
Интересное сегодня

Сравнительный анализ моделей обучения с подкреплением в человеческой пространственной навигации
Модели обучения с подкреплением (Reinforcement Learning, RL) оказали значительное влияние на понимание процессов обучения и принятия решений у человека. Однако их применение для изучения человеческой пространственной навигации, а также систематическое сравнение различных RL-моделей при различных навигационных требованиях, изучено недостаточно. RL-модели позволяют количественно и непрерывно описывать стратегии обучения человека, а также оценивать последовательность их применения. Это открывает новые возможности для понимания значительных индивидуальных различий в навигационных способностях человека и отделения самих стратегий от результативности навигации.
В данном исследовании приняли участие сто четырнадцать человек, которые выполняли задания по поиску пути в виртуальной среде. В процессе выполнения задач изменялись навигационные требования. Была проведена сравнительная оценка эффективности пяти RL-моделей (три модели без модели среды (model-free), одна модель с моделью среды (model-based) и одна «гибридная») в интерпретации навигационного поведения на разных этапах.
Введение: Роль обучения с подкреплением в понимании навигации
За последние два десятилетия обучение с подкреплением (RL) достигло значительного прогресса в таких областях, как информатика, психология и нейронаука. RL описывает механизм обучения, при котором поведение формируется посредством приближения к вознаграждению и избегания наказания. Этот подход имеет долгую историю, уходящую корнями в XIX век. В психологии исследования RL демонстрируют, что оно может быть иерархически структурировано и взаимодействует с другими когнитивными функциями, такими как рабочая память, при принятии решений. В нейронауке исследователи RL стремятся выявить нейронные субстраты, представляющие параметры RL (например, ошибку предсказания в RL-модели), включая полосатое тело, вентромедиальную префронтальную кору, гиппокамп и активность дофаминовых нейронов.
Большинство парадигм, используемых в исследованиях человеческого RL, сосредоточены на принятии решений в двумерных средах. Поэтому остается недостаточно изученным вопрос, могут ли эти выводы быть обобщены на сценарии, важные для выживания, такие как пространственная навигация, которая происходит в трехмерных средах. Более того, моделирование человеческого пространственного навигационного поведения с помощью RL-моделей может дать дополнительное понимание лежащих в основе когнитивных механизмов для заданного навигационного маршрута по сравнению с традиционными методами (например, вычисление длины маршрута). Это достигается путем использования собственной навигационной истории человека для количественной оценки индивидуальных навигационных стратегий и последовательности их применения (обсуждается ниже). Текущее исследование направлено на устранение этих пробелов и использование возможностей, существующих в научной литературе.
Два типа обучения с подкреплением: модель-свободное и модель-основанное
Для максимизации вознаграждений при минимизации усилий/затрат мы изучаем ассоциации между поведением и вознаграждениями преимущественно с помощью двух типов RL:
- Модель-свободное обучение (model-free): способствует жесткому повторению ранее вознагражденных действий.
- Модель-основанное обучение (model-based): способствует формированию ментальной модели среды или структуры задачи для гибкого выбора целенаправленных действий.
В контексте пространственной навигации, модель-свободное обучение соответствует обучению реакции (response learning) или простому запоминанию ассоциаций «ориентир-действие» (например, повернуть направо у второго светофора) без изучения общего расположения среды. Модель-основанное обучение, напротив, соответствует обучению месту (place learning) или изучению конфигурации среды.
В литературе по RL существуют данные, показывающие, что модель-свободное и модель-основанное обучение работают параллельно и конкурируют друг с другом. В литературе по человеческому пространственному познанию имеется множество свидетельств существенных индивидуальных различий в пространственной навигации человека, включая эффективность поиска пути и стратегии навигации. Такие индивидуальные различия коррелируют со структурными и функциональными особенностями мозга, объемом рабочей памяти, полом и инструкциями к задаче.
Исходя из этих данных, разумно предположить, что, хотя навигационное поведение некоторых людей лучше всего описывается либо модель-свободным, либо модель-основанным обучением, большинство из них будет лучше всего описываться гибридной моделью, которая представляет собой комбинацию или более непрерывный баланс между модель-свободным и модель-основанным обучением.
Актуальность исследования и гипотезы
Удивительно, но очень мало исследований подтвердили идею о том, что такая гибридная RL-модель наилучшим образом описывает человеческую пространственную навигацию. В исследовании с использованием задачи пространственной навигации, где расположение среды постоянно менялось, было обнаружено, что модель-основанное обучение лучше соответствует данным, чем модель-свободное. Однако вопрос о том, обеспечивает ли гибридная модель лучшее соответствие, чем модель-основанная, остался открытым. Другое исследование сравнивало нейронные субстраты, отслеживающие параметры модель-свободного, модель-основанного и гибридного обучения, но вопрос о том, какая модель наилучшим образом соответствует самим данным навигации, остался без ответа. Мы считаем, что сравнение этих трех типов моделей имеет решающее значение для исследования того, как результаты вычислительного моделирования, такие как RL, соответствуют устоявшимся индивидуальным различиям и предпочтениям в стратегиях, выявленным в литературе по пространственному познанию.
