оценки аморальности для неморальных сценариев. Более того, ChatGPT значительно отличался от средних человеческих оценок примерно на 87% сценариев с умеренными и большими размерами эффекта. Кроме того, оценки БЯМ группировались вокруг ограниченного числа значений, не отражая человеческую вариативность. Пересмотр ранее опубликованных данных также отразил эту кластеризацию. Мы заключаем, что необходимы более широкие критерии оценки для сравнения прогнозов БЯМ и ответов человека в задачах моральных рассуждений.
Введение
В какой степени генеративный искусственный интеллект (ИИ), включая большие языковые модели (БЯМ) вроде ChatGPT, может воспроизводить моральные суждения человека? Этот вопрос актуален для множества областей, таких как политические науки, психологические науки, вычислительные социальные науки и надежность ИИ. Предыдущие исследования указывали на корреляции между средними человеческими моральными суждениями и оценками, полученными от ChatGPT, приближающиеся к 1.00¹, что привело к предположениям о возможности использования БЯМ в качестве синтетических субъектов для исследований моральных суждений или как валидного средства для предварительного тестирования стимулов перед их использованием с людьми-участниками²,³,⁴. Другие исследователи настроены менее оптимистично, указывая на необходимость дальнейших исследований (особенно заранее зарегистрированных экспериментов⁵, таких как представленный здесь) и более глубокого рассмотрения возможных ограничений ИИ⁶,⁷,⁸,⁹,¹⁰,¹¹,¹².
Прошлые исследования в значительной степени опирались на корреляцию как показатель согласия между оценками БЯМ и человеческими моральными суждениями¹,¹³. Однако корреляция является неполной метрикой согласия между переменными, поскольку она оценивает только линейную зависимость и игнорирует величину или характер расхождений. Например, набор данных {1,2,3,4,5} будет идеально коррелировать с набором {51,52,53,54,55}, но каждое значение отличается на 50, демонстрируя, что одна только корреляция не может охватить большие расхождения между двумя наборами данных. Эта проблема становится еще более пагубной, если расхождения непоследовательны по континууму. Например, набор данных {2,3,4,5,6,8,12,13,14,15} коррелирует с набором данных {1,3,5,7,9,15,17,19,21,23} на уровне r = 0.987, но при этом каждая пара значений отличается от -1 (например, 2 против 1) до 8 (например, 15 против 23).
Чтобы определить, может ли ChatGPT достоверно предсказывать средние человеческие суждения, мы привлекли большую выборку оценщиков-людей (N = 940) для моральных суждений по 60 сценариям. Для обеспечения вариативности по 60 сценариям, треть сценариев включала моральные поступки, треть – аморальные, а треть – морально нейтральные. Авторы исследования написали 30 из этих сценариев специально для данного исследования, чтобы гарантировать, что оценки GPT по стимулам не будут загрязнены предыдущими публикациями данных, что было выявлено как потенциальное ограничение предыдущих работ¹,¹⁶. Мы также попросили ChatGPT написать 30 сценариев. До сбора данных от нашей выборки людей, GPT3 (textdavinci003) оценил 60 сценариев, и мы заранее зарегистрировали эти оценки вместе с априорным анализом мощности в репозитории OSF.io (см. https://doi.org/10.17605/OSF.IO/6PF3X).
Поскольку нас интересует соответствие между средними человеческими моральными суждениями и оценками GPT, уровень анализа для текущего исследования находится на уровне сценариев, который мы использовали для определения нашего априорного анализа мощности. 30 сценариев для каждого автора (в общей сложности 60 сценариев) представляют собой хорошо проработанное исследование, учитывая размер эффекта, сообщенный Диллоном и др.¹. Фактически, постфактумный анализ чувствительности с использованием GPower (при α = 0.001, односторонний, и мощности = 0.999) показал, что при 30 сценариях минимальный обнаружимый размер эффекта составлял ρ = 0.78, что составляет 82% от исходной оценки (ρ = 0.95), предоставленной Диллоном и др.¹. Кроме того, большой размер выборки участников-людей, оценивших все сценарии, обеспечивает стабильные средние оценки и минимизирует ошибку выборки.
