Интересное сегодня

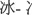
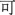

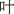



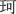
introduction
В последние 15 лет мегаисследования значительно увеличили доступность данных о распознавании визуальных слов для различных языков с алфавитными системами письма, таких как английский (Balota et al., 2007; Keuleers et al., 2012), голландский (Brysbaert et al., year; Keuleers et al., 2010), французский (Ferrand et al., 2010), малайский (Yap et al., 2010), испанский (Aguasvivas et al., 2018; Miguel-Abella et al., 2022), персидский (Nemati et al., 2022) и иврит (Stein et al., 2023). Мегаисследования распознавания визуальных слов обычно собирают данные реакций на большую часть слов языка, позволяя ответить на множество исследовательских вопросов без необходимости разработки и выполнения ad hoc эксперимента (Brysbaert et al., 2018; Keuleers & Balota, 2015). Количество стимулов и их вариативность предлагают преимущества в терминах статистической мощности и моделирования эффектов непрерывных переменных (Cortese, 2019) и улучшают обобщаемость результатов (Yarkoni, 2022). Анализ данных мегаисследований значительно уточнил наше понимание эффектов формы слова (Ferrand et al., 2010; Miguel-Abella et al., 2022; Stein et al., 2023), семантики (Keuleers et al., 2012), фонетики (Stein et al., 2023; Yap et al., 2010), частоты использования (Keuleers et al., 2012; Miguel-Abella et al., 2022), эффективных измерений (Balota et al., 2007) и характеристик читателя (Kuperman & Van Dyke, 2013; Baayen et al., 2016).
Существующие мегаисследования по распознаванию китайских слов и иероглифов.
Подобные усилия были предприняты для сбора данных мегаисследований для языков с неалфавитными системами письма, в частности для китайского языка. Существует две тесно связанные вариации морфосиллабической системы письма (DeFrancis, 1989; Gorman & Sproat, 2023) для записи китайского языка: Гонконг, Тайвань и Макао используют традиционные китайские иероглифы, тогда как материковый Китай, Сингапур и Малайзия используют упрощенные иероглифы. Упрощенные иероглифы, которые были впервые введены в 1956 году, требуют меньшего количества штрихов для написания и являются визуально менее сложными (Cheng, 1975; McBride-Chang et al., 2005).
То, что делает исследование визуального распознавания слов в китайском языке отличительным, так это его большой набор иероглифов. В то время как чтение в алфавитных системах письма включает относительно ограниченный набор букв (напримермер, 26 в английском языке), китайская система письма требует от читателей распознавать несколько тысяч иероглифов. В большинстве случаев эти отдельные иероглифы также являются словами сами по себе. Кроме того, основная часть китайских слов является биморфемной (Mok, 2009). Мегаисследования в китайском языке часто фокусируются на словах из одного и двух иероглифов. В то время как первое является основным фокусом данной статьи, исследования, использующие слова из двух иероглифов (Tsang & Zou, 2022; Tse et al., 2017, 2023), не менее информативны.
Таблица 1 дает обзор существующих мегаисследований, касающихся распознавания отдельных иероглифов, по задаче (лексическое решение, называние, рукопись), варианту иероглифа (традиционный или упрощенный), количеству иероглифов (NChar), количеству участников (NParticipant) и среднему количеству иероглифов на участника (неизвестно для Tsang et al., (2018), потому что они используют до 12,578 слов разной длины от одного до четырех).
Согласно литературе по визуальной обработке слов в алфавитных языках, наиболее сильные эффекты, обнаруженные в этих исследованиях, связаны с тем, как часто иероглифы встречаются в процессе развития: иероглифы с более высокой частотой и знакомостью, а также с более ранним возрастом приобретения и возрастом обучения легче обрабатывать (Chang et al., 2016; Lee et al., 2015; Liu et al., 2007; Sze et al., 2014; Tsang et al., 2018). Однако, результаты также показывают сложное взаимодействие между составом иероглифа и его отношением к другим иероглифам. Lee et al. (2015), Liu et al. (2007) и Sze et al. (2014) показали, что время обработки увеличивается с визуальной сложностью (количеством штрихов), и результаты Liu et al. (2007) и Chang et al. (2016) показывают, что иероглифы, состоящие из семантического и фонетического компонента, легче назвать, когда фонетический компонент соответствует произношению всего иероглифа. Иероглифы с множественными произношениями трудно распознать (Tsang et al., 2018), но количество других иероглифов, с которыми иероглиф делит фонетические компоненты, ускоряет его обработку (Chang et al., 2016). Также, если иероглиф делит одно и то же произношение с другими иероглифами – его омофонами – то он становится легче обрабатывать, если эти иероглифы также имеют один и тот же фонетический компонент (Lee et al., 2015, LDT). Однако, количество омофонов, которые имеет иероглиф, и частота иероглифов с одним и тем же произношением, похоже, не влияют на обработку Liu et al. (2007). В отношении семантики количество иероглифов, делящих один и тот же семантический радикал, не облегчает называние (Chang et al., 2016), тогда как количество значений облегчает распознавание для иероглифов с низкой частотой (Sze et al., 2014). Семантические переменные, такие как конкретность и образность, также облегчают чтение (Liu et al., 2007).