Если результаты RL согласуются с данными литературы, мы сможем с большей уверенностью использовать параметры, генерируемые RL-моделями, для лучшего понимания человеческой пространственной навигации. Как отмечалось выше, уникальный вклад применения RL в понимание человеческой пространственной навигации заключается в том, что RL-модели могут количественно и в зависимости от предыдущего опыта человека раскрыть его навигационную стратегию. В недавних исследованиях мы и другие использовали «задачу двойного решения» (dual solution task) для количественной оценки навигационных стратегий индивидов, связанных с следованием по известному маршруту против выбора более короткого пути. В этом подходе участники сначала несколько раз следуют по заранее определенному маршруту к цели, а затем могут перемещаться к цели свободно. Используя эту задачу, индивидуальная навигационная стратегия количественно оценивается с помощью индекса решения, который равен количеству попыток, в которых был выбран новый короткий путь, разделенному на общее количество успешных попыток, в которых был выбран либо короткий путь, либо изученный маршрут.
Исследования с использованием этой задачи демонстрируют заметные индивидуальные различия в навигационных тенденциях: одни люди преимущественно используют короткие пути, другие — известные маршруты, а многие находятся между этими крайностями. Однако классификация навигационной стратегии эпизода как следования по известному маршруту или выбора короткого пути может упрощать многие сложные навигационные поведения, наблюдаемые в нашей повседневной жизни. Часто бывает так, что человек сначала следует по первым нескольким участкам изученного маршрута, а затем выбирает короткий путь оттуда. Аналогично, когнитивные требования «короткого пути» могут сильно зависеть от того, какая часть последовательности маршрута была ранее пройдена (то есть, в какой степени маршрут является новой конструкцией).
Параметр веса гибридной RL-модели может раскрыть степень опоры навигатора на когнитивную карту или на следование по маршруту на основе каждой отдельной попытки, что обеспечивает более детальную характеристику индивидуальной навигационной стратегии объективным и непрерывным образом, основанным на их предыдущей навигационной истории. Кроме того, RL-модели могут оценивать последовательность использования навигационной стратегии в различных навигационных эпизодах. Эти два параметра из RL дают важное представление о том, как человек адаптирует свои навигационные стратегии в условиях различных навигационных требований, что является отличным дополнением к индексу решения задачи двойного решения.
Методология исследования: модели и эксперимент
Для выбора соответствующих RL-алгоритмов для данного исследования использовалось временное разностное обучение (Temporal Difference, TD), один из наиболее часто используемых алгоритмов без модели в литературе по RL. TD-обучение предполагает, что агенты изучают будущую ценность вознаграждения после действия и непрерывно корректируют предсказания до получения вознаграждения. В данном исследовании сравнивались три типа TD-моделей:
- TD(0): Базовая модель TD-обучения.
- TD(λ): Модель, включающая «след удовлетворения» (eligibility trace), который предполагает, что обновляются значения всех посещенных мест с течением времени, причем величина обновления зависит от частоты посещения.
- TD(1): Особый случай TD(λ), при котором значение посещенного места не уменьшается со временем, даже если оно не посещается повторно. Это подразумевает отсутствие забывания важности посещенных мест.
Эти три TD-алгоритма отличаются тем, как меняется важность посещенных мест со временем, что по сути отражает разные предположения о механизмах обновления памяти при пространственной навигации. Тема обновления памяти при пространственной навигации широко изучалась экспериментальными методами, но редко — с помощью вычислительных моделей.
В дополнение к модель-свободному обучению была построена модель-основанная для пространственной навигации. Предполагается, что люди, полностью полагающиеся на модель-основанную систему, обладают совершенной когнитивной картой, поэтому достаточно одной модель-основанной модели. Поскольку производительность человека, полностью полагающегося на идеализированные когнитивные карты, может быть неправдоподобной в большинстве навигационных сценариев, была создана гибридная модель для отражения гетерогенности или баланса между знанием, основанным на карте, и более эмпирическим знанием. Эта гибридная модель была разработана путем объединения наиболее эффективной TD-модели с модель-основанной моделью и добавления свободного параметра веса (ω) для учета относительной зависимости индивида от модель-основанного обучения.
Экспериментальный дизайн: Фиксированная и Случайная фазы
Результаты сравнения моделей могут проинформировать нас о том, насколько хорошо RL-модели соответствуют литературе по человеческой пространственной навигации. Как упоминалось выше, RL-модели генерируют по крайней мере два параметра (навигационные стратегии и последовательность использования этих стратегий), которые позволяют получить дополнительное понимание человеческой пространственной навигации по сравнению с традиционными методами. Для этого были созданы навигационные задачи с различными требованиями, и исследовалось, как эти различные навигационные сценарии модулируют навигационные стратегии и последовательность их использования, что отражает, как люди адаптируются к постоянно меняющейся среде, но редко исследовалось в литературе.
Конкретно, дизайн исследования учитывает тот факт, что не каждая целенаправленная навигационная задача решается наилучшим образом одинаково, что создает динамику, в которой индивидуальные различия также могут быть поняты с точки зрения того, как люди меняют свою модель обучения/поведения в зависимости от различных требований.
В данном исследовании участники сначала находили различные объекты в виртуальной среде из фиксированной начальной точки (Фиксированная фаза), а затем искали те же объекты в той же среде, но из различных случайных начальных точек (Случайная фаза). Исследователей интересовало, как относительный вес модель-основанного обучения (ω) и параметр исследования-эксплуатации (θ) изменяются в зависимости от опыта обучения и этих различных требований к задаче. В гибридной модели ω представлял собой среднее значение навигационной стратегии индивида за ряд навигационных попыток, а θ — последовательность использования этой стратегии в этих попытках (то есть степень, в которой индивид придерживается определенного способа решения задач перед лицом обратной связи и меняющихся требований).
