Интересное сегодня
Эффективность программ поддержки психического здоровья для с...
Профессиональный стресс у сотрудников исправительных учрежденийСотрудники исправительных учреждений ...
Надежные методы статистического вывода для общей линейной мо...
Введение Современные исследователи в области психологии и социальных наук часто сталкиваются с пробл...
Биндж-этинг у детей и подростков: причины, развитие и роль с...
Теоретическая основа Биндж-этинг характеризуется потреблением большого количества пищи за ограниченн...
Доверие к качественным данным: критерии и методы обеспечения...
Доверие к качественным данным в исследованиях Доверие в качественных исследованиях аналогично концеп...
Как музыкальное обучение развивает моторику у детей: роль чу...
Введение: связь ритма, музыки и моторных функций Ритм является фундаментальным компонентом человечес...
Дофамин и терпение: новое исследование раскрывает связь
Дофамин: ключ к терпению и самоконтролю? Новаторское исследование, проведенное командой из Унив...
Слух — одно из первых развивающихся чувств, и к моменту рождения он уже достаточно зрелый. Современные теории предполагают, что мозг использует закономерности в звуках для создания внутренних моделей окружающей среды. Посредством статистического обучения эти внутренние модели экстраполируют паттерны, чтобы делать предсказания относительно последующего опыта. У взрослых измененные реакции мозга на звук позволяют нам судить о существовании и свойствах этих моделей. В данном исследовании с помощью мозговых потенциалов определялось, демонстрируют ли новорожденные контекстно-зависимые модуляции мозговой реакции, которые можно использовать для выявления существования и свойств внутренних моделей. Результаты указывают на значительную контекстную зависимость в реакциях на звук у новорожденных. Когда обычные и редкие звуки с постоянной вероятностью продолжаются в течение очень длительного периода, новорожденные реагируют на все звуки одинаково (без дифференциации). Однако, когда те же обычные и редкие звуки с той же вероятностью чередуются во времени, реакции новорожденных показывают четкие различия. Эта контекстная зависимость согласуется с предположением, что мозг новорожденного создает более точные внутренние модели, которые различают контексты, когда есть emergent (возникающая) структура для обнаружения, но, по-видимому, использует более широкие модели, когда дифференциация дает мало или никакой дополнительной информации об окружающей среде.
Введение
Слух — одно из самых ранних созревающих чувств. Развивающийся плод способен воспринимать звук уже с 18-й недели беременности1. К моменту появления на свет новый человек уже имеет значительный опыт обработки звуковой информации2. Известно, что новорожденные могут узнавать знакомые голоса с рождения или даже раньше3,4, локализовать источники звука5 и даже разделять одновременные звуковые источники6. Однако меньше известно о том, как звук обрабатывается в контексте на ранних стадиях развития мозга. Данное исследование было разработано с целью расширить наши знания о том, как мозг новорожденного использует звуковую информацию в структурированных последовательностях.
Запись слуховых событийных вызванных потенциалов (event-related potentials, ERP) в этом исследовании использует методологию, которая применима к новорожденным так же, как и к взрослым7. Электроды размещаются на поверхности кожи головы, в то время как предъявляется структурированная последовательность звуков. Эта методология дала представление о статистическом обучении у новорожденных, которое позволяет извлекать абстрактные паттерны, необходимые для обучения музыке и языку8,9,10. Для звуковых последовательностей с предсказуемой структурой, с увеличением экспозиции, мозг становится менее чувствительным к предсказуемым событиям и более чувствительным к событиям, которые не соответствуют ожиданиям11. Это отражается в ответах ERP. Способность различать реакции на предсказуемые и нарушающие предсказание звуки, следовательно, может быть использована для вывода существования внутренних моделей окружающей среды, представляющих предсказание или вывод о сенсорном вводе, который, скорее всего, будет получен далее11,12,13. Эта методология идеально подходит для использования у новорожденных, поскольку процесс происходит автоматически и не требует выполнения задачи или явного внимания6,7,14-21.
У взрослых амплитуда ответа на звуки, нарушающие установленные паттерны, предположительно отражает сигнал, взвешенный по точности (precision-weighted signal), на который влияет степень достоверности доказательств, на которых построена внутренняя модель (например, стабильность и надежность паттерна22,23). Значительный объем исследований относит взвешивание по точности к усилению выходных сигналов от определенных популяций клеток в чувствительных корковых областях (а именно, поверхностных пирамидных клеток), признавая, что это отражает взаимодействие иерархической сети как внутри, так и между областями мозга. Другими словами, кажущийся простым индикатор обнаружения отклонений подкрепляется сложным итеративным процессом вывода, который работает на многих различных временных масштабах23-27. Внутри регистрируемых скальповых ответов этот процесс связан с изменениями во времени нескольких компонентов слухового ERP28. У взрослых ключевое различие между совпадающими с паттерном и не совпадающими звуками возникает в течение 100–250 мс после точки отклонения и максимально регистрируется над фронтоцентральными электродными участками при использовании носового или сосцевидного референса. Эта «чувствительность к несоответствию» (mismatch negativity, MMN) улавливается в разностной форме, но в тональных ответах она часто перекрывает ранние компоненты, известные как N1 и P2, и считается частью комплекса N229-31. Взвешивание по точности может быть рассмотрено как изменения в реакции на совпадающие с паттерном звуки, которые становятся менее отрицательными с повторением и стабильностью паттерна во времени, и в реакции на несоответствие, которая становится более отрицательной в течение этого периода.