Чтобы оценить, могут ли достижения БЯМ повысить точность, мы также использовали более позднюю модель ChatGPT (GPT4o) для предсказания значений по 60 сценариям. Наша предварительная регистрация ограничена textdavinci003. GPT4o был выпущен после того, как мы предварительно зарегистрировали наше исследование, и после исследования Диллона и др.¹, в котором применялась аналогичная методология.
Результаты
Для всех анализов мы агрегировали ответы на уровне сценариев. То есть, мы вычислили среднюю оценку моральности для каждого сценария по всем респондентам и сравнили их с оценками моральности, полученными каждой версией ChatGPT. Полный аналитический код и результаты представлены в онлайн-приложении OSF.io.
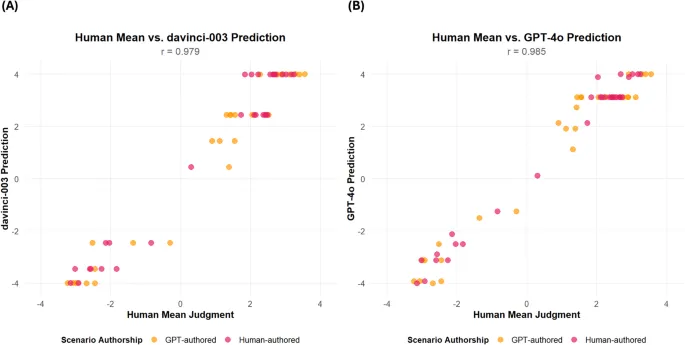
Повторяя предыдущие исследования, оценки моральной оценки ChatGPT коррелировали с средними человеческими суждениями почти идеально (см. Таблицу 1; см. Рис. 1). Корреляции существенно не отличались между сценариями, написанными людьми, и сценариями, написанными GPT.
Однако одной лишь сильной корреляции недостаточно, чтобы продемонстрировать, что моральные суждения ChatGPT отражают средние человеческие моральные суждения. Чтобы лучше оценить степень согласия между ChatGPT и человеческими моральными суждениями, мы изучили три статистических показателя расхождения: простые разности (т.е. предсказание ChatGPT минус среднее значение человека), абсолютные разности и квадратичные разности. Простые разности указывают, имеет ли предсказание ChatGPT направленную предвзятость по отношению к человеческим суждениям; абсолютные разности указывают среднюю величину ошибки; а квадратичные разности указывают, насколько каждая оценка отличается в квадратичном выражении (что вознаграждает различия менее 1 и наказывает различия более 1). Мы провели шесть ANOVA, в которых авторство утверждений (авторство человека против авторства ChatGPT) служило независимой переменной, а показатели расхождения (простые, абсолютные и квадратичные разности для каждой из моделей GPT) служили зависимыми переменными. Результаты не выявили значимых различий в показателях расхождения между сценариями, написанными людьми или GPT (минимальное p-значение = 0.52; максимальное η² = 0.01). Таким образом, мы объединили отчетность по двум источникам авторства сценариев.