Изучение ω и θ отдельно и совместно пролило бы важный свет на то, как люди адаптируются к навигационным сценариям с различными требованиями. Основываясь на манипуляции навигационными требованиями, были выдвинуты следующие гипотезы:
- ω, зависимость от модель-основанной системы или когнитивной карты, увеличится от Фиксированной к Случайной фазам из-за возрастающей знакомости среды и требований Случайной фазы, стимулирующих большее опору на знание, основанное на карте.
- Участники будут более склонны к исследованию или отклонению от своей стандартной стратегии в Случайной фазе из-за случайности и неопределенности. Следовательно, ожидалось, что θ увеличится от Фиксированной к Случайной фазам.
- Корреляции между ω и θ будут различаться в Фиксированной и Случайной фазах. В Фиксированной фазе, где начальная точка была всегда одинаковой, не было необходимости варьировать навигационную стратегию от попытки к попытке. В Случайной фазе, напротив, более эффективной стратегией было бы опираться на модель-свободную систему при начале из знакомого места, но опираться на модель-основанную систему при начале из незнакомого места (тем самым отдавая предпочтение вариации навигационной стратегии). Другими словами, предполагалось, что лучшие навигаторы будут последовательно использовать одну стратегию в детерминированных навигационных сценариях, в то время как они будут чаще менять свою стратегию в вероятностных навигационных сценариях. С этой теоретической точки зрения, гипотеза заключалась в том, что корреляция между ω и θ будет положительной в Фиксированной фазе (то есть, лучшие когнитивные картографы будут чаще придерживаться одной стратегии, чем не-картографы), но корреляция станет отрицательной в Случайной фазе (то есть, когнитивные картографы могут быть более гибкими в подходе к пространственным задачам).
Наконец, чтобы показать, что ω действительно отражает способность к пространственной навигации, был проведен корреляционный анализ ω с объективно измеренной эффективностью поиска пути, с гипотезой о значимой корреляции этих двух факторов.
Результаты: Сравнение моделей и индивидуальные различия
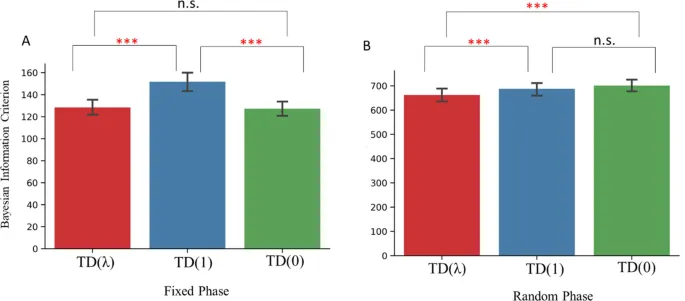
TD(λ) превзошла другие TD-модели в моделировании пространственной навигации.
Было проведено сравнение TD-семейства алгоритмов для моделирования навигационного поведения. В Фиксированной фазе однофакторный повторный дисперсионный анализ (ANOVA) показал значимое влияние модели на BIC (Bayes Information Criterion). Попарные t-тесты показали, что TD(λ) превзошла TD(1) и была сопоставима с TD(0). TD(0) превзошла TD(1). В Случайной фазе ANOVA также была значимой. TD(λ) превзошла TD(1) и TD(0). Значимой разницы между TD(0) и TD(1) не обнаружено. В целом, TD(λ) оказалась наилучшей моделью среди выбранных модель-свободных моделей и поэтому была использована для гибридной модели.
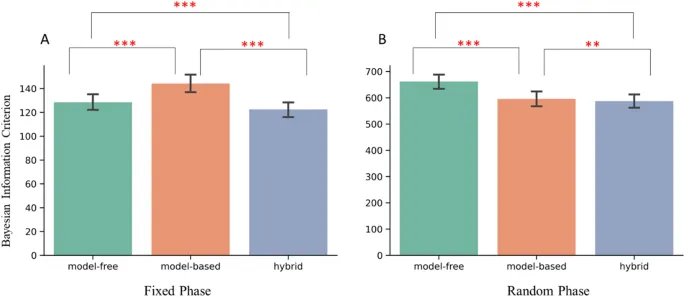
Гибридная модель превзошла модель-свободные и модель-основанные модели в обеих фазах.
Далее было проведено сравнение, какая модель (модель-свободная, модель-основанная или гибридная) обеспечила наилучшее соответствие в Фиксированной и Случайной фазах соответственно. В Фиксированной фазе ANOVA показала значимое влияние модели на BIC. Попарные t-тесты выявили, что гибридная модель превзошла модель-свободную и модель-основанную. Более того, модель-свободная модель превзошла модель-основанную. В Случайной фазе ANOVA также была значимой. Гибридная модель превзошла модель-свободную и модель-основанную. В отличие от результатов в Фиксированной фазе, модель-основанная модель превзошла модель-свободную в Случайной фазе. Очевидно, что гибридная модель оказалась наилучшей моделью в обеих навигационных фазах.
Корреляция между стратегией навигации (ω) и тенденцией к исследованию-эксплуатации (θ) модулировалась навигационными требованиями.