approach
Ограничения существующих исследований.
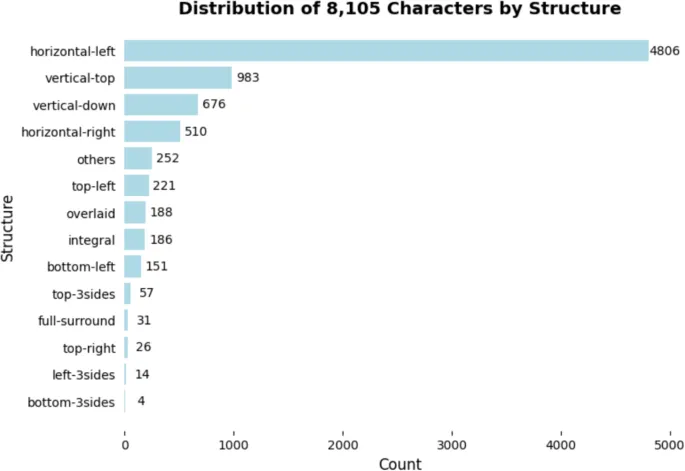
Китайские иероглифы считаются закрытым классом (Hockett, 1951; Hoosain, 1992). Другими словами, хотя новые слова могут быть образованы путем комбинирования существующих иероглифов, новые иероглифы не создаются ради создания новых слов. Согласно Списку часто используемых стандартных китайских иероглифов, официальному списку, используемому в материковом Китае (Language and Text Information Management Department, 2013), существует 8105 упрощенных иероглифов. Однако, некоторые из этих иероглифов не находятся в широком употреблении, часто ограничиваясь формальными текстами (Hoosain, 1992). Корпус SUBTLEX-CH (Cai & Brysbaert, 2010), который основан на субтитрах фильмов и телевидения, содержит 5936 уникальных иероглифов, из которых 4746 используются более пяти раз. Если что-то, это указывает на то, что не все иероглифы часто используются. Однако, определить, какие иероглифы известны и в какой степени, невозможно на основе только данных корпуса. Например, некоторые иероглифы могут соответствовать регистру, который не часто представлен в данных корпуса. Поэтому определить, какие иероглифы следует включить в мегаисследование на основе их использования, непросто. Практически, также возможно просто собрать данные мегаисследования для всех китайских иероглифов. Фактически, полный набор из 8105 иероглифов все равно был бы намного меньше, чем количество слов, собранных в нескольких мегаисследованиях в алфавитных языках (напримермер, ELP, 40,481 слов; BLP, 28,730 слов; FLP, 38,840 слов). Удивительно, как показывает Таблица 1, ни одно из существующих мегаисследований по обработке китайских иероглифов не представило полный набор упрощенных иероглифов участникам.
Сбор данных по этому полному набору иероглифов максимизирует его исследовательский потенциал. Например, у каждого иероглифа есть радикал, компонент, используемый для поиска в словаре (называемый bushou в китайском языке. Для подробного обсуждения различных использований термина см. Yeh и Li, 2002). Радикалы критически важны для развития чтения (Ho et al., 2003) и играют важную роль в обработке иероглифов (Hsu et al., 2021; Yeh & Li, 2002). Существует 201 основной радикал, некоторые с вариантами в зависимости от их положения в макете иероглифа (State Language Affairs Commission, 2009). Ни MELD-SCH, ни CLP не охватывают весь этот набор.