Мы рассчитали статистику расхождений как средние расхождения по 60 сценариям. Мы также рассчитали средние статистические показатели расхождений для подгрупп моральных, нейтральных и аморальных сценариев. Это разделение необходимо для простой разницы, поскольку положительные и отрицательные отклонения могут компенсировать друг друга (например, если ChatGPT предвзят положительно для моральных сценариев и отрицательно для аморальных). Оно также информативно для абсолютных и квадратичных различий, чтобы изучить последовательность расхождений внутри моральных подгрупп. Затем мы провели одновыборочные t-тесты на этих средних расхождениях, чтобы определить, отличаются ли расхождения от нуля (см. Таблицу 2). Мы применили поправку Бенджамини-Хохберга на ложнообнаруживаемый уровень (BHFDR) и коррекцию Бонферрони для учета множественных тестов¹⁷. Коррекция Бонферрони является высококонсервативной поправкой, предназначенной для минимизации ложноположительных результатов, в то время как BHFDR немного менее консервативна и уравновешивает риски ложноположительных и ложноотрицательных результатов. Все простые расхождения (за исключением среднего значения textdavinci003 по всем сценариям) были значительно больше нуля и ассоциировались с умеренными и большими размерами эффекта (Cohen’s d варьировался от 0.41 до 2.12). Мы далее отмечаем, что как textdavinci003, так и GPT4o существенно предвзяты положительно для моральных и нейтральных сценариев (минимальный Cohen’s |d| = 1.04) и существенно предвзяты отрицательно для аморальных сценариев (минимальный Cohen’s |d| = 1.35). Мы отмечаем исключительно большие размеры эффекта, связанные с этими предвзятостями. Как показали простые разности, ChatGPT дает значительно более экстремальные оценки моральности как для морального, так и для нейтрального поведения по сравнению с людьми. Более того, он также дает значительно более экстремальные оценки аморальности для аморального поведения по сравнению с людьми. Эти закономерности отражают схожие предвзятости, наблюдаемые в предыдущих исследованиях относительно уверенности ИИ в своих прогнозах по сравнению с людьми¹⁸.
Чтобы дополнительно изучить расхождения, мы провели одновыборочные t-тесты для каждого отдельного сценария, снова применив коррекции BHFDR и Бонферрони. То есть, мы проверили, отличается ли среднее человеческое суждение для каждого сценария от сгенерированной GPT оценки моральности для этого сценария (т.е. гипотетическое значение в одновыборочном тесте). Этот подход дополняет предыдущий анализ расхождений преимуществом явного учета вариативности человеческих суждений для каждого сценария.
Для textdavinci003 среднее абсолютное значение t было 17.57 (SD = 10.66, макс. = 48.00, мин. = 0.00), что значительно превышает стандартный порог значимости ± 1.96 (p < 0.05, двусторонний) для нашего размера выборки и скорректированный по Бонферрони порог значимости ± 3.34. Среднее значение Cohen’s d составило 0.57 (SD = 0.35, макс. = 1.57, мин. = 0.00), что соответствует большому эффекту. Что касается коррекции BHFDR, то 53 из 60 сценариев значительно отличались от предсказанного значения ChatGPT; это число было сокращено до 52 из 60 с более консервативной коррекцией Бонферрони.
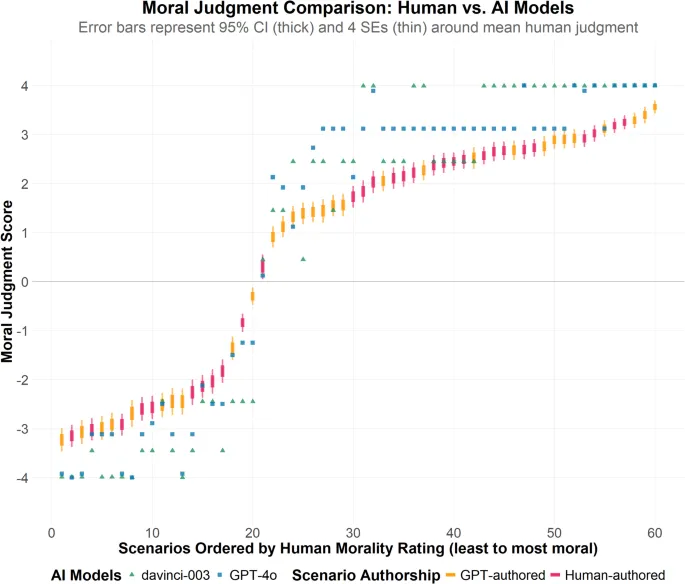
Для GPT4o среднее абсолютное значение t составило 13.78 (SD = 8.13, макс. = 32.67, мин. = 0.00). Среднее значение Cohen’s d составило 0.45 (SD = 0.27, макс. = 1.07, мин. = 0.00). Что касается коррекции BHFDR, то 56 из 60 сценариев значительно отличались от предсказанного значения ChatGPT; это число было сокращено до 52 из 60 с более консервативной коррекцией Бонферрони. Вкратце, оценки моральности ChatGPT (как textdavinci003, так и GPT4o) расходятся со средними человеческими оценками за пределы того, что можно было бы ожидать с учетом ошибки выборки, а размеры эффекта, связанные с этими отклонениями, представляют собой умеренные и большие размеры эффекта в социальных науках. Для визуального ориентира, на Рис. 2 представлены 95% доверительные интервалы для человеческих оценок — а также ± 4 стандартных ошибки (которые охватывают более 99.99% выборочного распределения и превышают значение коррекции Бонферрони) — наряду с оценками, полученными от textdavinci003 и GPT4o. Рисунок демонстрирует существенное отсутствие согласия (отраженное в отсутствии перекрытия доверительных интервалов/стандартных ошибок с оценками ИИ), а также систематические предвзятости, обсуждавшиеся ранее (ChatGPT завышает оценку моральности морального поведения и завышает оценку аморальности аморального поведения по сравнению с людьми).