Было исследовано, как навигационная стратегия (ω) и исследование-эксплуатация (θ) модулируются навигационными требованиями. ω был значительно меньше в Фиксированной, чем в Случайной фазах, что предполагает, что в целом навигационное поведение участников в большей степени отражало модель-свободное обучение в Фиксированной фазе, чем в Случайной. С другой стороны, θ был значительно больше в Фиксированной, чем в Случайной фазах, что предполагает, что в целом участники использовали одну и ту же навигационную стратегию более последовательно в Фиксированной фазе, чем в Случайной.
Затем было проведено сравнение корреляций ω и θ в Фиксированной и Случайной фазах. В Фиксированной фазе эта корреляция была значимо положительной, что предполагает, что в Фиксированной фазе когнитивные картографы имели тенденцию к эксплуатации или к более последовательному использованию одной навигационной стратегии, чем последователи маршрутов. В Случайной фазе, напротив, эта корреляция стала значимо отрицательной, что предполагает, что в Случайной фазе когнитивные картографы имели тенденцию к исследованию или к более частой вариации своей навигационной стратегии, чем последователи маршрутов. В совокупности эти результаты подтвердили теоретическую основу исследования: когнитивные картографы отличаются от последователей маршрутов тем, что они гибки и эффективны не только благодаря использованию стратегий, основанных на когнитивной карте, но и благодаря адаптивному избеганию или принятию изменений стратегии в зависимости от различных навигационных требований.
Чтобы продемонстрировать, что ω также коррелирует с объективно наблюдаемой производительностью, было проведено сравнение ω и показателя чрезмерного расстояния (Excessive Distance, ED). Было обнаружено, что ω коррелирует с ED значительно в обеих фазах (Фиксированной и Случайной), поддерживая предположение о том, что независимо от навигационных требований, более модель-основанное поведение указывает на лучшую, более пространственно эффективную навигацию.
Обсуждение: новые перспективы в понимании навигации
Текущее исследование сравнило пять RL-моделей для характеристики человеческого поведения в навигационных задачах с различными требованиями. Было обнаружено, что гибридная модель, состоящая как из модель-свободного, так и из модель-основанного обучения, обеспечивала наилучшее соответствие в обеих навигационных задачах, несмотря на то, что она была оштрафована (при сравнении моделей) за свою сложность. Кроме того, посредством анализа индивидуальных различий было обнаружено, что зависимость от модель-основанной системы (ω) и вариативность использования стандартной стратегии (θ) увеличиваются по мере возрастания случайности поиска пути. Интересно, что корреляция между ω и θ модулировалась требованиями задачи, таким образом, что люди, в большей степени полагающиеся на модель-основанное обучение, чаще придерживались одной навигационной стратегии при поиске пути из одной и той же начальной точки, но чаще меняли свою навигационную стратегию при поиске пути из непредсказуемой начальной точки.
Роль обновления памяти при пространственной навигации
Сначала были сравнены три модель-свободные модели: TD(0), TD(λ) и TD(1), чтобы определить роль обновления памяти в пространственной навигации. Как было упомянуто ранее, TD(0) предполагает, что обновление памяти происходит только в наиболее недавно посещенном месте. С другой стороны, TD(λ) предполагает, что обновление памяти происходит во всех ранее посещенных местах, и объем обновления уменьшается со временем, если эти места не посещаются снова. TD(1) является особым случаем TD(λ), при котором обновление памяти одинаково для всех ранее посещенных мест, независимо от частоты их посещения. Результаты показывают, что, хотя модель TD(λ) не лучше, чем TD(0) в Фиксированной фазе, она превосходит другие модель-свободные модели в Случайной фазе. Эти выводы, подкрепленные превосходством гибридной модели в этой фазе над чисто модель-основанным подходом и свойствами TD(λ), предполагают, что, в той мере, в какой люди демонстрируют профили, подобные TD, их обновление пространственной памяти обычно происходит более непрерывно во всех ранее посещенных местах и масштабируется с частотой посещения при пространственной навигации, особенно когда поиск пути не является полностью детерминированным (т.е. в Случайной фазе). Эти результаты дополняют литературу по обновлению памяти при пространственной навигации и расширяют ее с помощью вычислительного подхода.
Гибридная модель как отражение индивидуальных различий
Как было отмечено ранее, возрастающая знакомость среды и требования Случайной фазы должны стимулировать участников в большей степени полагаться на знание, основанное на карте, в Случайной фазе. Действительно, при сравнении эффективности модель-свободного и модель-основанного обучения было обнаружено, что модель-свободное обучение превосходит модель-основанное в Фиксированной фазе, а модель-основанное — в Случайной фазе, что подтверждает валидность методов моделирования. Гибридная модель, с другой стороны, превосходит модель-свободную и модель-основанную модели в обеих фазах обучения, предполагая, что большинство индивидов не полагаются полностью ни на модель-свободную, ни на модель-основанную системы обучения ни в одном из сценариев, а находятся где-то посередине. Эти выводы согласуются с хорошо установленными данными о существенных индивидуальных различиях в пространственной навигации, согласно которым, хотя некоторые люди имеют ограниченное или почти совершенное конфигурационное знание своей среды, большинство находятся где-то посередине по различным объективным показателям. Насколько нам известно, это первое исследование, демонстрирующее, что гибридная RL-модель значительно превосходит модель-свободные и модель-основанные модели в явной моделировании человеческой пространственной навигации.
