Интересное сегодня
Введение
Люди занимаются многими видами деятельности не только ради материального вознаграждения или практической выгоды, но и просто ради удовольствия и развлечения. От игр и просмотра фильмов до создания музыки — существует бесчисленное множество занятий, где поведение кажется внутренне мотивированным при отсутствии инструментальных преимуществ. При таком количестве доступных вариантов развлечений в любое время крайне важно понимать, какие занятия люди предпочитают и продолжают участвовать в них纯粹 ради удовольствия. Какие особенности влияют на то, будет ли текущая деятельность восприниматься как внутренне вознаграждающая и, следовательно, предсказывать continued engagement, особенно в богатых и реалистичных сценариях?
Теоретические основы
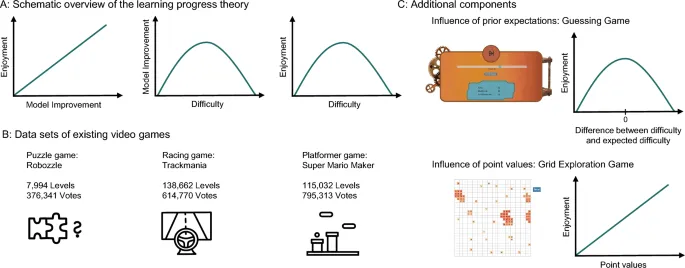
Внутренняя мотивация часто связывается с оптимальным уровнем сложности задачи. Многочисленные теории — основанные на таких факторах, как новизна, достижения или вызов — предполагают, что внутренняя мотивация достигает пика при задачах средней сложности (или знаний), что приводит к перевернутой U-образной зависимости между двумя переменными. Это явление наблюдалось в различных областях исследований, включая любопытство, скуку, поток, развитие и дизайн игр.
Теория прогресса обучения
Одна из теорий, формально описывающих «удовольствие» — или, более generally, внутреннее вознаграждение — основана на информационной цели прогресса обучения. Общая техника, используемая в робототехнике и машинном обучении, заключается в назначении внутренних вознаграждений за активное создание или обнаружение удивительных впечатлений, которые позволяют интеллектуальным агентам улучшать предсказания своей модели мира. Согласно этому подходу, субъективная мера «удовольствия» или внутреннего вознаграждения может быть определена как степень, в которой модель мира улучшается. Это снова создает перевернутую U-образную зависимость между сложностью и внутренним вознаграждением, с максимальным внутренним вознаграждением в ситуациях средней сложности (т.е. не слишком легких и не слишком сложных), где прогресс обучения максимален.
Методология исследования
Чтобы ответить на вопрос о факторах удовольствия, мы использовали несколько крупномасштабных наборов данных игр, а также два онлайн-эксперимента. В рамках трех крупномасштабных наборов данных видеоигр («Robozzle», «Trackmania» и «Super Mario Maker») мы использовали субъективные оценки как показатель внутреннего вознаграждения, обнаружив перевернутую U-образную зависимость между сложностью и удовольствием людей. Однако emerged и другие важные факторы.
Анализ игровых данных
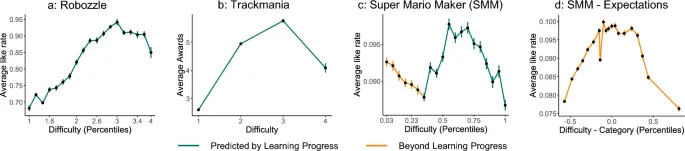
Robozzle — это головоломка, в которой игроки пишут небольшие, часто рекурсивные программы с помощью строительных блоков, чтобы направить космический корабль к цели. Набор данных состоял из 7,994 уровней и 376,341 голоса. Игроки могли оценить сложность каждого уровня от 1 до 5. Мы использовали средний рейтинг для каждого уровня, который отображался на сайте как значение от 1 (очень легко) до 5 (очень сложно) с шагом 0.01. Игроки также могли голосовать за уровни, что мы transformed в меру удовольствия, разделив голоса «за» на общее количество голосов, чтобы получить коэффициент симпатии. Анализ голосов показал, что игроки предпочитали уровни средней сложности очень легким или сложным.