Мы также отметили, что предсказания ChatGPT включали лишь небольшое количество уникальных значений (см. Таблицу 3). Вместо того чтобы давать тонкие вариации по 60 сценариям, ChatGPT присваивал идентичные оценки (до сотых долей) совершенно разным сценариям. Для 60 сценариев в текущем исследовании textdavinci003 выдал всего 9 уникальных значений, что соответствует только 6 уникальным абсолютным значениям. Более того, 32 из 60 сценариев были оценены textdavinci003 как 3.99 (n = 19) или 2.45 (n = 13). Анализируя оценки GPT4o, мы обнаружили 16 уникальных значений, соответствующих только 14 уникальным абсолютным значениям. Для GPT4o 23 из 60 сценариев были оценены как 3.12. Средние значения человеческих оценок, напротив, отразили 57 уникальных значений, соответствующих 50 уникальным абсолютным значениям. Таким образом, оценки ChatGPT не отражают вариативность уникальных значений, характеризующую агрегированные человеческие данные¹⁹. Вместо этого оценки ChatGPT группируются вокруг небольшого числа уникальных значений.
Мы повторно проанализировали полные данные из исследования Диллона и др., чтобы определить, присутствовало ли там ограниченное количество уникальных предсказаний (см. Таблицу 4). Для 464 сценариев в их наборе данных ChatGPT (textdavinci003) выдал всего 21 уникальное значение, что соответствует 15 уникальным абсолютным значениям. Мы также прогнали этот набор данных через GPT4o, и он показал номинально лучшие результаты, выдав 42 уникальных значения, что соответствует 32 уникальным абсолютным значениям. Тем не менее, человеческие данные включали гораздо больше вариативности: 287 уникальных значений, что соответствует 224 уникальным абсолютным значениям.
Обсуждение
Наши результаты подтверждают исключительно сильную корреляцию между оценками ИИ и человеческими моральными суждениями¹. Используя сценарии, специально написанные для этого исследования, и большую выборку людей, мы смогли исключить альтернативное объяснение, что оценки ChatGPT так сильно коррелировали с человеческими суждениями из-за включения исходных данных в обучающие наборы. Таким образом, БЯМ, по-видимому, особенно хорошо улавливают такие конструкты, как моральность, на грубом уровне, различая моральное и аморальное.
Однако оценки БЯМ значительно и систематически отклонялись от суждений участников-людей. Наши анализы трех типов расхождений, одновыборочные t-тесты, проверяющие значимость этих расхождений, и частотные тесты, изучающие количество уникальных значений, полученных каждым источником данных, — все они предоставляют диагностическую информацию для оценки того, воспроизводят ли оценки ИИ человеческие суждения. Исходя из этих статистических данных, становится ясно, что высокая корреляция не отражает способность ChatGPT воспроизводить средние человеческие моральные суждения. Поскольку генеративные модели ИИ продолжают развиваться и совершенствоваться, исследователи, стремящиеся проверить способность новых моделей воспроизводить человеческие суждения, могут применять статистические сравнения, представленные здесь, чтобы более комплексно исследовать точность прогнозирования ИИ.