Новый взгляд на индивидуальные различия: стратегия и последовательность
После подтверждения соответствия результатов гибридной модели данным литературы, были извлечены два ключевых параметра для нового понимания индивидуальных различий в пространственной навигации в подобных задачах. Значительная часть литературы по человеческой пространственной навигации посвящена исследованию того, что делает хорошего навигатора. Критическим компонентом является навигационная стратегия (следование по маршруту или когнитивное картирование). Наиболее широко используемый метод измерения навигационной стратегии — это задача двойного решения, которая может упрощать сложные навигационные поведения, наблюдаемые у людей. Параметр ω гибридной модели указывает долю использования когнитивной карты в пространственной навигации по сравнению с следованием по известным маршрутам, и он значительно коррелирует с эффективностью навигации, но, что важно, не идентичен ей. Ключевое отличие ω от индекса решения задачи двойного решения заключается в том, что индекс решения указывает общую навигационную стратегию как черту на протяжении ряда попыток, в то время как ω может использоваться для указания общей стратегии (как это было сделано в текущем исследовании), а также для анализа на уровне каждой отдельной попытки, где каждая попытка имеет свое собственное значение ω. Другими словами, RL-модели могут обеспечить более тонкую меру навигационной стратегии по сравнению с традиционными методами.
Другой важный и уникальный вклад RL-моделей — это параметр тенденции к исследованию-эксплуатации (θ), который отражает, насколько последовательно человек использует свою стандартную стратегию, и который очень трудно оценить традиционными методами. Комбинация ω и θ обеспечивает мощный и уникальный способ дальнейшего понимания факторов, способствующих существенным индивидуальным различиям в пространственной навигации. Например, в данном исследовании изменение корреляции между ω и θ показывает, что когнитивные картографы чаще используют разные стратегии при увеличении случайности в задаче, что является новым открытием для понимания того, что делает хорошего навигатора. Это открытие также важно, поскольку, хотя само по себе модель-основанное поведение отражает навигационную гибкость, мы также видим, что люди с хорошими когнитивными картами и способностью к модель-основанному поведению являются теми же людьми, которые чаще соответствующим образом переключаются между фреймворками. Например, представьте себе, что вы поворачиваете за угол и видите знакомый набор ориентиров — возможно, знакомый путь вперед с этого момента, соответствующий модель-свободному поведению, на самом деле является наиболее эффективным вариантом, и наш вычислительный подход раскрывает, как хороший когнитивный картограф может осуществить этот переход. В совокупности эти результаты не только дают новую перспективу для понимания индивидуальных различий в человеческой пространственной навигации через призму навигационных стратегий и последовательности их использования, но также имеют важное значение для того, как можно улучшить пространственную навигационную способность как у людей, так и у искусственных агентов.
Методы
Участники
Сто двадцать шесть участников из Технологического института Джорджии и сообщества Атланты приняли участие в эксперименте, получив зачет за курс или денежное вознаграждение. Участники провели от 80 до 140 минут, выполняя эксперимент. Двенадцать участников испытывали чувствительность к движению и не закончили эксперимент. В результате сто четырнадцать участников (сорок шесть женщин) были включены в анализ данных. Анализ чувствительности к мощности показал, что наименьший размер эффекта, который наше исследование могло обнаружить, составил r = 0,26 при нашем финальном размере выборки (114), с целевой статистической мощностью (0,8) и уровнем альфа (0,05), что было достаточно чувствительно для обнаружения малых (0,2) — средних (0,5) эффектов согласно рекомендациям Коэна. Все участники (возраст 18–33 года) дали письменное согласие, и от всех участников было получено информированное согласие. Исследование было одобрено Комитетом по этике Технологического института Джорджии (код одобрения IRB: H17456). Все процедуры выполнялись в соответствии с институциональными рекомендациями.
Процедура исследования: навигация в виртуальной среде
Участники прошли практику в сетке из 4 × 4 комнат, чтобы ознакомиться со схемой управления и целью навигационной задачи. Трехмерная виртуальная среда была создана в Sketchup (www.sketchup.com), а навигационная задача была рендерена и реализована в игровом движке Unity 3D (https://unity.com/). Каждая комната представляла собой квадрат размером 10 × 10 виртуальных метров со стеной высотой 3 виртуальных метра. В каждой стене комнаты, кроме граничных, имелась проходимая дверь. Перемещение в виртуальной среде осуществлялось с помощью клавиатуры, обеспечивающей самостоятельное и непрерывное движение вперед-назад и вращение.
После практического занятия участники приступили к Фиксированной фазе.
Фиксированная фаза
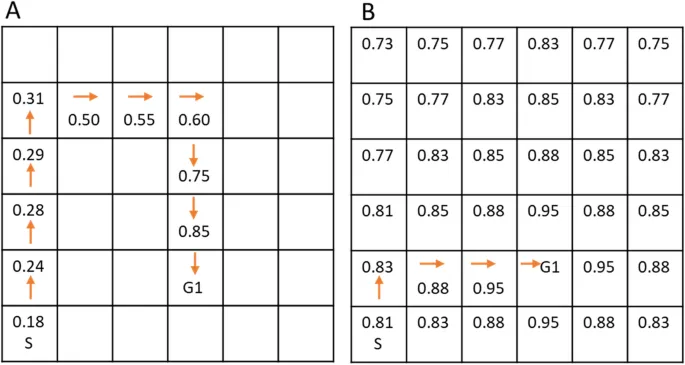
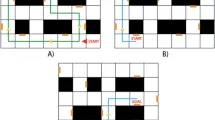
Для оценки навигационного обучения и его моделирования с помощью RL-алгоритмов участники учились перемещаться к скрытым местам в сетке из 6 × 6 комнат (Рис. 1). Каждая комната имела уникальный объект-ориентир (игрушки, мебель, транспортные средства и т. д.), служивший локальным ориентиром, который был виден только в пределах комнаты, но не из других комнат. Дистальные или глобальные ориентиры отсутствовали. В течение девяти попыток Фиксированной фазы участники обучались находить три конкретных целевых объекта (яблоко, банан и арбуз; по три попытки на каждый объект). Эти целевые объекты оставались в одних и тех же комнатах на протяжении всего эксперимента, но только целевой объект, который нужно было найти, был невидим в конкретной попытке (например, все объекты-ориентиры были видны в своих комнатах, но если целевым объектом в этой попытке было «яблоко», то банан не появлялся, даже если участники проходили через комнату с бананом). Это помогало избежать смешивания обучения разных пар «объект-цель» в одной попытке.