Мегаисследования визуального распознавания слов часто принимают форму задачи лексического решения. Хотя у этой задачи есть некоторые недостатки (Balota & Chumbley, 1984), одно из главных преимуществ этой задачи заключается в том, что времена реакции прямолинейны для анализа. В мегаисследованиях дизайн псевдоиероглифов (или псевдохарактеров) имеет решающее значение. Если участники через неявное статистическое обучение могут идентифицировать свойства, которые с высокой вероятностью отличают псевдоиероглифы от стимулов иероглифов, они могут начать реагировать на то, отражают ли стимулы эти свойства, а не на то, существует ли иероглиф или нет. Существующие методы генерации псевдоиероглифов произвольного комбинирования подкомпонентов могут столкнуться с такой проблемой. Кроме того, понимание того, как обрабатываются псевдоиероглифы, улучшает наше понимание того, как обрабатываются слова (Cassani et al., 2020; Hendrix & Sun, 2021). Хотя существующие мегаисследования китайских иероглифов, которые используют задачу лексического решения, уделяли большое внимание созданию хороших псевдоиероглифов, MELD-SCH является единственным существующим мегаисследованием, которое опубликовало латентности псевдоиероглифов. Однако, 12 из его псевдоиероглифов перечислены в корпусе частоты SUBTLEX-CH (Cai & Brysbaert, 2010), что указывает на то, что они, возможно, не являются истинными псевдоиероглифами. В целом, мы считаем, что в этой области все еще есть место для улучшения.
В данной статье мы представляем Проект Лексикон Упрощенных Китайских Иероглифов (SCLP), который собирает данные лексического решения для всех 8105 иероглифов в Списке часто используемых стандартных китайских иероглифов и 4864 псевдоиероглифов, тщательно разработанных для отражения свойств и вариаций, присутствующих в реальных иероглифах.
Участники
Участники были набраны в Южно-Китайском нормальном университете через электронные флаера, распространяемые в чате WeChat, специально разработанном для объявления экспериментов. Флаер информировал потенциальных участников о том, что они могут принять участие в исследовании распознавания китайских иероглифов, которое займет в среднем 6 часов. Потенциальным участникам сообщили, что они получат 200 RMB по завершении исследования или 7 RMB за блок, если они решат не продолжать эксперимент. Всего было набрано 42 участника (27 женщин, 15 мужчин) для участия в эксперименте. Все участники приняли участие в пилотной сессии, в которой были представлены четыре блока по 20 стимулов (12 иероглифов и восемь псевдоиероглифов на блок). Участникам сообщили, что они не смогут продолжить эксперимент, если не достигнут требуемого балла по крайней мере в двух блоках в тестовой сессии (двое участников не продолжили) или в более чем четырех блоках в ходе эксперимента (трое участников не продолжили). Кроме того, восемь участников выбыли из эксперимента по личным причинам. В результате, 29 участников (19 женщин, 10 мужчин) завершили все блоки и отреагировали на все стимулы. Их возраст варьировался от 18 до 24 лет (M = 20.31, SD = 1.97). Для оценки их владения китайским языком участникам были предоставлены их баллы по китайскому языку в Национальном экзамене на поступление в высшие учебные заведения в качестве справки (M = 114.07 из 150, SD = 6.54).
Стимулы
Стимулы состояли из 8105 иероглифов и 4864 псевдоиероглифов. Иероглифы были выбраны на основе их включения в Список часто используемых стандартных китайских иероглифов, опубликованный Управлением по управлению языковой и текстовой информацией (2013). Следуя Keuleers и Balota (2015), было использовано неравное соотношение иероглифов (62.5%) и псевдоиероглифов (37.5%), чтобы предотвратить развитие предвзятости участников к отрицательным ответам. Учитывая типичный размер словаря 80% (оцененный на основе средней точности в CLP & MELD-SCH) и небольшой процент положительных ответов на псевдоиероглифы, это соотношение должно привести к тому, что средний участник даст примерно столько же ответов „да“, сколько и ответов „нет“. В данном исследовании большое количество редких иероглифов привело к средней точности 61% для иероглифов. В сочетании с высокой долей правильных отказов для псевдоиероглифов это все равно привело к небольшой предвзятости отрицательных ответов.