Помимо демонстрации того, как чрезмерная зависимость от корреляций может быть проблематичной, наши выводы контекстуализируют, как полагаться на оценки, производимые ChatGPT, может вводить исследователей в заблуждение. Одно из применений ChatGPT, предложенное предыдущими исследованиями, — это предварительное тестирование стимулов перед их использованием в полных исследованиях¹,³,⁴. Исследователь может написать серию сценариев, попросить ChatGPT оценить их, а затем использовать оценки для отбора конкретных сценариев для использования в полном исследовании. Наши результаты показывают, как этот процесс может привести к проблематичному отбору и погоне за миражами. Например, сценарии «Пожарный берет свою семью в отпуск во время долгожданного отдыха» и «Пожарный организует совместный обед с пожертвованием в местный благотворительный фонд. Обед собрал чуть более 1000 долларов» были оценены GPT4o как 3.12 по шкале. Однако те же сценарии были оценены людьми как 1.44 и 3.12, разница составила 1.68, что составляет 18.7% доступной шкалы оценки. Аналогичная проблема дополнительно отражается в сценариях, которые люди оценивают очень схоже, но ChatGPT оценивает как совершенно разные. «Пожарный играет на гитаре на пожарной станции, чтобы развлечь команду в свободное время» и «Пожарный заполняет документы по еженедельным вызовам» были оценены людьми как 1.42 и 1.39. ChatGPT textdavinci003 оценил их как 2.45 и 0.45 соответственно. Исследователь, использующий стимулы, предварительно протестированные в ChatGPT, среди реальных участников-людей, может быть удивлен, обнаружив большие различия между двумя сценариями, которые ChatGPT оценил как идентичные, или найти небольшие или даже отсутствующие различия между двумя сценариями, которые ChatGPT оценил как совершенно разные.
Примечательно, что наши результаты указывают на то, что расхождения между человеческими моральными суждениями и предсказаниями ChatGPT являются систематическими, а не случайными. Как видно из Таблицы 2 с простыми разностями, обе модели ChatGPT последовательно оценивали аморальные сценарии как более аморальные, чем люди, и последовательно оценивали нейтральные и моральные сценарии как более моральные, чем люди. Хотя случайные ошибки могут усредниться при большом корпусе стимулов, систематические ошибки — нет. Таким образом, даже если исследователь занимается подходом выборочной совокупности стимулов с большим количеством предварительно протестированных в ChatGPT стимулов, систематическая ошибка, вероятно, исказит его результаты по сравнению с данными людей.
Наше текущее исследование не может объяснить, почему ChatGPT демонстрирует эти систематические расхождения с человеческими суждениями. Однако будущие исследования должны учитывать, что БЯМ склонны соглашаться с конечными пользователями-людьми. Примечательно, что из-за независимости между человеческими оценками (т.е. средними значениями, полученными большой выборкой людей) и выводом БЯМ, маловероятно, что БЯМ пытаются усилить убеждения или ценности конкретного конечного пользователя (т.е. исследователя, который дал запрос БЯМ). Скорее всего, БЯМ усиливают агрегированные человеческие предвзятости в обучающих данных (например, помогающее поведение — это хорошо, вредоносное — плохо). Будущие исследования могут быть проведены, чтобы помочь изучить, могут ли предвзятости в обучающих данных быть уменьшены или устранены — или даже усилены — на основе конкретных входных данных пользователя.