Trackmania — это гоночная игра, в которой игроки управляют гоночным автомобилем на различных искусственных трассах. Набор данных состоял из 138,662 уровней и 614,770 голосов (здесь called awards). Сложность каждого уровня была указана сайтом как одна из четырех категорий: Beginner, Intermediate, Expert и Lunatic. Эти сложности были assigned создателями уровней. Мы mapped эти категории сложности к значениям 1–4. Игроки могли давать награды уровням, из которых мы использовали абсолютное число на уровень как приближение удовольствия. Снова игроки, казалось, liked уровни средней сложности больше, чем очень легкие или сложные.
Super Mario Maker — это платформерная видеоигра, в которой игроки должны переместить главного героя к цели, в основном прыгая, бегая и избегая врагов. В Super Mario Maker игроки могут создавать свои собственные уровни в стиле Super Mario и затем загружать их для других игроков, чтобы играть и оценивать их. Мы проанализировали данные 115,032 уровней, созданных игроками, и 795,313 голосов, основанных на общей сложности 32,665,615 попыток. Поскольку у нас были более подробные данные на уровень, нам не пришлось полагаться на оценки сложности игроков или создателя. Вместо этого мы approximated сложность каждого уровня как 1 минус отношение того, сколько игроков, attempted уровень, смогли его закончить. Игроки могли оценивать уровни звездами. Мы определили нашу меру удовольствия как долю игроков, attempted уровень, которые также дали звезду этому конкретному уровню. Как и в наших предыдущих экспериментах, мы found перевернутую U-образную связь между нашей мерой сложности и нашей мерой удовольствия.
Дополнительные факторы влияния
Более пристальный взгляд на данные Super Mario Maker suggests, что они не следуют квадратичной функции и better описываются полиномом третьей степени. Поэтому, хотя мы found перевернутую U-образную связь во всех трех наборах данных, набор данных Super Mario Maker, казалось, involved больше, чем просто предпочтение стимулов средней сложности. При взгляде только на lower сложности, казалось, что игроки предпочитали более простые уровни более сложным. Существует несколько возможных объяснений этого явления.
Несоответствие ожиданий сложности
Игроки могли быть influenced их prior ожиданиями о сложности уровня и тем, насколько хорошо он matched фактической сложности. В наборе данных Super Mario Maker каждый уровень был помещен в одну из четырех категорий сложности создателем. Эти категории не всегда matched нашим calculations сложности — определенным количеством игроков, manage очистить уровень. Мы looked at discrepancy между этими двумя оценками сложности, related разницу между calculated сложностью и expected сложностью — определенной категорией сложности — к средней rate симпатии. Мы observed перевернутую U-образную форму с пиком около 0. Игроки предпочитали уровни, в которых их ожидания matched нашей calculated мере сложности.
Влияние успеха
Вторая возможность для negative trend в первой половине набора данных Super Mario Maker might быть that игроки simply enjoy чувство успеха (например, решение уровня или получение higher вознаграждений) поверх прогресса в обучении — thereby предпочитая очень легкие уровни slightly более сложным. Влияние вознаграждений в видеоиграх на мотивацию было shown в предыдущей работе. Однако с данными из игровых наборов данных мы не able tease apart сложность и предпочтение успеха.
Контролируемые эксперименты
Все упомянутые данные originated из трех крупномасштабных наборов данных popular существующих игр. Хотя это provided нас с большим количеством данных на уровень, у нас был limited доступ к данным на игрока. Поэтому мы не able further изучать дополнительные гипотезы — т.е. влияние disparity ожиданий сложности или влияние успеха. Вместо этого мы решили разработать два контролируемых и gamified эксперимента, в которых мы can собрать все необходимые данные, провести более detailed анализы и точно simulate прогресс обучения.
