Интересное сегодня

Введение в исследование внимания при распознавании символов
Модели машинного обучения, которые распознают объекты через последовательность "взглядов", вызывают растущий интерес в последние годы благодаря своей масштабируемости и эффективности. Многие из этих моделей сообщили о экспериментальных результатах на эталонном наборе данных MNIST для распознавания рукописных цифр. К сожалению, данные отслеживания внимания для MNIST недоступны. Это препятствует оценке моделей, основанных на внимании, в сравнении с человеческой производительностью.
Мы заполняем этот пробел, собирая набор данных от взрослых участников, пытающихся распознать рукописные цифры и буквы из изображений с помощью последовательной выборки. В отличие от отслеживания внимания по движениям глаз, участник щелкает по местоположению на изображении, которое он хочет увидеть (форма отслеживания внимания по кликам мыши). Сразу после этого он выбирает класс(ы), к которым, по его прогнозам, может принадлежать объект, на основе его наблюдений на данный момент. Таким образом, в каждом эпизоде выборки наши данные состоят из выбранного местоположения изображения, предсказанных меток класса(ов) и времени, затраченного с последнего эпизода участником.
Преимущества отслеживания внимания по кликам мыши
Метод отслеживания внимания по кликам мыши имеет несколько существенных преимуществ по сравнению с отслеживанием движений глаз для распознавания рукописных цифр/букв:
- Снижение вариативности: Отслеживание движений глаз содержит значительную внутри- и межличностную вариативность в местоположении фиксации, особенно для статических стимулов (изображений). Поэтому для получения статистически значимых выводов требуется большое количество данных о фиксации глаз. Отслеживание внимания по кликам мыши не подвержено некоторым источникам технического шума, характерным для данных отслеживания глаз.
- Контроль добровольности: Движения глаз могут быть результатом как добровольных, так и непроизвольных механизмов. Чтобы облегчить принятие решений, зависящих от задачи, мы предоставляем участникам достаточное время, контекст и сигнал подкрепления, которые также могут быть представлены модели машинного обучения.
- Независимость от оборудования: Точность и правильность данных отслеживания движений глаз зависят от айтрекера, в то время как те же параметры отслеживания внимания по кликам мыши не зависят от какого-либо устройства.
- Синхронизация действий: Синхронизация движений глаз с выбором класса представляет сложность. Чтобы преодолеть это, в нашем случае местоположение выборки и класс(ы) выбираются в одном эпизоде.
- Эффективность сбора данных: Наконец, наш метод позволяет собирать данные с помощью Amazon Mechanical Turk, что эффективно по стоимости и времени и легко воспроизводимо.
Методология исследования и сбор данных
Выбор стимулов
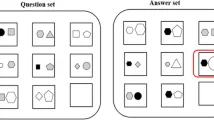
Стимулы выбирались из изображений двух эталонных наборов данных:
- Набор данных MNIST состоит из 70 000 размеченных изображений (28×28 пикселей) 10 рукописных цифр {0,1,…,9}
- Набор данных EMNIST состоит из 145 600 изображений (28×28 пикселей) рукописных английских букв в верхнем и нижнем регистре, образующих сбалансированный класс
Из каждой категории мы выбрали 15 хорошо сформированных цифр из MNIST и 15 хорошо сформированных букв из наборов данных EMNIST в верхнем и нижнем регистре. Таким образом, мы представили стимулы из набора 930 уникальных изображений, по 15 изображений, принадлежащих каждому из 62 классов.
Процесс отбора участников
В нашем исследовании приняли участие в общей сложности 382 различных взрослых человека. Критерии отбора не использовались. Участник мог отвечать на несколько изображений. Для каждого из 62 классов в среднем было записано 169,1 ответов.
Визуальная задача
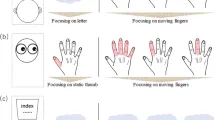
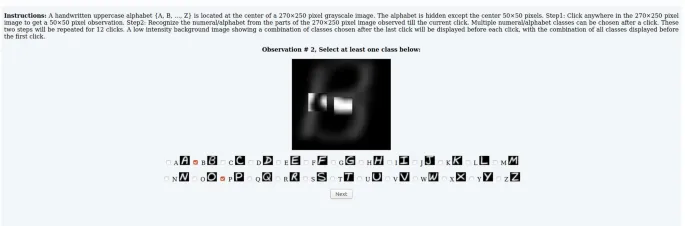
Интерфейс Mechanical Turk для нашей визуальной задачи был разработан следующим образом: холст размером 270×250 отображает изображение с низкой интенсивностью фона в течение всего времени. Фоновые и стимульные изображения увеличиваются в десять раз до 270×250. Центр холста совмещен с центром изображений.