Как только участники находили целевой объект, они телепортировались в исходное положение и им давалась инструкция найти следующий целевой объект. Чтобы сделать эту Фиксированную фазу пригодной для модель-свободного обучения, участники всегда возвращались в одну и ту же исходную точку с тем же направлением взгляда, и каждый целевой объект находился в одном и том же порядке для всех участников (т. е. яблоко-банан-арбуз, а затем повтор для всех участников). Это похоже на изучение маршрутов от нового дома до продуктового магазина, кинотеатра и т. д. Фиксированная фаза была ограничена девятью попытками, чтобы минимизировать перенос пространственного обучения, то есть многие участники могут начать использовать короткие пути на основе модель-основанного обучения в Фиксированной фазе, когда они станут более знакомы со средой, потенциально подавляя нашу способность выявлять интересные индивидуальные различия.
Случайная фаза
Затем участники прошли «Случайную фазу» в той же виртуальной среде, что и в Фиксированной фазе. Важно отметить, что использование небольшого количества попыток в Фиксированной фазе в нашем дизайне не только гарантировало, что участники не выработали и не закрепили «короткие пути» во время Фиксированной фазы, но и оставило пространство для улучшения их точного конфигурационного знания среды и продолжения обучения на данном этапе. Таким образом, Случайная фаза представляла собой критический период, включающий проверку (1) пространственного переноса и гибкого принятия перспективы из Фиксированной фазы, а затем (2) дальнейшее обучение среде по новым процедурам. Случайная фаза была почти идентична Фиксированной фазе, за исключением того, что начальная точка и ориентация участников рандомизировались в каждой попытке (целевые объекты исключались из возможных начальных точек). Это похоже на поиск одного и того же продуктового магазина, кинотеатра и т. д. из различных точек в окрестности. Кроме того, порядок целевых объектов был псевдослучайным, так что каждый целевой объект находился один раз каждые три попытки, но не в предсказуемом порядке (например, банан-яблоко-арбуз-яблоко-арбуз-банан...). В Случайной фазе было семьдесят две попытки.
Для нашего исследования было критически важно, чтобы Фиксированная фаза всегда предшествовала Случайной для каждого участника. Во-первых, предшествующее знакомство со Случайной фазой могло бы побудить участников по умолчанию использовать модель-основанную стратегию, и эффективность в Фиксированной фазе могла бы быть на минимальном уровне. Во-вторых, Фиксированная фаза — путем повторения пар «старт-цель» — позволила участникам разработать один (или несколько) маршрутов к цели, которые затем были бы знакомы в Случайной фазе и могли бы стратегически использоваться из знакомого ориентира/комнаты (позволяя участникам демонстрировать изменения стратегии в Случайной фазе, когда в противном случае у них был бы только один [модель-основанный] вариант).
Конвейер анализа
Подробно описанный ниже, конвейер анализа был следующим: сначала мы подогнали навигационное поведение каждого участника к трем модель-свободным моделям и выбрали наилучшую (Рис. 3). Затем мы создали гибридную модель, объединив выигрышную модель-свободную модель и модель-основанную модель. Наконец, мы сравнили эффективность модель-свободной, модель-основанной и гибридной моделей (Рис. 4) и выбрали наилучшую модель для последующего анализа индивидуальных различий с использованием ее параметров (Таблица 1).
Обучение с подкреплением: модели и их математическое описание
Модели обучения с подкреплением
Как упоминалось во Введении, мы использовали пять различных моделей обучения с подкреплением для интерпретации навигационного поведения, отдельно для Фиксированной и Случайной фаз, и отдельно для каждого участника. Мы моделировали последовательность выборов участников (какие комнаты входить), сравнивая их шаг за шагом с теми, которые предсказывались различными моделями. Поскольку у нас была сетка 6 × 6, навигационная задача состояла из 36 состояний (комнат), и в каждом состоянии субъекты могли выбирать из четырех действий (вверх, вниз, влево или вправо). Навигационная задача включала три вознаграждения (три целевых объекта), и целью всех моделей было изучить функцию ценности состояния-действия Q(s,a) для каждой пары состояние-действие (т. е. в каком направлении двигаться, находясь в определенной комнате, чтобы максимизировать вознаграждение) для каждого целевого объекта (Рис. 2). Мы предполагали отсутствие интерференции или обобщения между (неявными) вознаграждениями трех целевых объектов, и поэтому каждый алгоритм был разделен на три независимых набора задач и функции ценности, по одному для каждого целевого объекта.