Хотя морфология ERP быстро меняется в течение первого года жизни, и стабильные компоненты взрослого состояния появляются только в детстве, признаки ERP обнаружения слуховых отклонений присутствуют с самого рождения32. Неонатальная структура ERP-ответа, связанного с отклонением (полученная путем вычитания ответа на регулярные звуки из ответа на нерегулярные), обычно характеризуется положительной волной, появляющейся через 200–400 мс с момента отклонения (называемой mismatch response, MMR33), которая может быть окружена ранним и поздним отрицательными отличиями, в зависимости от акустических свойств стимулов, объема и типа разделения между регулярными и нерегулярными звуками и т. д.34. Хотя изначально это считалось индикатором вероятности29,30, процесс несоответствия показывает чувствительность к нарушениям установленных звуковых переходов27,35,36, требуя более контекстуализированной формы обучения. Этот тип статистического обучения включает извлечение закономерностей в том, как признаки и объекты сосуществуют в окружающей среде в пространстве и времени. Важно отметить, что предыдущие исследования показали, что свойства инфантильного электрического ответа мозга на слуховое отклонение предполагают, что он отражает ошибку предсказания37, аналогично аналоговому ответу у взрослых38. Инфантильный MMR-ответ вызывается как нарушением закономерностей, основанных на отдельных звуках, так и на коротких звуковых паттернах39, что ставит вопрос о том, что, опять же, аналогично взрослым40, они могут также отражать крупномасштабную структуру слухового контекста.
Данное исследование было разработано для того, чтобы определить, может ли дифференциальное взвешивание по точности, основанное на крупномасштабной структуре, наблюдаемой у взрослых41-44, также наблюдаться у новорожденных. Здесь мы предоставляем доказательства того, что мозг новорожденных младенцев действительно может формировать внутренние модели, которые различают звуки на основе вероятности и взвешивают этот ответ на основе точности, но склонность к этому зависит от контекстуальных факторов, которые могут быть связаны с определением предполагаемой ценности отслеживания информации во времени. Дифференциальные ответы на звук могут возникать только тогда, когда звук предоставляет информацию о более долгосрочных структурах в окружающей среде. Таким образом, одна и та же акустическая дифференциация может автоматически происходить или нет, в зависимости от ее актуальности для выявления важной информации о контексте.
Результаты
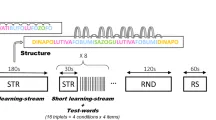
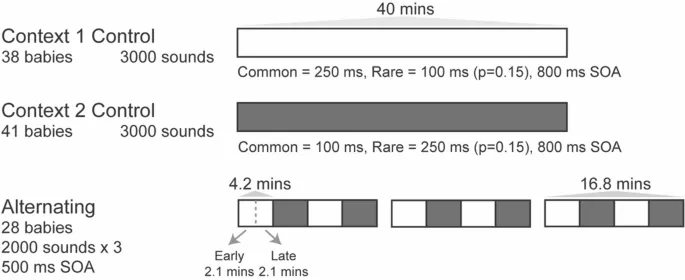
Исследование включало три эксперимента с тремя отдельными группами новорожденных с дизайном звуковой последовательности, представленным на рис. 1. В первых двух экспериментах последовательности, услышанные младенцами, содержали всего два звука: длинный тон (250 мс) и более короткий тон (100 мс), оба из которых состояли из наложения частот 500 Гц, 1000 Гц и 1500 Гц. Звуки были организованы по традиционному «нечетному» дизайну (oddball)11, таким образом, что два звука воспроизводились с существенно разными вероятностями (длинный p = 0.85 и короткий p = 0.15 соответственно). Эксперимент 1 далее именуется контролем контекста 1. Другая группа новорожденных слышала аналогичные последовательности, но с обратными вероятностями звуков (Эксперимент 2), что далее именуется контролем контекста 2. Когда взрослые слышат такие последовательности, ответы на обычные и редкие тоны различаются, так что ответ становится более «подавленным» или более положительным во фронтоцентральных участках скальпа с увеличением экспозиции, и «более сильным» или более отрицательным при редких отклонениях11. Стабильные последовательности такого типа также считаются идеальными для формирования точных внутренних моделей и были разработаны на основе последовательностей, для которых ранее наблюдались зависимые от вероятности ответы у новорожденных16. Однако ни одна из групп младенцев не показала ответов на редкие тоны, которые значительно отличались бы от ответов на обычные тоны, и, фактически, ответы каждой группы были удивительно схожими как по амплитуде, так и по морфологии.