Изначально фоном является среднее значение всех изображений в наборе данных, из которого drawn стимул. После первого эпизода фоном является среднее значение всех изображений из набора классов, выбранных участником в последнем эпизоде.
Процесс выполнения задачи
Задача участника состоит из трех шагов на каждом эпизоде t (t=1,…,T):
- Щелкните в любом месте холста 270×250, чтобы открыть участок, который он хочет выбрать. Принимается только первый щелчок.
- Распознайте цифру/букву по всем образцам, наблюдаемым до сих пор. Участник может выбрать несколько классов и должен выбрать хотя бы один класс из списка классов, показанного ниже холста.
- Нажмите "Далее" в нижней части экрана, чтобы продолжить.
Чтобы точно и быстро вывести класс, участнику придется judiciously выбирать местоположения с учетом его наблюдений до текущего эпизода. Ограничения по времени для эпизода нет. Однако мы ограничиваем общее время для T эпизодов изображения шестью минутами. Мы выбираем T=12, так как в известных работах по распознаванию или генерации рукописного текста на основе внимания использовалось менее 12 "взглядов".
Результаты и анализ данных
Эффективность человеческого распознавания
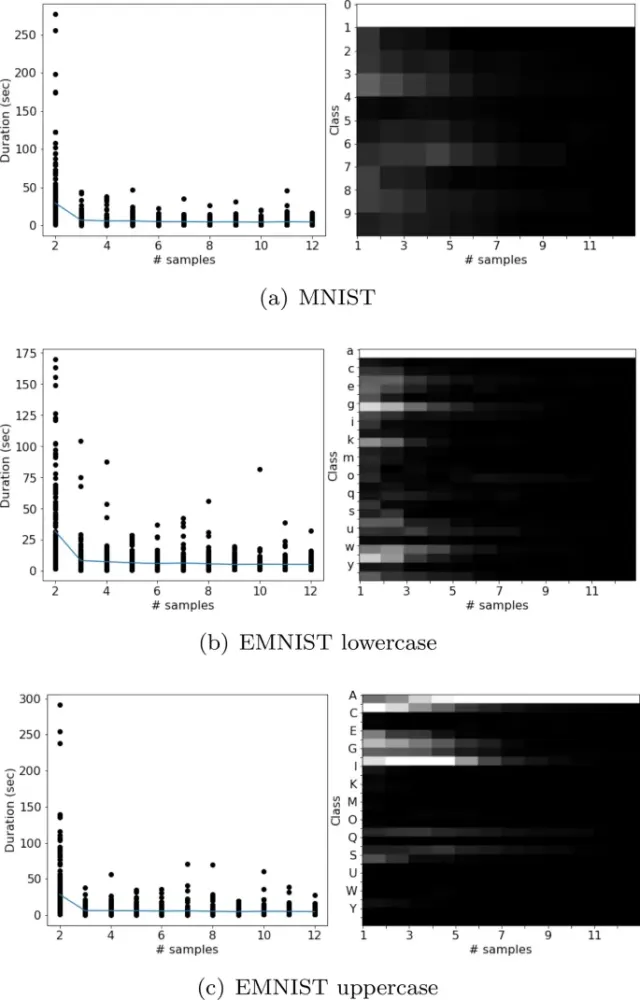
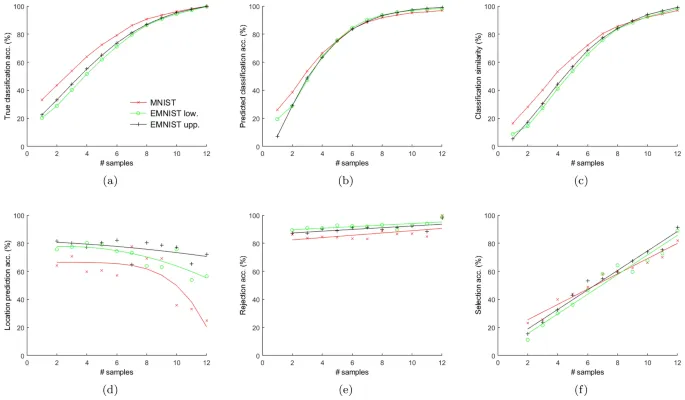
Собранные данные можно визуализировать с точки зрения последовательности распределения выбранных местоположений, выбранных классов и продолжительности между последовательными эпизодами. Эти распределения очень похожи для трех наборов данных.