Модель-свободное обучение с подкреплением
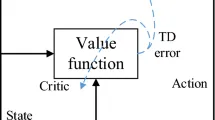
Для получения дальнейшего понимания модель-свободного поведения в человеческой пространственной навигации и выбора лучшей модели для гибридной модели, мы создали три TD-модели: TD(0), TD(λ) и TD(1). Сначала мы опишем и приведем уравнения для TD(0), а затем объясним различия между тремя моделями. Уравнения того, как значения Q обновлялись в TD-модели, были следующими:
$$Q_{TD}(s_t, a_t) = Q_{TD}(s_t, a_t) + lpha elta uad (1)$$
где $$elta = r_{t+1} + Q_{TD}(s_{t+1}, a_{t+1}) - Q_{TD}(s_t, a_t) uad (2)$$
Здесь t обозначает текущее состояние и действие, а t+1 обозначает будущее состояние и действие, выбранное функцией softmax (см. ниже). Уравнение (1) показывает, что значение Q, связанное с текущим состоянием (Q(s(t), a(t))), обновляется на величину ошибки δ, скорректированную скоростью обучения α. Уравнение (2) показывает, что ошибка δ определяется вознаграждением, связанным с будущим состоянием (r(t+1)), плюс разница между значениями Q, связанными с будущим и текущим состояниями. Значение Q каждой пары состояние-действие инициализировалось как 0 в начале эксперимента, и значения Q переносились между попытками и фазами.
Чтобы определить, какое действие предпринять на основе значений Q, связанных с будущими состояниями и действиями, мы вычислили вероятность выбора действия на основе функции softmax:
$$p_{t+1} = rac{exp^{θ Q(s_{t+1}, a)}}{um_{a' n A} exp^{θ Q(s_{t+1}, a')}} uad (3)$$
θ — это обратная температура, контролирующая степень случайности при выборе действия участниками, а a' обозначает возможные будущие действия из текущего состояния. θ было ограничено диапазоном от 1 до 15, и чем выше θ, тем более детерминированным был выбор действия и, следовательно, более эксплуататорским.
По сравнению с TD(0), TD(λ) добавляет след удовлетворения e к обновлению значения Q, который представляет собой временную запись того, как часто посещалось каждое состояние. След удовлетворения для каждой пары состояние-действие устанавливался равным 0 в начале каждой попытки. Уравнения того, как значения Q обновлялись в TD(λ), были следующими:
$$Q_{TD(ambda)}(s_t, a_t) = Q_{TD(ambda)}(s_t, a_t) + lpha elta e_t(s, a) uad (4)$$
где $$e_t(s, a) = ambda e_{t-1}(s, a) + athbf{I}(S_t=s, A_t=a) uad (5)$$
I — это индикаторная функция, которая равна 1, когда условие внутри нее истинно, и 0 в противном случае. λ ограничено диапазоном от 0 до 1, поэтому Уравнение (5) указывает, что чем реже посещается состояние, тем меньше обновление значения Q, связанного с этим состоянием. TD(1) является особым случаем TD(λ), который заставляет каждое посещенное состояние получать одинаковое обновление, независимо от того, как часто оно посещалось.
При соотнесении этих RL-алгоритмов с человеческими системами памяти, TD(0) предполагает, что обновление памяти, представленное обновлением значения Q, происходит только в наиболее недавно посещенном месте, тогда как TD(λ) предполагает, что обновление памяти происходит во всех ранее посещенных местах непрерывно, и такое обновление масштабируется с частотой посещения. TD(1) отличается от TD(λ) тем, что обновление памяти не масштабируется с частотой посещения.
Модель-основанное обучение с подкреплением
Для модель-основанного алгоритма использовалось динамическое программирование, которое изучало расположение среды (т. е. когнитивную карту), вычисляя значения Q путем обхода всех возможных комнат и направлений для определения цели (Рис. 2). Мы вычисляли значения Q на основе процесса «сканирования», завершающегося в целевых местах. Сначала мы инициализировали все QMB(s) нулями в начале Фиксированной фазы. Затем для всех состояний и смежных пар состояние-действие мы итеративно выполняли следующее:
$$Q_{MB}(s) eftarrow um_{a} i(a|s) + um_{s', r} p(s', r|s, a) [r + amma Q_{MB}(s')] uad (6)$$
где (a|s) — вероятность выбора действия a из состояния s в соответствии с политикой исследования-эксплуатации. p(s', r|s, a) — вероятность попадания в состояние s' и получения вознаграждения r при данном состоянии и действии. Алгоритм имел один фиксированный параметр γ, установленный на 0,8. Окончательные модель-основанные значения (QMB) — это значения после сходимости алгоритма (т. е. разница между каждым QMB в текущей и предыдущей итерации была меньше 0,0001). Концептуально, модель-основанные значения отражали значения состояние-действие, как если бы у человека была идеальная когнитивная карта, и поэтому значения Q не обновлялись и были одинаковы для всех участников.
Гибридная модель
Мы реализовали гибридную модель как взвешенную линейную комбинацию значений из наиболее эффективного модель-свободного алгоритма среди участников и модель-основанного алгоритма:
$$Q_{hybrid} = (1-mega) Q_{MF} + mega Q_{MB} uad (7)$$
где ω представляет собой баланс между модель-свободным и модель-основанным поведением. Чем выше ω, тем лучше навигационное поведение может быть охарактеризовано как основанное на модели или когнитивной карте.