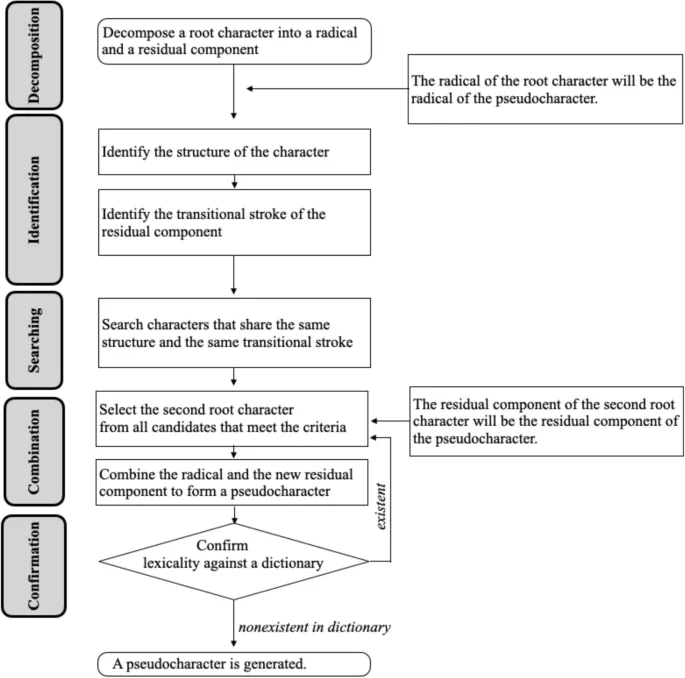
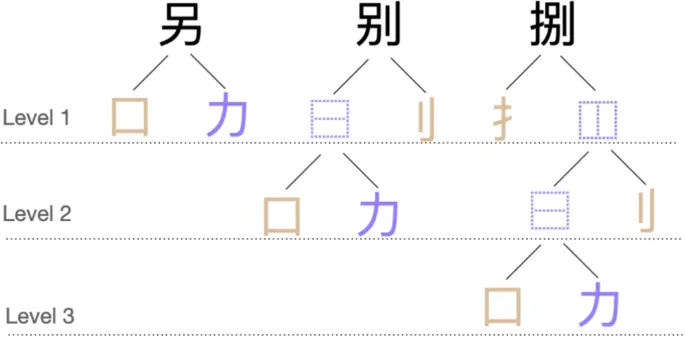
Для генерации псевдоиероглифов было использовано то, что иероглифы могут быть иерархически декомпозированы (см. Рис. 1). С точки зрения дихотомического подхода, иероглифы, за исключением тех, которые имеют цельные структуры, могут быть декомпозированы на радикал и остаточный компонент. Мы определяем уровень, на котором происходит манипуляция этих подкомпонентов, как уровень 1. Если остаточный компонент сам по себе является декомпозируемым иероглифом, то он может быть далее разделен на радикал и остаточный компонент, где уровень определяется как уровень 2, и так далее. Мы установили максимальный уровень три. Такая декомпозируемость позволяет иероглифам быть рекомпозированы путем иерархического соединения подкомпонентов. Таким образом, псевдоиероглифы могут быть сгенерированы через обмен подкомпонентами двух корневых иероглифов на определенном уровне. В то время как почти все существующие методы (напримермер, Sze et al., 2014) сосредоточены на обмене подкомпонентами на уровне 1, что имеет преимущество сохранения функций подкомпонентов (напримермер, возможной фонетической информации от остаточных компонентов), более глубокое исследование иерархической структуры позволяет создание на уровне 2 или выше, что приводит к созданию уникальных псевдоиероглифов. Однако, мы признаем, что манипуляция на более глубоких уровнях может привести к результатам с высокой визуальной сложностью. Для решения этой проблемы на уровни 2 и 3 накладываются ограничения. Конкретно, количества штрихов выбранных подкомпонентов совпадают, чтобы сделать полученные элементы правдоподобными. Процедура описана на Рис. 2. Для подробного объяснения генерации псевдоиероглифов см. Wang et al. (2024).
Мы выбрали в общей сложности 4864 псевдоиероглифа для эксперимента, включающих 4603 на первом уровне манипуляции, 239 на втором уровне и 22 на третьем уровне. Лексический статус каждого псевдоиероглифа был проверен с использованием онлайн-словаря Xinhua Dictionary (2024). Мы обеспечили, чтобы в наборе псевдоиероглифов каждый радикал встречался пропорционально его частоте в наборе иероглифов. Подобным образом, набор псевдоиероглифов соответствовал набору иероглифов в распределении количества штрихов. Данные декомпозиции для этих иероглифов были получены из онлайн-базы данных штрихов иероглифов (Hanzi Stroke Lookup, 2024).