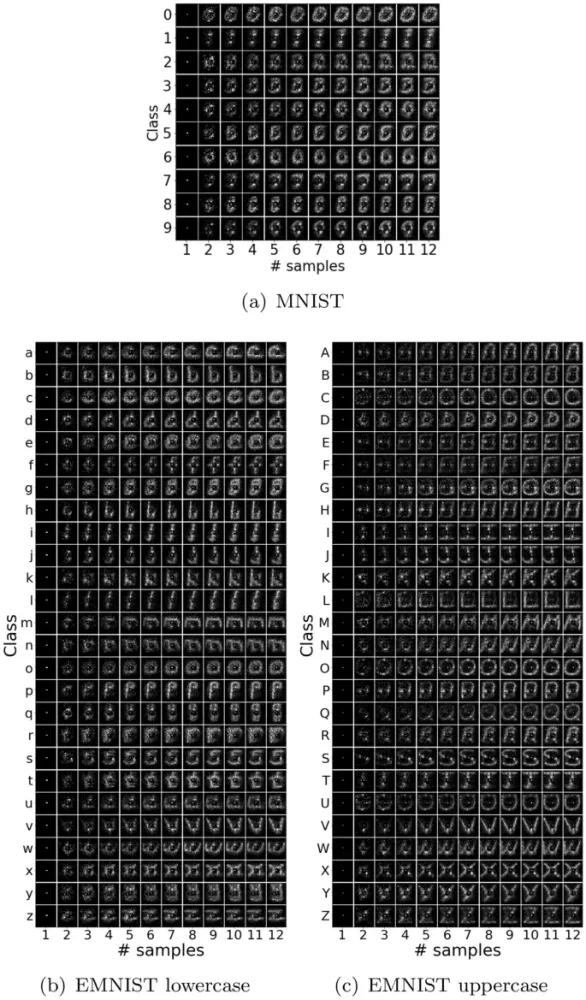
Для любой цифры или буквы распределение выбранных местоположений после финального эпизода напоминает распределение интенсивностей пикселей его класса из набора данных. Однако последовательность выбранных местоположений носит стохастический характер.
Распределение классов указывает на путаницу между категориями с similar structures на начальных нескольких эпизодах, когда участники выбирают несколько классов. Эта путаница уменьшается с увеличением выборки. Существует значительная положительная корреляция между степенью путаницы и продолжительностью выборки.
Количественные показатели эффективности
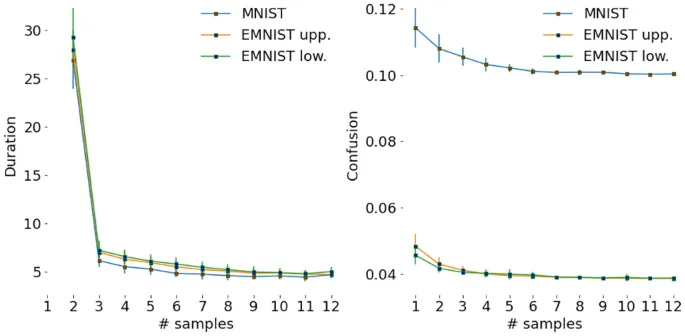
Среднее количество выборок, необходимое участнику для точного прогнозирования класса, довольно низкое. В среднем требуется 4,2, 4,7, 4,9 выборки, что соответствует 36, 44,1, 48,1 секундам для точной классификации изображений MNIST, EMNIST в верхнем и нижнем регистре соответственно. Участники в среднем просматривали только 11,3%, 13,4%, 13,7% площади изображения для точной классификации изображения цифры, буквы в верхнем и нижнем регистре соответственно. Эти результаты подчеркивают эффективность человеческой системы визуального reasoning, хотя и с более низким разрешением, чем данные отслеживания глаз, но с меньшим шумом и вариативностью.