Модель-фитинг и сравнение
Для каждого алгоритма мы вычисляли отрицательный логарифм правдоподобия (Negative Log-Likelihood, NLL) наблюдаемых выборов (a_t) путем суммирования логарифмов Уравнения (3) для выбранного действия в каждой из n попыток, следующим образом:
$$NLL(athbf{X}) = um_{t=1}^{n} og p(a_t|athbf{X}) uad (8)$$
где вектор X обозначает свободные параметры модели, а NLL вычислялся отдельно для Фиксированной и Случайной фаз. Наилучшие параметры затем вычислялись как те, которые минимизируют отрицательный логарифм правдоподобия:
$$athbf{X}_{MLE} = rg in_{athbf{X}} NLL(athbf{X}) uad (9)$$
Подгонка моделей выполнялась с использованием оптимизационной функции из SciPy. Сравнение моделей проводилось путем вычисления Байесовского информационного критерия (BIC) для каждой модели для каждого участника, отдельно для Фиксированной и Случайной фаз.
$$BIC = k og n + 2 athbf{X}_{MLE} uad (10)$$
где k — количество свободных параметров в модели, а n — количество попыток в данных. Было два свободных параметра (α и θ) в моделях TD(0) и TD(1), и три свободных параметра (α, θ и λ) в TD(λ). Был один свободный параметр θ в модель-основанной модели, и четыре свободных параметра (α, θ, λ и ω) в гибридной модели.
Чрезмерное расстояние
Чрезмерное расстояние (Excessive Distance, ED) широко используется как показатель эффективности поиска пути, который определяется как:
$$( ext{фактическое пройденное расстояние} - ext{оптимальное расстояние}) / ext{оптимальное расстояние}.$$
ED, равный 0, означает идеальную эффективность поиска пути (фактическое пройденное расстояние равно оптимальному), а индекс 1 означает, что фактическое пройденное расстояние на 100% больше оптимального. В нашем исследовании, поскольку состояния и переходы состояний были разделены на комнаты, мы использовали количество комнат для представления расстояния.
Выводы
В текущем исследовании мы сравнили пять моделей обучения с подкреплением при интерпретации человеческого навигационного поведения. Было обнаружено, что гибридная модель обеспечивает наилучшее соответствие данным независимо от требований задачи, и она проливает важный свет на то, как требования задачи модулируют навигационную стратегию (баланс между модель-свободным и модель-основанным), последовательность использования и взаимодействие между этими двумя факторами. В целом, мы показываем, что модели обучения с подкреплением обеспечивают более тонкую характеристику навигационной стратегии в непрерывном режиме, основанную на предыдущей навигационной истории индивида, что не только дополняет и расширяет существующие методы изучения индивидуальных различий в пространственной навигации, но и предполагает, что последовательность использования навигационной стратегии в зависимости от навигационных требований является важным фактором, определяющим хорошего навигатора.
Ограничения
Последовательность фаз
В текущем исследовании Фиксированная фаза всегда предшествовала Случайной. Как подробно описано в «Методах», это было особенно важно для дизайна и текущих исследовательских вопросов. Тем не менее, очевидным шагом для последующих исследований будет использование более длительного дизайна, включающего переключения обратно к попыткам Фиксированной фазы (либо чередующиеся со Случайными, либо заблокированные) на разных этапах обучения, чтобы понять, как опыт навигации в нашей среде более гибкими способами (Случайная фаза) может повлиять на нашу внутреннюю модель, используемую при навигации по более знакомым взаимосвязям между местами.
Структура среды и глобальные ориентиры
Другим важным соображением при дизайне было то, что структура среды представляла собой правильную сетку без каких-либо глобальных ориентиров. Эти атрибуты в совокупности затрудняют ориентацию в глобальном пространстве и делают ее зависимой от изучения взаимосвязей между соседними комнатами. С одной стороны, мы рассматриваем это как сильную сторону дизайна, особенно в контексте изучения ассоциаций «состояние-состояние» в модели обучения с подкреплением. И действительно, существует множество сценариев из реальной жизни, имеющих общие черты с нашей виртуальной средой — навигация по закрытым пространствам, таким как внутренние помещения отеля, торгового центра или больницы, и в меньшей степени карты метро. Кроме того, когда мы находимся среди высоких зданий на городских улицах, наш обзор ориентиров с большей вероятностью будет ограничен видимым пространством и местным масштабом, что в некоторой степени похоже на ограничения текущей задачи (но не полностью).
Тем не менее, другим очевидным шагом вперед в этом исследовании является изучение того, влияет ли форма среды и наличие глобальных ориентиров на картину результатов, описанных в текущем исследовании. Можно предположить, что глобальные ориентиры, облегчая выбор коротких путей, уменьшат склонность некоторых людей использовать знакомые сегменты маршрута вместо исследования при переходе к Случайной фазе. С другой стороны, опираясь на некоторые из наших других недавних выводов, может быть и так, что лучшие навигаторы — это те, кто гибко использует эти дополнительные подсказки в большей степени, чем худшие навигаторы. В этом случае интригующим следствием текущих результатов является то, что такие подсказки могут усугубить различия между более и менее модель-основанными индивидами и их вариативность в стратегии, в зависимости как от требований задачи, так и от доступности подсказок. Будущие исследования могли бы проверить эти взаимодополняющие идеи.