Эксперимент 1: Игра в угадывание
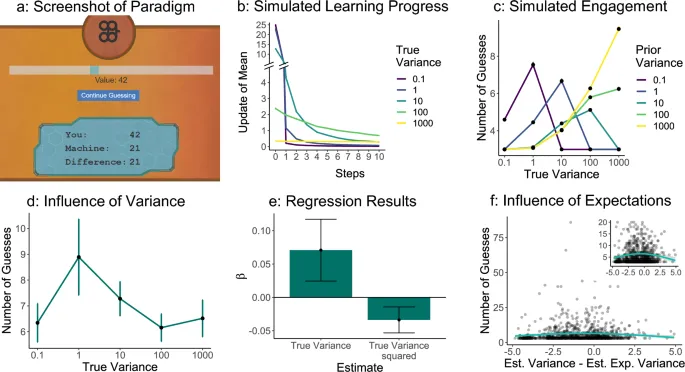
Чтобы проверить влияние прогресса обучения на вовлеченность в простой setting, мы developed игру в угадывание, в которой игроки guessed числа из Gaussian распределений с different дисперсиями. Эта простая задача имеет два основных advantages по сравнению с вышепроанализированными игровыми наборами данных: Во-первых, она позволяет нам implement рациональную модель и thereby derive более конкретные предсказания. Во-вторых, она minimizes эффект prior уровня навыков игроков, поскольку сложность определяется randomness среды. Хотя задача напоминала классические психологические парадигмы, мы maintained идею использования игр как research платформы, давая игрокам только base оплату и не компенсируя производительность. Additionally, мы дали игрокам option не взаимодействовать с задачей, while still получая их base компенсацию. Thereby, мы still assessed удовольствие, rather than инструментальный сбор информации.
Эксперимент 2: Игра исследования
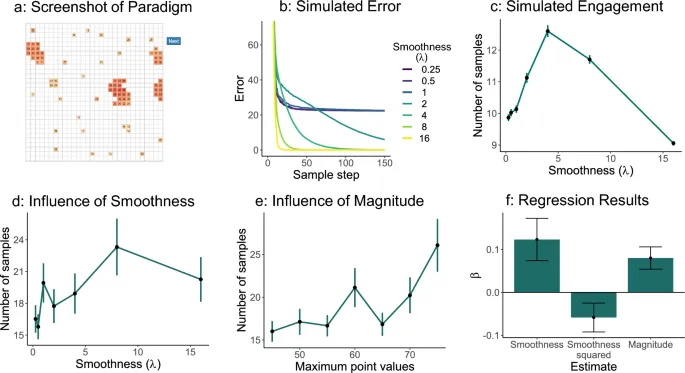
Люди, казалось, принимают во внимание прогресс обучения и disparity ожиданий сложности, когда решают, как долго взаимодействовать с каждым распределением в игре угадывания. Однако, как мы saw в наборе данных Super Mario Maker, игроки might также мотивированы simply предпочтением успеха. Мы believe, что игроки предпочитают взаимодействовать со средами, которые offer higher значения вознаграждения, even если они не cumulative и игроки не instructed или compensated чтобы делать это. В идеале мы wanted проверить влияние этого additional компонента во втором эксперименте, в котором мы could различать влияние сложности и влияние uncompensated вознаграждений на поведение игроков. Moreover, мы wanted расширить наши initial наблюдения на another setting, в котором прогресс обучения could быть directly manipulated. Таким образом, мы решили использовать additional парадигму для нашего второго эксперимента — игру исследования сетки. В этой игре — основанной на парадигме поиска сетки, developed Ву и др. — мы could not only manipulate сложность среды, но и ее значения очков, independent друг от друга. Additionally, этот setting был somewhat богаче, чем original игра в угадывание, thereby further закрывая gap между lab экспериментами и играми.
Результаты экспериментов
В эксперименте 1 мы used данные 98 участников, собранные через Amazon Mechanical Turk. Участники played в среднем с 14 машинами, сделали в среднем 77 guesses в общей сложности и 8 guesses на машину. Мы found, что с increasing дисперсией средняя разница между guesses и numbers, produced машиной, increased, в то время как число correct guesses decreased, как и ожидалось. Мы examined, whether обновления guess участников diminished со временем, означая сходимость в их guesses. Это would указать на прогресс в угадывании numbers, generated машинами. Мы выполнили regression анализ, используя scaled обновление — абсолютную разницу между текущим и последним guess — и included случайный intercept для каждого участника. Мы found, что номер текущего trial имел significant negative эффект на размер текущего обновления: обновления игроков became smaller со временем для каждой машины, indicating, что они сошлись на number чтобы guess.