Модели и методы использования данных
Базовые модели прогнозирования поведения
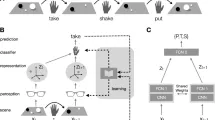
Поведение на любом эпизоде t состоит из выбора местоположения и выбора класса. Поскольку выборка содержит разное количество информации для разных наблюдателей, прогнозирование поведения каждого участника является сложной проблемой.
Мы формулируем проблему прогнозирования поведения участника следующим образом:
- Прогнозирование класса: Оценка вероятности i∈c_t (i=1,2,…,n) с учетом его o_1:t и l_1:t
- Прогнозирование местоположения: Оценка вероятности l_t+1 с учетом его o_1:t, l_1:t и c_t
Оценка моделей на основе внимания
В качестве представителя моделей, основанных на внимании, мы рассматриваем широко цитируемую рекуррентную модель внимания, которая сообщает о экспериментальных результатах на наборе данных MNIST. Эта модель подкрепления последовательно выбирает изображение и решает, где выбрать следующее в каждый момент выборки, что делает ее подходящей для оценки с использованием собранных данных.
Поведение RAM можно сравнить с поведением участников, сравнивая карты фиксации, полученные из последовательности местоположений, предсказанных RAM, и тех, которые выбраны участниками. Карта фиксации вычисляется путем присвоения каждому местоположению значения, равного частоте его выбора, а затем нормализации этих значений для создания распределения по всем местоположениям.
Экспериментальные результаты и сравнение
Точность прогнозирования поведения
Точность прогнозирования класса, показанная на рисунках, вычислена по всем классам для всех выборок. Средняя точность прогнозирования класса по всем выборкам и наборам данных составляет 74,4% (стандартное отклонение 26,5).
Наборы классов, выбранные участниками и нашей базовой моделью, довольно неточны на начальных эпизодах и улучшаются с увеличением выборок. В течение начальных эпизодов эти два множества довольно dissimilar; схожесть увеличивается с увеличением выборок.
Сравнение с моделью RAM
В этих условиях RAM требуется 3,7, 8,5, 7,6 выборок для распознавания цифр MNIST, букв EMNIST в верхнем и нижнем регистре, что соответствует 8,9%, 21,0%, 18,7% площади изображения соответственно. Таким образом, по сравнению с нашими участниками RAM менее эффективна.
Результаты сравнения карт фиксации из RAM и собранных данных показывают, что расхождения существуют, что подразумевает, что несколько местоположений выбираются участниками, но не RAM. Эти эксперименты могут быть использованы в качестве baseline для оценки местоположений, выбираемых моделью внимания.
Обсуждение и выводы
Парадигма отслеживания внимания по кликам мыши, используемая в этой статье, имеет определенные точки отличия от тех, которые в основном полагаются на движения глаз и взгляды для изучения механизмов распознавания объектов. Поскольку участники настоящего исследования рассматривали статические изображения в условиях свободного просмотра и с достаточным временем, они, вероятно, engaged in серией саккадических движений глаз или визуального рассуждения для исследования изображения перед щелчком на области интереса.
Вероятно, что взгляды непосредственно перед и после выбора области интереса — возможно, также aided фиксационными движениями глаз — внесли наибольший вклад в распознавание цифр/букв. Мы предполагаем, что участники выбирали диагностические области изображения, чтобы различать классы, и эти области, вероятно, содержат смесь bottom-up и top-down диагностической информации.
Основные достижения исследования
Мы представили набор данных отслеживания внимания по кликам мыши для распознавания рукописных цифр и букв с помощью последовательной выборки. Данные собраны от 382 участников, которым presented изображения, выбранные из эталонных наборов данных. В среднем записано 169,1 ответов на класс цифр/букв. Данные тщательно проанализированы, чтобы выявить эффективность человеческого визуального распознавания.
Участники наблюдали только 12,8% изображения для распознавания. Мы предложили базовую модель для прогнозирования местоположения и класса(ов), которые участник выберет при следующей выборке. Мы показали, как наши экспериментальные условия и данные могут быть использованы для оценки модели подкрепления на основе внимания по сравнению с человеческой производительностью. Этот набор данных отслеживания внимания по кликам мыши, с множеством преимуществ по сравнению с данными отслеживания глаз, заполняет crucial gap в исследованиях моделей на основе внимания в искусственном интеллекте, машинном обучении и других областях.