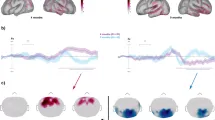
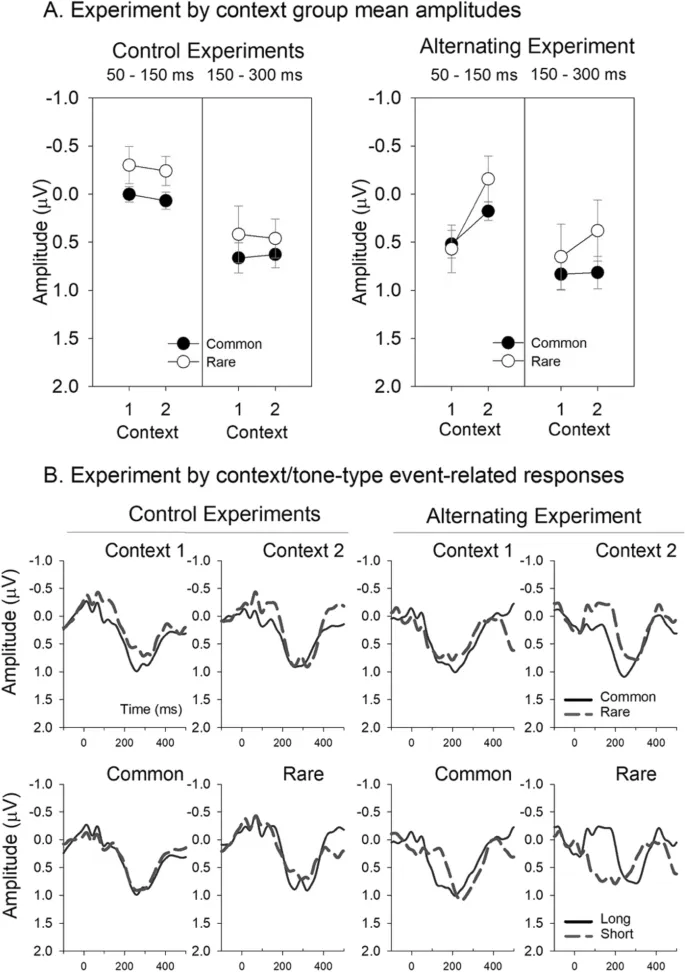
В слуховых ERP ранний период ответа считается отражением относительно более сенсорно-основанных процессов, с более поздними компонентами, прогрессивно более когнитивными по своей природе45. У новорожденных младенцев латентность ответов, вызванных слуховым сенсорным отклонением, зависела как от специфической акустической характеристики, так и от степени разделения32. В предыдущих исследованиях чувствительности к длительности тона у новорожденных ответы на обычные и редкие звуки имели тенденцию различаться примерно от 150 до 300 мс16. Для охвата этого окна ответы количественно оценивались с использованием средней амплитуды в диапазоне 150–300 мс на скальповом электроде Cz. Дополнительный период анализа был включен для захвата более ранних компонентов с использованием средней амплитуды в диапазоне 50–150 мс. Амплитуды компонентов представлены на рис. 2A (слева), а соответствующие ответы — на рис. 2B (слева) и см. также дополнительные рисунки для полного скальпового монтажа. Не было обнаружено общего эффекта условия, ни основных эффектов, ни взаимодействий для любого анализируемого окна при сравнении амплитуд ответов в отдельных смешанных моделях ANOVA с фактором между группами для контекста (контекст 1, контекст 2) и внутрисубъектным фактором для вероятности (обычный, редкий).
У взрослых и новорожденных отсутствие дифференциации в реакции на редкий и обычный звук с разными физическими свойствами обычно считается доказательством того, что два тона не могли быть различимы12,46-48. Безусловно, мозговые ответы наших двух групп младенцев не показали существенных доказательств того, что между редкими и обычными звуками в любой контрольной последовательности была произведена дифференциация. Таким образом, исходя только из этих данных, можно было бы предположить, что эти новорожденные не смогли различить разницу в длительности между 100 и 250 мс тонами. Однако контексты 1 и 2 были весьма отчетливо различимы, когда те же тональные последовательности были объединены попеременно в непрерывную последовательность. Дальше, было также указание на то, что редкие свойства различались во времени.
В эксперименте с чередующимися контекстами (Эксперимент 3) другой группе новорожденных предъявлялись те же тоны, что и в контрольных контекстах, но организованные в чередующуюся последовательность, переключаясь вперед и назад между периодами контекста 1 и 2, смоделированными на основе последовательностей, используемых у взрослых41,49,50 (см. рис. 1). Ответы существенно отличались от тех, что были получены в контрольных контекстах. На рис. 2A (справа), B (справа), ответы на тоны, предъявленные в контексте 2, выглядят очень похожими на ответы в контрольных экспериментах, но ответы на тоны в контексте 1 были явно другими. Морфологическое отличие очевидно в более ранней положительной отклонении в ответ на тоны в контексте 1 в чередующемся эксперименте: положительный сдвиг начинается примерно на 100 мс раньше (то есть, примерно в 50 мс в контексте 1 по сравнению с примерно 150 мс в контексте 2). Это морфологическое отличие заметно не только между контекстом 1 и контекстом 2 в чередующемся эксперименте, но и между контрольным контекстом 1 и чередующимся контекстом 1.