Мы assessed, whether игроки acted как predicted гипотезой прогресса обучения — и другими перевернутыми U-образными теориями — в этой контролируемой среде, investigated связь между дисперсией и вовлеченностью, measured количеством guesses, которые участники made с каждой машиной. Согласно нашим simulations и original теории, игроки should engage больше всего со средами с intermediate дисперсией. Мы first построили среднее число interactions по дисперсиям и участникам. Мы saw, что люди showed перевернутую U-образную связь и engaged больше всего с машинами дисперсии 1. Чтобы подтвердить этот результат, мы выполнили negative binomial mixed-effects regression анализ, including дисперсию и squared дисперсию как components while adding случайный intercept для каждого участника. Мы found, что linear компонент имел significant positive эффект, в то время как squared компонент имел significant negative эффект, что indicated обратную U-образную форму. Следовательно, участники engaged больше всего с intermediate дисперсиями.
Обсуждение
Мы изучали влияние сложности на внутреннюю мотивацию — с particular focus на теории прогресса обучения — в inherently приятных средах, основанных на трех крупномасштабных наборах данных игр и двух контролируемых экспериментах. В трех видеоиграх (головоломка, гоночная игра и платформер) мы found, что оценки игроков depended от сложности уровня, как predicted диапазоном перевернутых U-образных теорий. С нормативной perspective, средняя сложность led к наибольшему прогрессу обучения, который в turn led к higher оценкам (indicating increased удовольствие), которые мы were able проверить в естественно приятных и engaging игровых settings. В наборе данных Super Mario Maker мы observed два additional фактора, которые также influenced оценки: i) disparity ожиданий сложности между prior ожиданиями сложности и нашими calculations сложности на основе success ratio задачи и ii) эффект успеха в легких уровнях. Через два точно контролируемых эксперимента — игра в угадывание и игра исследования сетки — мы confirmed, что оба этих additional компонента influenced вовлеченность игроков beyond влияние прогресса обучения.
Ограничения и будущие направления
Мы начинаем эту статью, arguing, что мы want понять experience людей «удовольствия» или «наслаждения». Однако точная природа этих concepts debated. Например, Блайт и Хассензал define «удовольствие» как подмножество наслаждения и contrast это с «удовольствием». Они argue, что удовольствие более тривиально и кратковременно, в то время как удовольствие concerned с relevance и идентичностью. Другая работа в психологии использует термин удовольствие более generally для приятных experiences, в то время как другая работа описывает similar concepts как «мгновенное субъективное благополучие» или «мгновенное счастье». В своей работе по прогрессу обучения Удейер и др. используют термин «внутреннее вознаграждение» как зависимую переменную в их теории. Это связано с литературой по внутренней мотивации, которая suggests, что certain свойства сред, такие как новизна или неожиданность, могут быть внутренне вознаграждающими для агентов. В нашей работе мы aim описать и понять positive affect, associated с внутренне мотивирующими парадигмами, такими как игры. Чтобы сделать это, мы используем термины «наслаждение» или «внутреннее вознаграждение» как appropriate. Таким образом, while Шмидхубер использует выражение «удовольствие», мы не claim, что это единственный appropriate термин для ссылки на researched concept.
Заключение
Мы исследовали связь между сложностью и внутренним вознаграждением в трех богато структурированных, крупномасштабных наборах данных игр и двух простых экспериментах, которые focus на удовольствии, rather than обучении. Мы found, что — как predicted многочисленными перевернутыми U-образными теориями, такими как прогресс обучения — игроки предпочитали среды средней сложности. Кроме того, мы found в одном из игровых наборов данных, а также в двух highly контролируемых экспериментах и detailed simulations, что disparity ожиданий сложности, а также чувство успеха additionally influenced удовольствие. Эти результаты обогащают наше понимание динамики удовольствия в реалистичных средах и подчеркивают важность использования как реалистичных, подобных играм сред, так и highly контролируемых экспериментов вместе с detailed simulations для продвижения теорий человеческого обучения и принятия решений.