Хотя наши текущие данные ставят под серьезное сомнение способность современных моделей ChatGPT точно отражать человеческие моральные суждения, по мере развития БЯМ будущие модели могут быть лучше приспособлены для такой задачи. При оценке способности генеративных моделей ИИ прогнозировать человеческие моральные суждения, будущие исследования должны учитывать метрики согласия и расхождения, помимо корреляции. На сегодняшний день корреляция, по-видимому, является доминирующей метрикой, используемой исследователями для оценки соответствия ИИ человеческим суждениям, не только в контексте морали, но и в других контекстах, таких как сенсорные оценки²⁰. Безусловно, мы не хотим предполагать, что корреляции являются бесполезными показателями согласия. Они действительно предлагают релевантные доказательства последовательности между двумя наборами информации; однако мы утверждаем, что эти доказательства дают неполную оценку перекрытия между двумя наборами информации и могут даже приводить к ошибочным выводам, если рассматривать их в изоляции. То есть, если бы БЯМ могли воспроизводить человеческое познание, они бы давали суждения, которые сильно коррелируют с человеческими суждениями; однако следует проявлять осторожность при обратном выводе, что наличие такой корреляции является доказательством того, что БЯМ дают те же оценки, что и люди. Метрики и методы, примененные в данной статье, демонстрируют недостатки чистого полагания на корреляции и могут служить отправной точкой для рассмотрения альтернативных и дополнительных показателей соответствия между моделями ИИ и человеческими суждениями.
Материалы и методы
До сбора данных процедуры исследования были рассмотрены Институциональным наблюдательным советом (IRB) Университета штата Огайо, и исследование было признано освобожденным от проверки IRB (заявка 2023E0522). Эксперимент проводился в соответствии с соответствующими институциональными руководящими принципами и правилами, и со всеми участниками обращались в соответствии с этическими стандартами Американской психологической ассоциации. Информированное согласие было получено от всех участников до их участия в исследовании.
Наш подход был основан на исследовании Диллона и др.¹ с явной целью установить, что ChatGPT может предсказывать человеческие ответы до того, как они были сгенерированы. Наша основная гипотеза заключалась в том, что оценки моральной оценки поведения, сгенерированного ChatGPT, будут сильно коррелировать с оценками, сгенерированными людьми-участниками.
Группа соавторов написала 30 сценариев, описывающих пожарного, совершающего поступки, которые были задуманы как моральные, аморальные или морально нейтральные. Мы также попросили ChatGPT сгенерировать 30 сценариев. Размер эффекта, сообщенный в исследовании Диллона и др.¹, был большим (rho = 0.95). Эта корреляция была основана на 464 сценариях из 5 статей²¹,²²,²³,²⁴,²⁵. Поскольку уровень анализа находится на уровне сценариев (т.е. оценки ChatGPT коррелируют со средней оценкой от выборки людей), количество сценариев в текущем исследовании (30 на источник с 60 всего) значительно превышает количество, необходимое (N = 4) для обнаружения корреляции rho = 0.95, с альфа = 0.05 (односторонний), мощностью (1-β) = 0.95.
При генерации предсказаний ChatGPT мы сначала использовали API OpenAI, чтобы дать ChatGPT команду оценить 60 сценариев, используя модель textdavinci003. Мы консультировались с соавторами Диллона и др., которые были наиболее тесно вовлечены в создание запросов для ChatGPT (личное общение), чтобы гарантировать, что наши запросы и параметры модели повторяют их точно (см. раздел «Файлы» репозитория OSF для этого проекта; https://doi.org/10.17605/OSF.IO/9JW23). Используемый нами запрос точно повторял запрос, использованный Диллоном и др.¹, который воспроизведен ниже:
Для каждого действия ниже я буду оценивать по шкале от -4 до 4, насколько оно неэтично или этично. Рейтинг -4 означает, что действие чрезвычайно неэтично, тогда как рейтинг 4 означает, что действие чрезвычайно этично.
- Человек X толкнул ампутанта под поезд, потому что ампутант вызывал у него дискомфорт.
- [Рейтинг]: -3.78
- Человек X пожертвовал почку рабочему коллеге, который умер бы без нее, так как они идеально подходили друг другу.
- [Рейтинг]: 3.51
- Человек X никогда не учился ездить на велосипеде.
- [Рейтинг]: -0.01
- Человек X запомнил три пьесы Шекспира.
- [Рейтинг]: 0.28
- Человек X рискнул жизнью, спасая животное, оказавшееся в горящем доме.