ANOVA с повторными измерениями амплитуд, полученных в чередующейся последовательности, с внутрисубъектными факторами контекста (контекст 1, контекст 2) и вероятности (обычный, редкий) выявила значительно большую положительную поляризацию ответа в диапазоне 50–150 мс в контексте 1 (F(1,27) = 6.269, p < 0.019, η2 = 0.188), отражая этот более ранний положительный ответ на тоны в контексте 1 по сравнению с контекстом 2. Смешанная модель ANOVA, сравнивающая ранние ответы контекста 1 между соответствующими контрольным и чередующимся экспериментами, также указала на значительно более положительные ответы в диапазоне 50–150 мс в группе с чередующейся последовательностью по сравнению с контрольной группой (F(1,64) = 16.968, p < 0.001, η2 = 0.210). Не было значительных основных эффектов или взаимодействий для эквивалентных сравнений амплитуд ответов для контекста 2. Эти различия очевидны на рис. 2, где средняя амплитуда для этого периода явно более положительна в чередующемся контексте 1. Та же ANOVA с повторными измерениями была применена к ответам в диапазоне 150–300 мс, не выявив значительных различий или взаимодействий. В итоге, в отличие от двух контрольных контекстов, младенцы по-разному реагировали на те же два контекста, когда они встречались в одной звуковой последовательности: доминирующая положительность начиналась раньше в чередующемся контексте 1, чем в чередующемся контексте 2, причем только контекст 1 отличался от любого контрольного контекста. Однако не было общего значительного различия между обычными и редкими тонами ни в одном контексте, ни в одном окне, ни в одном эксперименте.
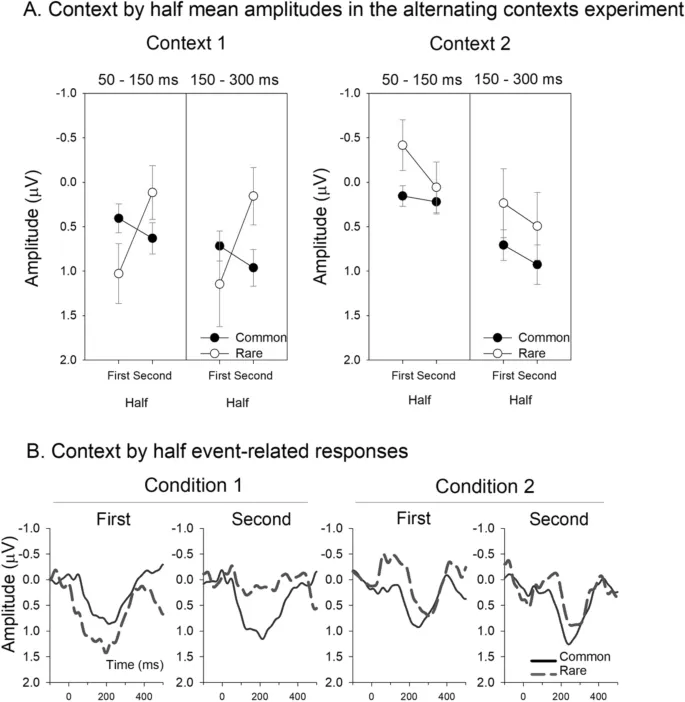
Учитывая данные о том, что младенцы могли различать контексты, и данные у взрослых о том, что взвешивание по точности слуховых ответов драматически меняется со временем в чередующихся последовательностях41,49,50, данные были далее исследованы на предмет доказательств дифференциации вероятности путем раздельного изучения ответов, полученных из первых 2.1 минут и вторых 2.1 минут периодов (1-я и 2-я половина соответственно). Амплитуды компонентов для этих разделений данных представлены на рис. 3A, а сопровождающие ответы — на рис. 3B (см. также дополнительные рисунки для полного скальпового монтажа). Данные на рис. 3, опять же, показывают гораздо большую раннюю положительность в ответ на тоны контекста 1 в целом, но также есть признаки дифференциации между редкими и обычными тонами во второй 2.1-минутный период в более позднем (150–300 мс) измерительном окне. ANOVA с повторными измерениями [вероятность (обычный, редкий) × контекст (контекст 1, контекст 2)] была проведена для проверки эффектов различия вероятности, отдельно для первого и второго 2.1-минутных периодов и для раннего и позднего измерительных интервалов. Анализ ответов в первый 2.1-минутный период выявил значительный эффект контекста в временном окне 50–150 мс (F(1,27) = 11.393, p < 0.002, η2 = 0.297), где ответы были значительно более положительными в первом, чем во втором контексте. Эффект был дополнительно модифицирован вероятностью тона (F(1,27) = 5.464, p < 0.027, η2 = 0.168), причем различия были больше между редкими, чем между обычными тонами, из которых только первые достигли значимости (t(27) = 4.034, pholm < 0.001). Не было значительных основных эффектов или взаимодействий для амплитуд, измеренных в окне 150–300 мс в течение первого 2.1-минутного периода. Однако, что важно, не было обнаружено значительного основного эффекта вероятности в течение первого 2.1-минутного периода для любого контекста.
В отличие от этого, анализ ответов во второй 2.1-минутный период не выявил различий в диапазоне 50–150 мс. Однако был обнаружен основной эффект вероятности для периода 150–300 мс (F(1,27) = 7.284, p < 0.012, η2 = 0.212). Как видно на рис. 3, ответы на редкие тоны были значительно менее положительными (более отрицательными), чем ответы на обычные тоны (m = 0.325 µV против m = 0.944 µV соответственно). В итоге, дифференциация в событийных вызванных мозговых ответах в течение первых 2.1 минут в основном отражала контекст, в котором предъявлялись тоны, но ко второй 2.1 минуте вероятности тонов различались, причем редкие вызывали более отрицательный ответ в диапазоне 150–300 мс; то же окно, которое ранее наблюдалось для улавливания отрицательного ответа несоответствия16.