Процедура
Вся задача состояла из до 12,969 испытаний, рандомизированных для каждого участника перед разделением на 26 блоков (первые 25 блоков по 500 испытаний и последний блок по 469 испытаний). Эксперимент начался с тестовой сессии, в которой 80 испытаний были разделены на четыре блока, чтобы ознакомить участников с работой всей системы, и результат не был записан. В конце каждого блока участники получали отчет о производительности, в котором указывался уровень точности для реальных иероглифов и уровень ошибок для псевдоиероглифов. Отчет сопровождался инструкцией сделать 5-минутный перерыв. За одни сутки участникам разрешалось завершить максимум четыре блока задач, и время, потраченное на задачи, не должно было превышать 2 часа. В противном случае они могли остановиться раньше, когда захотят. Триал состоял из знака фиксации и стимула (иероглифа или псевдоиероглифа). Сначала знак фиксации отображался в центре экрана в течение 500 мс, затем через 120 мс отображался стимул. Участники нажимали кнопку j, если считали, что стимул является реальным иероглифом, и f, если это был псевдоиероглиф. Время реакции не было ограничено, хотя участников информировали заранее, что они должны реагировать как можно быстрее с лучшей точностью. Обратите внимание, что участникам также было явно указано не угадывать, а использовать стратегию знакомства, чтобы увеличить свои баллы. Им было сказано: „Если вы когда-либо видели или знали эти стимулы, вероятность того, что это иероглиф, выше. Если вы не видели, вероятность того, что это не иероглиф, выше.“
conclusion
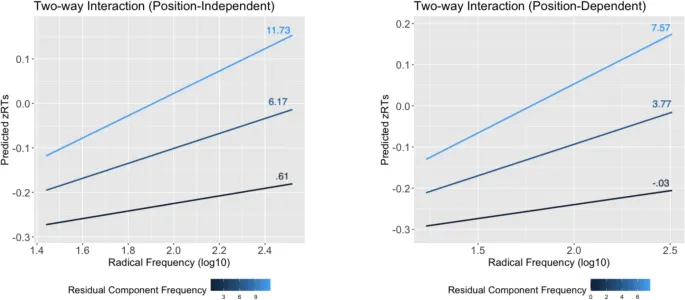
В данной статье мы представили Проект Лексикон Упрощенных Китайских Иероглифов (SCLP), который собирает данные лексического решения для полного набора упрощенных китайских иероглифов, перечисленных в Списке часто используемых стандартных китайских иероглифов. Наш анализ показывает, что внутренняя надежность собранных данных сопоставима с надежностью существующих мегаисследований. SCLP добавляет к объему работ, установленному двумя предыдущими мегаисследованиями распознавания иероглифов (CLP и MELD-SCH) и дает исследователям возможность сравнивать результаты по нескольким исследованиям.
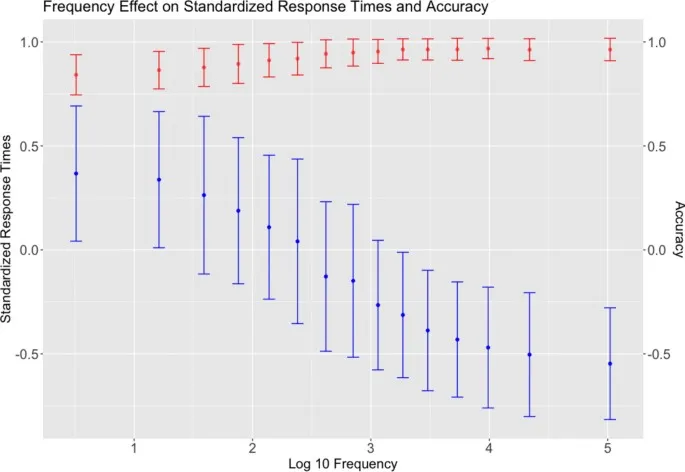
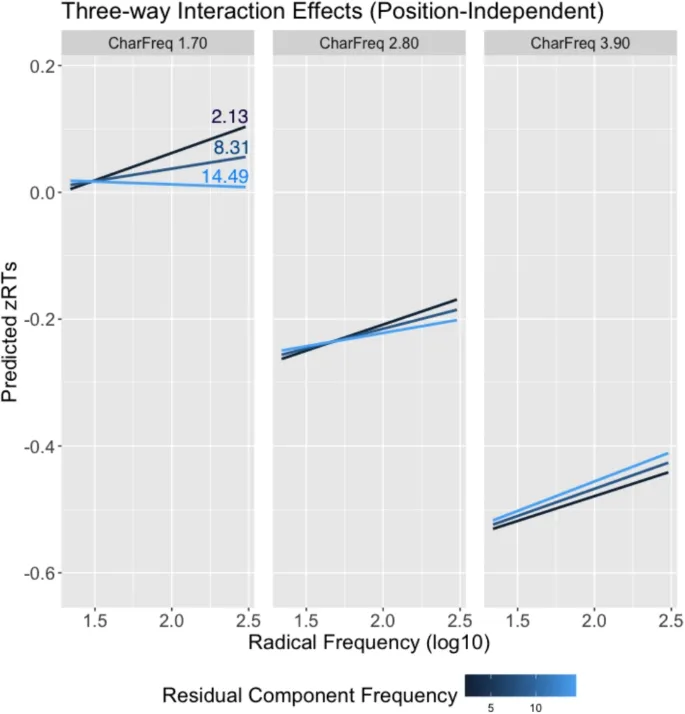
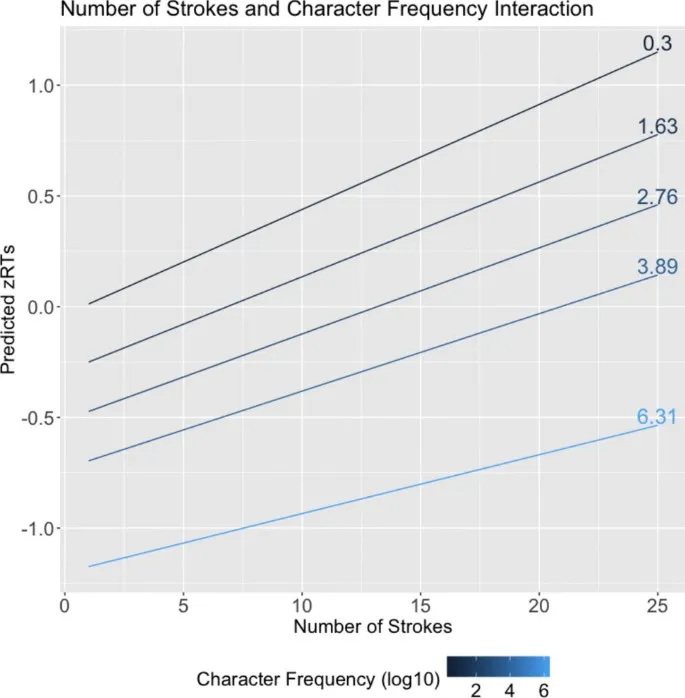