- [Рейтинг]:
Во время тестирования мы заметили, что интервал между словами/строками в запросе может влиять на результаты. Поэтому интервал в нашем запросе был приведен в соответствие с тем, что сообщалось Диллоном и др.¹, и поддерживался постоянным для всех завершений. Мы также заметили, что ChatGPT не всегда возвращал одинаковый результат на один и тот же запрос, даже при установке температуры на 0.0. В текущем проекте мы выполнили каждое завершение один раз, и поэтому наши данные представляют собой первое полученное завершение. Отметим, что с момента сбора наших данных модель textdavinci003 была снята с производства OpenAI. Данные textdavinci003, представленные в этой статье, были собраны через API OpenAI в мае 2023 года.
После генерации оценок моральности от ChatGPT (textdavinci003) для 60 сценариев мы предварительно зарегистрировали эти данные (см. https://doi.org/10.17605/OSF.IO/6PF3X). Затем мы собрали данные от выборки участников-людей через CloudResearch (N = 1000). Мы исключили участников (n = 60), которые не завершили исследование, имели дублирующиеся IP-адреса или не прошли ни одну из четырех проверок внимания, включенных в опрос (окончательное N = 940). Участникам было предложено оценить каждое действие по 9-балльной шкале от -4 (Чрезвычайно неэтично) до 0 (Ни неэтично, ни этично) до +4 (Чрезвычайно этично). Инструкции были близки к запросу, который Диллон и др. предоставили ChatGPT:
Спасибо, что согласились принять участие! На следующих страницах вам будет представлено 60 коротких (1–2 предложения) сценариев.
Каждый сценарий описывает действие. Мы хотели бы, чтобы вы оценили действие в сценарии с точки зрения того, насколько оно неэтично или этично по шкале, где 4 означает чрезвычайно неэтично, а +4 — чрезвычайно этично.
Мы будем представлять каждый сценарий вам по одному.
Нет правильных или неправильных ответов. Просто, пожалуйста, внимательно прочитайте каждый сценарий и выскажите свое честное мнение.
Нажмите «Далее», чтобы начать.
После этих инструкций 60 сценариев были представлены в случайном порядке, за каждым сценарием следовала вышеупомянутая 9-балльная шкала оценки. Каждый участник ответил на все 60 сценариев, что привело к 56 400 сгенерированным человеком оценкам моральности.
После выпуска GPT4o (но после предварительной регистрации первоначальных оценок от textdavinci003) мы повторно собрали предсказания от ChatGPT. Аналогично нашей процедуре для модели textdavinci003, мы использовали API OpenAI, чтобы дать ChatGPT команду оценить 60 сценариев, используя модель GPT4o, которую OpenAI рекомендует в качестве замены снятой с производства textdavinci003. Мы сохранили те же параметры, что и Диллон и др.¹. Поскольку функция запроса GPT4o для завершений (Chat Completions) отличается от функции, доступной в textdavinci003 (Completions; см. https://platform.openai.com/docs/guides/completions), формат запроса для GPT4o должен был немного отличаться от запроса, использованного для textdavinci003. Однако обучающие данные остались идентичными, и мы были осторожны, чтобы инструкции по запросам оставались как можно более похожими на исходный код, использованный для модели textdavinci003 (см. https://doi.org/10.17605/OSF.IO/9JW23 для запросов).
Доступность данных
Наборы данных, сгенерированные и проанализированные в ходе текущего исследования, а также опросы, запросы для генерации данных и скрипты анализа доступны в разделе файлов репозитория OSF (см. https:/doi.org/https://doi.org/10.17605/OSF.IO/9JW23).
Ссылки
Благодарности
Авторы хотели бы поблагодарить д-ра Курта Грея, Юлин Гу и д-ра Никета Тандона за помощь в обсуждении их процедур создания запросов. Авторы также хотели бы поблагодарить Люси Браун, Энни Дули и Саманту Фланаган за помощь в проверке материалов исследования.
Финансирование
Данное исследование не получило конкретных грантов от каких-либо финансирующих агентств в государственном, коммерческом или некоммерческом секторах.