Обсуждение
Контекстная зависимость реакций новорожденных на звуки подразумевает, что младенческий мозг следует рассматривать как интеллектуального потребителя информации, а не как пассивного обработчика звуковых последовательностей. Предполагается, что внутренние модели окружающей среды содержат оценку степени волатильности среды (см. «точность» в теориях предиктивного кодирования23,25). Оценка волатильности/точности затем взвешивает мозговой ответ, приводя к изменениям амплитуды ответа с течением времени. Там, где модель была построена на основе высоконадежной информации, ответ на соответствующий модели звук должен быть сильно подавлен, а ответы на несоответствующие модели — очень яркими23,25,51. Классические «нечетные» последовательности, используемые для контрольных контекстов 1 и 2, считаются идеальными условиями обучения для построения точных внутренних моделей при условии, что мозг может различать обычные и редкие элементы. Более ранние исследования действительно предполагают, что младенческий мозг может различать используемые здесь длительности15,16, и настоящие данные из чередующихся последовательностей указывают на то, что наши младенцы также различали две длительности. Ключевой вопрос заключается в том, почему новорожденные не делали этого в классических контрольных последовательностях «нечетного» типа. Основные результаты данного исследования обсуждаются ниже в свете тезиса о том, что младенческий мозг чувствителен и отзывчив к информации, переносимой звуком, и что мозговые ответы соответственно настраиваются на это определение. Эта чувствительность к информации, переносимой звуком, будет зависеть от извлечения закономерностей в том, как признаки и объекты сосуществуют в окружающей среде на более длительных временных масштабах, что расширяет взгляд на статистическое обучение до крупномасштабной структуры.
Общая морфология неонатальных ERP, зарегистрированных в данном исследовании, соответствовала паттерну, наблюдаемому во многих предыдущих исследованиях: отрицательная волна во временном окне 50–150 мс, за которой следовал доминирующий центрально-положительный ответ в диапазоне 150–400 мс. Два контекста, использованные в этих экспериментах, характеризовались различными тенденциями к двум звукам, отличающимся друг от друга по длительности (100 мс и 250 мс). Ответы, вызванные обычными и редкими случаями этих двух звуков, были удивительно схожи в контрольных экспериментах. В отличие от этого, сопоставление двух контекстов в чередующейся последовательности выявило способность различать границы в последовательности, где вероятности двух звуков менялись, переходя от большей тенденции к более короткому тону после периода прослушивания большей тенденции к более длинному тону и наоборот. Ключевым показателем того, что младенцы обнаружили эти границы, является точка, в которой начинается положительный сдвиг в морфологии ответа, который гораздо раньше для контекста 1, чем для контекста 2, и гораздо раньше в контексте 1 для чередующегося эксперимента, чем для контрольного эксперимента. Таким образом, существовала сильная зависимость морфологии ответа младенца, основанная на очень долгосрочной структуре слуховой среды.
Существует ряд свойств, которые могут влиять на ответы на изменения тона на границах посредством процесса, называемого адаптацией (обратите внимание, здесь мы ссылаемся на адаптацию в более крупных ответах, а не на уровне отдельных нейронов, для различий52,53). Адаптация, специфичная для стимула, является важным механизмом, с помощью которого слуховая система настраивает реактивность, чтобы отразить избыточность и обострить способность к дискриминации54, а также отличить несущие информацию сигналы от фонового шума55. Процессы, лежащие в основе влияния слуховой статистики на адаптацию, сложны и изощренны52,53, и хотя они считаются недостаточными для полного объяснения чувствительности к отклонениям24, они могут способствовать общему эффекту контекста в чередующейся последовательности. Каждый из них обсуждается по очереди с точки зрения того, насколько хорошо они соответствуют текущим данным. Во-первых, звуки разной длительности несут разный уровень звуковой энергии56, и, как таковые, возможно, что контекст 1 и 2 могли быть дифференцированы на основе общего сдвига интенсивности звука во времени. Это различие, основанное на сенсорных свойствах, можно рассматривать как согласующееся с эффектом, появляющимся рано в вызванном событием ответе45, возможно, даже раньше точки различия в длине тона в 100 мс (см. рис. 2, условие чередования). Различия в длительности звука, использованные здесь, могут влиять на степень адаптации, повышая вероятность того, что ответы контекста 1 более положительны в ранний период из-за более высокого уровня адаптации. Однако у взрослых более длинные тоны показали увеличение амплитуды положительного компонента, который возникает примерно через 200 мс после начала тона, но не ранних компонентов57. Другая особенность контекстов, которая может влиять на адаптацию, — это пауза между тонами в чередующейся последовательности, которая обычно составляла 400 мс в контексте 2 (100 мс обычные тоны с 500 мс межударным интервалом (SOA)), но только 250 мс в контексте 1 (250 мс обычные тоны с 500 мс SOA). У взрослых это различие в паузе меняет степень адаптации. Однако, опять же, у взрослых это проявляется в основном примерно через 200 мс после начала тона57. Наконец, паузы немного длиннее в контрольных условиях (550 мс для контекста 1 и 700 мс для контекста 2), что также может быть связано с различными уровнями адаптации и может снова влиять на амплитуду положительного компонента, который возникает примерно через 200 мс после начала тона. Однако различие в адаптации между двумя контрольными условиями не проявляется. Далее, этот эффект создал бы более положительный ответ в контрольном контексте 1, чем в чередующемся контексте 157. В отличие от этого, здесь было найдено противоположное. В итоге, текущие данные не подтверждают идею о том, что адаптация сама по себе, вероятно, объясняет эффекты у новорожденных, различающих разные контексты или чередующиеся и контрольные последовательности. Поэтому вместо этого предлагается, что различие в ответах возникает только там, где статистические свойства звука несут информацию о более долгосрочной структуре внутри звуковой последовательности. Другими словами, мы предполагаем, что младенцы могут различать два звуковых контекста, но делают это только тогда, когда дифференциация имеет смысл для выделения информации, необходимой для кодирования крупномасштабной структуры.