Данные, собранные в SCLP, имеют потенциал внести вклад в наше понимание обработки китайских иероглифов. Как мы показали, данные могут быть использованы для проведения виртуальных факторных экспериментов или для понимания непрерывных эффектов переменных на обработку иероглифов. В исследованиях, представленных здесь, мы показали, что существует устойчивый эффект количества штрихов по всем иероглифам, что обработка иероглифов зависит от сложного взаимодействия между размером соседства и регулярностью, и что взаимодействие между частотой иероглифов и частотой подкомпонентов влияет на распознавание иероглифов. В этом контексте мы считаем, что способ определения регулярности для китайских иероглифов может быть улучшен. Существующие определения регулярности либо бинарны (напримермер, Fang et al., 1986), либо ограничены маломасштабными категоризациями (напримермер, Liu и Zhang, 2020). Более изощренный подход к определению регулярности заключался бы в использовании более точных метрик расстояния, таких как расстояние Левенштейна, для измерения относительного расстояния между произношением (пиньинь) подкомпонентов иероглифа и его произношением в целом. Это позволило бы исследователям изучать эффект фонетического отображения на непрерывной шкале с использованием всего набора иероглифов, представленного в этом исследовании.
Для SCLP мы тщательно разработали и выбрали псевдоиероглифы, чтобы избежать неявного обучения (Reber, 1989). Вместо произвольного комбинирования подкомпонентов мы контролировали частоту переходов штрихов между подкомпонентами. Мы также обеспечили, чтобы диапазон визуальной сложности, присутствующий в наборе иероглифов, соответствовал набору псевдоиероглифов. Наш набор псевдоиероглифов также отражает, в значительной степени, пропорции, с которыми конкретные радикалы и остаточные компоненты встречаются в реальных иероглифах. Метод генерации псевдоиероглифов, использованный для SCLP, также может быть расширен для исследований, использующих слова из нескольких иероглифов. Типично, псевдослова из нескольких иероглифов создаются путем комбинирования существующих иероглифов, что эффективно в терминах подготовки материала, но игнорирует то, что иероглифы сами по себе имеют составные части. Результаты данного исследования указывают на то, что изучение обработки псевдослов, состоящих из сложных псевдоиероглифов, может дальше прояснить роль свойств подкомпонентов в распознавании китайских слов.