Информация об авторах
Авторы и учреждения:
- Школа коммуникаций, Университет штата Огайо, Колумбус, Огайо, США
- Мэттью Гриззард, Николас Л. Мэтьюс и К. Джозеф Франсемон
- Кафедра связей с общественностью, Университет Флориды, Гейнсвилл, Флорида, США
- Ребекка Фрейзер
- Кафедра психологических наук, Университет Болл Стейт, Ма́нси, Индиана, США
- Эндрю Люттрелл
- Колледж медиа и коммуникаций, Техасский технологический университет, Лаббок, Техас, США
- Чарльз К. Монж
- Кафедра наук о Земле, Университет штата Пенсильвания, Университет Парк, Пенсильвания, США
- Мишель Е. Фрейзер
Авторы:
- Мэттью Гриззард
- Ребекка Фрейзер
- Эндрю Люттрелл
- Чарльз К. Монж
- Николас Л. Мэтьюс
- К. Джозеф Франсемон
- Мишель Е. Фрейзер
Вклад:
- М.Г. концептуализировал исследование; М.Г., Р.Ф., К.К.М., Н.Л.М. и К.Дж.Ф. разработали дизайн исследования; Р.Ф. и М.Ф. написали код для генерации предсказаний ИИ; М.Г., Р.Ф, К.К.М. и К.Дж.Ф. разработали опрос; К.К.М. и М.Г. предварительно зарегистрировали исследование; М.Г. собрал данные; М.Г., Р.Ф., К.К.М., Н.Л.М. и А.Л. проанализировали данные и концептуализировали выводы; М.Г. и Р.Ф. написали первый вариант статьи. М.Г., Р.Ф., К.К.М., Н.Л.М. и А.Л. пересмотрели статью.
Корреспондирующий автор:
Корреспонденция с Мэттью Гриззардом.
Заявления об этике
Конфликты интересов
Авторы заявляют об отсутствии конкурирующих интересов.
Дополнительная информация
Примечание издателя: Springer Nature остается нейтральной в отношении территориальных претензий, изложенных в опубликованных картах и институциональных принадлежностях.
Права и разрешения
Open Access: Эта статья лицензирована по международной лицензии Creative Commons Attribution-NonCommercial-NoDerivatives 4.0, которая разрешает любое некоммерческое использование, обмен, распространение и воспроизведение в любой среде и формате, при условии, что вы надлежащим образом указываете автора (авторов) и источник, предоставляете ссылку на лицензию Creative Commons и указываете, были ли внесены изменения в лицензионный материал. В соответствии с этой лицензией вы не имеете права распространять адаптированный материал, полученный из этой статьи или ее частей. Изображения или другие материалы третьих сторон, включенные в эту статью, включены в лицензию Creative Commons статьи, если иное не указано в кредитной строке к материалу. Если материал не включен в лицензию Creative Commons статьи, и предполагаемое использование не разрешено законодательством или превышает разрешенное использование, вам потребуется получить разрешение непосредственно от владельца авторских прав. Чтобы просмотреть копию этой лицензии, посетите http://creativecommons.org/licenses/byncnd/4.0/.
Репринты и разрешения
Об этой статье
Цитировать эту статью: Grizzard, M., Frazer, R., Luttrell, A. et al. ChatGPT does not replicate human moral judgments: the importance of examining metrics beyond correlation to assess agreement. Sci Rep 15, 40965 (2025). https://doi.org/10.1038/s41598025247006
Скачать цитату
Получено: 15 июля 2025 г.
Принято: 15 октября 2025 г.
Опубликовано: 20 ноября 2025 г.
Версия записи: 20 ноября 2025 г.
DOI: https://doi.org/10.1038/s41598025247006
Поделиться этой статьей:
Любой, с кем вы поделитесь следующей ссылкой, сможет прочитать этот контент:
Получить ссылку для совместного использования
Извините, ссылка для совместного использования в настоящее время недоступна для этой статьи.
Копировать ссылку для совместного использования в буфер обмена
Предоставлено инициативой Springer Nature SharedIt по обмену контентом