Только когда звуки были встроены в более длинную структуру, появились доказательства способности различать один звук как локальный редкий выброс. Когда ответы из первой и второй половины контекстов были усреднены отдельно, стало очевидно, что ответы, появляющиеся изначально в «новом» контексте, имели тенденцию отражать только дифференциацию контекста (т. е. разницу в ранней положительности). Позже, когда контекст был стабилен некоторое время, наблюдался значительный отрицательный сдвиг с более поздней задержкой в ответ на редкий тон в контексте 1, что согласуется с предыдущими наблюдениями обнаружения отклонений16. Младенцы обнаруживали звук, который был неуместен или неожидан в этом контексте, и реагировали аналогично тому, что мы видим у взрослых (т. е. более отрицательный ответ47,58,59). Интересно, что данные также предполагают, что это было особенно характерно для первого контекста. Первый контекст, независимо от того, являются ли длинные или короткие тоны обычными, также ассоциируется с более высокими моделями точности у взрослых41-44. Следовательно, ответы на чередующиеся последовательности предоставляют доказательства того, что новорожденные могут не только определять структуру последовательности60, но и формировать внутренние модели, которые со временем повышают точность, позволяя обнаруживать выбросы. Последовательное совершенствование коркового ответа у новорожденных со временем также наблюдалось в статистическом обучении языку8, что также совместимо с концепцией взвешивания по точности, но в данном случае оно демонстрируется в отношении относительной вероятности. Эти наблюдения дополняют совокупность работ, демонстрирующих, как такое обучение формируется многими характеристиками более длительного временного масштаба, включая иерархию, порядок, энтропию и неопределенность9.
Так почему младенцы не реагировали на выбросы, когда они предъявлялись в слушательском контексте, который должен был быть идеальным для наблюдения дифференциальных ответов? Одна из возможных причин влияния долгосрочной структуры звуковой последовательности на дифференциацию звука может быть связана с компромиссом между информационной ценностью поддержания точных внутренних моделей и связанными с этим затратами усилий. В контрольных последовательностях младенцы слышали 3000 тонов в постоянном непрерывном вероятностном расположении в течение 40 минут. В чередующейся последовательности экспозиция к двум контекстам происходила блоками по 500 стимулов: таким образом, максимальный период экспозиции к одной схеме вероятности звука составлял менее 7 минут. Аналогично, в предыдущих исследованиях, демонстрирующих способность маленьких младенцев различать звуки разной длительности15,16, младенцы всегда слышали последовательности продолжительностью менее 7 минут с перерывами между последующими предъявлениями. Таким образом, потенциальным объяснением отсутствия дифференциации тонов в текущих контрольных последовательностях является то, что редкие изменения длительности звука в долгой постоянной последовательности не несли достаточной информации, чтобы рассматривать другую модель, поскольку не было альтернативы, предложенной звуковым вводом. Опять же, младенцы могут различать два звука, но, возможно, перестают это делать, когда это не дает новой информации о структуре.
При воздействии «нечетных» последовательностей в течение длительного периода времени, более широкая и инклюзивная модель, включающая обе длительности звука, позволила бы избежать привлечения внимания к неважным отклонениям, потенциально экономя энергию для моделирования других аспектов окружающей среды23,25,61. В рамках этой более широкой, более инклюзивной модели все слышимые звуки могут восприниматься как предсказуемые, так что отсутствие дифференциации в ответах не отражает неспособность их различить, а скорее определение того, что различение между ними несет недостаточную выгоду, чтобы оправдать затраченные усилия. В отличие от этого, когда эти два одинаковых звука встречаются в чередующихся последовательностях, в среде присутствуют два разных акустических состояния, и моделирование этих двух разных состояний может стать энергетически более выгодным. Это предполагает, что оптимизация ресурсов, потенциальный движущий фактор когнитивного развития62, уже проявляется в первые дни после рождения. Вышеизложенное объяснение полностью совместимо с теорией предиктивного кодирования функций мозга, предполагающей, что фундаментальным принципом работы является стремление уменьшить вариационную свободную энергию, то есть уменьшить сюрприз, используя статистическую информацию для предсказания предстоящих состояний23,61,63. Наблюдения позволяют накапливать плотность вероятности над их скрытыми причинами, и посредством процесса активного вывода внутренняя модель наиболее вероятного следующего состояния может быть выведена и уточнена со временем на основе адекватности соответствия новым данным. Оптимизация модели для снижения свободной энергии может управляться взвешиванием того, следует ли стремиться к точности предсказаний в краткосрочной или долгосрочной перспективе, исходя из энергии, необходимой для достижения этого уровня точности. Развитие или поддержание чувствительности к двум длительностям звука полезно для извлечения предсказуемой структуры в чередующейся последовательности, но не в контрольной последовательности. Этот вид контекстуализированной обработки является еще одним примером того, как ожидания могут формировать реакции на звук64, причем настоящие наблюдения предполагают, что некоторые такие модуляции настолько фундаментальны для обучения, что доказательства можно увидеть в первые дни жизни, даже у спящих новорожденных.
Ограничением данного исследования, как отмечалось во введении, является то, что стабильные компоненты взрослого состояния появляются только в детстве. Наблюдаемые у новорожденных ответы несравнимы с ответами взрослых (например, ни компонент N1, ни N2 не имеют эквивалента у новорожденных; в отличие от амплитуды ответа взрослых, MMR зависит от акустических параметров аномального стимула и т. д.32), что усложняет изучение лежащих в их основе вычислительных принципов (см. для обсуждения32). Существует ряд исследований, например, в которых упоминается большая центральная положительность как признак обнаружения отклонений для некоторых признаков в детских данных33, но это не наблюдалось здесь и, возможно, не является тем, как отклонение длительности отражается в ERP новорожденных, где ранее наблюдался более отрицательный ответ15,16,65,66. Тем не менее, мы предполагаем, что контекстная чувствительность и изменения в реактивности со временем, присутствующие в этих данных новорожденных, указывают на то, как восприятие формируется моделированием сложного паттерна в окружающей среде.
В итоге, представленные здесь данные по младенцам дают два представления о готовности новорожденных обрабатывать звуки в контексте. Возможно, не так удивительно, но новорожденный — это разборчивый слушатель. Далеко не будучи пассивным реципиентом сенсорных переживаний, мозг новорожденного, по-видимому, управляется определениями компромисса между информационной ценностью и энергетической эффективностью. Это уравнение затрат-выгод, по-видимому, приводит к экономии энергии в ситуациях, когда альтернативные модели не могут быть рассмотрены. Однако новорожденные используют более точные модели, когда одна модель не может адекватно объяснить множественные состояния. При этих обстоятельствах имеются четкие доказательства измененной реактивности, которая обеспечивает грубую дифференциацию состояний (между двумя контекстами) и возникновение дифференциации вероятных признаков взвешенным по точности образом. Эти достижения важны для того, чтобы младенцы учились на основе окружающей среды, находя закономерные последовательности событий в постоянно меняющейся стимуляции, обычно из нескольких источников информации/стимуляции, присутствующих одновременно. Эта способность, по-видимому, имеет решающее значение для объяснения готовности, с которой младенцы осваивают критические навыки взаимодействия, такие как понимание речи и вступление в коммуникативный обмен и диалоги60,67.
Материалы и методы
Участники
Электроэнцефалографические (EEG) данные, пригодные для текущего анализа, были записаны от 110 (56 мужчин) здоровых доношенных младенцев в возрасте 0–6 дней после родов. Данные, собранные от еще 14 младенцев, пришлось отбросить: три из-за ошибок записи (не было зарегистрировано триггеров) и одиннадцать из-за несоответствия критериям качества данных (см. раздел «Запись и анализ ЭЭГ» ниже). Младенцы были разделены на три группы (эксперименты): группа контрольного контекста 1 (n = 38, 20 мужчин) имела средний гестационный возраст 39.19 недель (SD = 0.84), массу тела при рождении 3472 г (SD = 522.21); группа контрольного контекста 2 (n = 41, 24 мужчины) имела средний гестационный возраст 39.48 недель (SD = 1.03), массу тела при рождении 3421 г (SD = 416.95); группа чередующихся контекстов (n = 28, 12 мужчин) имела средний гестационный возраст 39.12 недель (SD = 1.03), массу тела при рождении 3404 г (SD = 457.50). Эти размеры выборки соответствуют или превышают размеры выборок в аналогичных предыдущих исследованиях15,16, а оценки g*power предполагают, что мощность наблюдения значительного ответа несоответствия, если он присутствует, превышала 0.99. Все участники имели оценку по Апгар 9/10. Младенцы в основном спали во время записей: 78% времени в тихом сне и 16% времени в активном сне. Информированное согласие было получено от одного (матери) или обоих родителей. Эксперимент проводился в специально оборудованной экспериментальной комнате. Эксперименты 1 и 2 проводились одновременно, младенцы распределялись по экспериментам в сбалансированном порядке. Эксперимент 3 проводился отдельно, все младенцы слышали одинаковые последовательности. Важно отметить, что все записи проводились одинаково, в одинаковой обстановке. Исследование проводилось в полном соответствии с Хельсинкской декларацией и всеми применимыми национальными законами и было одобрено соответствующими этическими комитетами: Комитетом по научной и исследовательской этике Медицинского исследовательского совета (ETTTUKEB), Венгрия.
Звуковые последовательности
Каждой группе предъявлялась последовательность гармонических тонов, подаваемая бинаурально с использованием программного обеспечения EPrime для предъявления стимулов (Psychology Software Tools, Inc., Pittsburgh, PA, USA) с наушниками ER1 (Etymotic Research Inc., Elk Grove Village, IL, USA), подключенными через звуковые трубки к самоклеящимся ушным вкладышам (Sanibel Supply, Middelfart, Denmark), расположенным над ушами младенцев.
Последовательность, предъявляемая в контрольных условиях, основывалась на звуках, ранее использованных в аналогичных исследованиях младенцев, дававших значительно отличающиеся реакции на обычные и редкие звуки11,12. Два гармонических комплексных тона разной длительности (100 мс, 250 мс с 5 мс косинусным нарастанием и спадом каждого) состояли из трех чистых синусоидальных частотных компонентов (500 Гц, 1000 Гц и 1500 Гц с интенсивностью -5 дБ/шаг). Все тоны воспроизводились с равномерной интенсивностью 70 дБ. Тоны предъявлялись по типичной схеме «нечетного» дизайна11, где один звук был обычным (p = 0.85), а другой — редким (p = 0.15), и звуки появлялись псевдослучайным образом, с ограничением, чтобы между редкими звуками встречалось минимум три обычных звука. В контексте 1 длинный звук был обычным, а короткий — редким, а в контексте 2 вероятности были обратными.
Диаграмма, изображающая структуру последовательностей, предъявляемых каждой группе, представлена на рис. 1. В экспериментах 1 и 2 (контроль) 3000 тонов предъявлялись в одной непрерывной последовательности с регулярным межударным интервалом (SOA) 800 мс, причем одна группа получала последовательность, составленную как контекст 1, а другая — как контекст 2. В эксперименте 3 (чередующиеся контексты) тональные последовательности состояли из тех же двух звуков разной длительности, но с SOA 500 мс, которые предъявлялись блоками по 500, попеременно переключаясь между контекстом 1 и 2. Более короткий SOA был необходим для сохранения сходства во времени с чередующимися последовательностями у взрослых41, а SOA 300–500 мс успешно использовались в других исследованиях новорожденных68,69. Каждая группа из 500 звуков начиналась с минимума четырех повторений нового обычного звука. Последовательность предъявлялась три раза с 1-минутной паузой между ними и всегда начиналась с блока контекста 1.
Запись и анализ ЭЭГ
ЭЭГ записывалась с использованием электродов Ag/AgCl, расположенных в точках Fp1, Fp2, Fz, F3, F4, F7, F8, T3, T4, Cz, C3, C4, Pz, P3, P4 в соответствии с системой International 10–20. Референтный электрод располагался на кончике носа, а заземляющий электрод — на лбу. Данные записывались с помощью усилителя с прямым сопряжением (VAmp, Brain Products, Мюнхен, Германия) с разрешением 24 бит и частотой дискретизации 1000 Гц. Обработка данных проводилась с использованием плагина ERPLab70 для EEGLAB71 в среде MATLAB. Сигналы ЭЭГ пропускались через цифровой полосовой фильтр с полосой пропускания от 1 до 25 Гц, и эпохи от -100 до 500 мс относительно начала звука извлекались для каждого стимула. Все измерения амплитуды и иллюстрации относятся к 100-миллисекундному престимульному интервалу, то есть к базовой линии.
Эпохи подвергались процессу отклонения артефактов, где эпохи с изменением напряжения, превышающим 150 мкВ, исключались из анализа. Качество данных считалось приемлемым, если сохранялся минимум 50% эпох для каждого тестируемого условия для электродов F3, Fz, F4, C3, Cz, C4, P3, Pz, P4. Ответы усреднялись отдельно в соответствии с длительностью и вероятностью звука (контекст 1: длинный обычный и короткий редкий тон; контекст 2: короткий обычный и длинный редкий тон). Для тестирования дискриминации длинный против короткого, ответы в чередующемся условии далее разделялись на средние значения, которые отдельно захватывали первую и вторую половину (первый и второй 2.1-минутный период соответственно; см. рис. 3) внутри каждого блока контекста. Разделение первой и второй половины блоков контекста было очень полезным при анализе данных взрослых, поскольку ответы значительно меняются со временем49,72.
Для количественной оценки амплитуд в центральных (Cz) ответах использовались два временных окна. Cz был выбран как электрод, который обычно лучше всего фиксирует эффекты, связанные с отклонениями, у новорожденных (например, 32,34). Первым было среднее значение амплитуды между 50 и 150 мс после начала звука для захвата ранних компонентов ответа. Вторым было среднее значение амплитуды между 150 и 300 мс после начала звука, которое охватывает период, в течение которого наблюдалась значительная разница в ответе на обычные и редкие тоны в предыдущей работе12, указывающая на обнаружение несоответствия с преобладающей внутренней моделью. Отдельные ANOVA-анализы проводились на измерениях амплитуды в диапазонах 50–150 мс и 150–300 мс. Они описаны в разделе результатов, причем некоторые из них являются внутрисубъектными, а другие — межсубъектными, как требовалось. Для исследования значительных взаимодействий применялись пост-хок тесты с коррекцией Холма-Бонферрони. Размеры эффекта сообщаются как частичный эта-квадрат, а уровень значимости критерия был α < 0.05. Вся статистика вычислялась с использованием JASP (версия 0.13.1).