Интересное сегодня


Введение
Феномен мудрости толпы (Wisdom of Crowds, WOC), который предполагает, что совокупная информация от группы может превзойти точность любого отдельного человека, включая экспертов в предметной области, наблюдался в различных контекстах. Яркий популярный пример происходит из телевизионного игрового шоу «Кто хочет стать миллионером», где участникам предлагается возможность проконсультироваться с экспертом и получить коллективные ответы от живой аудитории в студии на заданный вопрос. На пике популярности шоу ответы экспертов были правильными в 65% случаев, в то время как аудитория была права в 91% случаев. Примеры явления WOC в других условиях включают идентификацию и классификацию кратеров на поверхности Марса, оценку корпоративных доходов, предсказание победителей выборов, оценку высоты горы и многие другие.
Подавляющее большинство исследований для оценки мудрости толпы involve числовые задачи оценки (то есть задачи numerosity), такие как угадывание количества конфет в стеклянной банке и оценка количества черных точек на белом фоне. Однако предыдущие работы также оценивали его применимость к порядковым задачам, таким как recall правильного порядка списка после его перемешивания и упорядочивание нескольких изображений на основе количества точек, которые они содержат (то есть от изображения с наименьшим количеством до изображения с наибольшим количеством). Но только недавно исследователи начали рассматривать объединение этих двух модальностей оценок в одной задаче. Хотя первоначальные результаты кажутся promising, необходимы дополнительные усилия в этом направлении, чтобы определить, как сбор и агрегация таких мультимодальных входных данных могут further enhance эффекты WOC.
Методология исследования
Дизайн эксперимента
Для решения исследовательских вопросов мы разработали веб-исследование через Amazon Mechanical Turk (N=600) для краудсорсинга упорядочивания различных наборов изображений на основе количества точек, содержащихся в каждом изображении. Всего в наборе 30 изображений с различным количеством черных точек, ranging от 50 до 79, случайным образом scattered на белом фоне. Каждому участнику назначались четыре меньшие задачи упорядочивания (то есть подмножества изображений), состоящие из псевдослучайного выбора 2, 3, 5 и 6 изображений соответственно; с каждым из четырех размеров задач связан different набор из 30 изображений. Конкретные подмножества назначались участникам таким образом, чтобы все 30 изображений просматривались одинаковое количество раз per задача.
Интерфейсы сбора данных
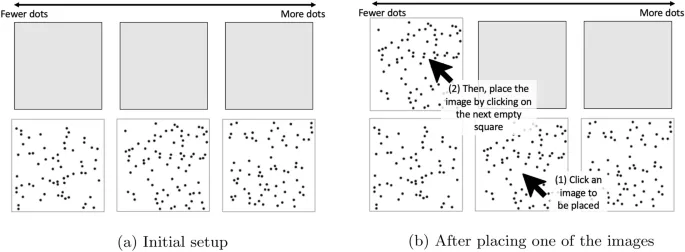
В задаче порядковой оценки назначенные изображения предоставлялись вдоль нижнего ряда интерфейса. Участники нажимали на каждое изображение, а затем на пустой квадрат в верхнем ряду, чтобы расположить изображения в порядке возрастания количества точек, которые они содержат. Затем участники переходили к задаче числовой оценки, которая заключалась в угадывании общего количества точек на каждом из изображений, которые они видели в предыдущей задаче упорядочивания.
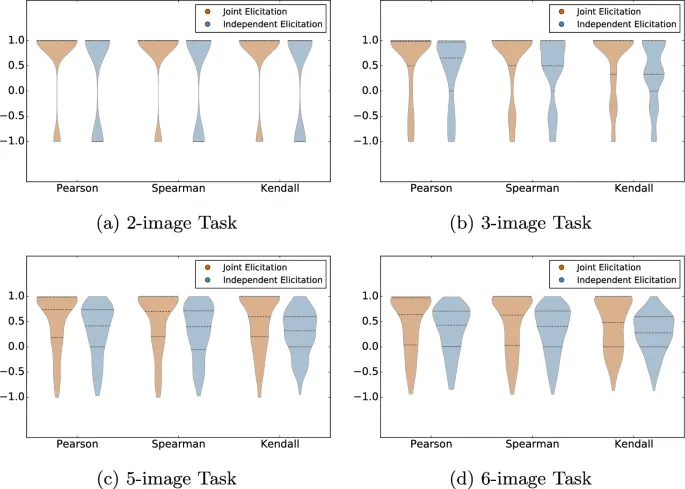
Для половины участников эта информация собиралась совместно (jointly), то есть все назначенные изображения показывались side-by-side так, как участник расположил их в задаче упорядочивания, с текстовым полем под каждым изображением для сбора числовых оценок. Для другой половины участников числовые оценки собирались независимо (independently); то есть каждое назначенное изображение показывалось индивидуально и в random порядке, с полем ввода под ним. По сути, интерфейс совместного сбора designed для повышения эффективности и удобства сбора двух модальностей входных данных, в то время как интерфейс независимого сбора intended для ослабления potential негативных impacts доступа к своим собственным более ранним оценкам.
Результаты исследования
Индивидуальная производительность
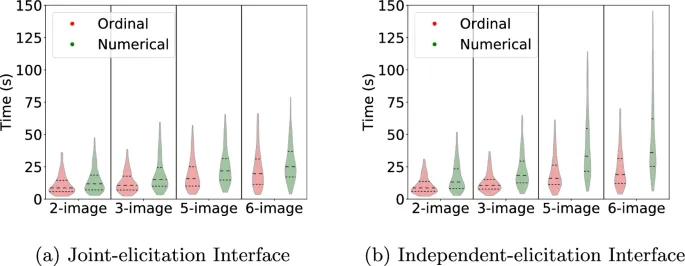
Чтобы выделить основные различия между интерфейсами сбора, мы сначала углубились в два аспекта на уровне individual участника: время выполнения и степень self-contradiction. Время выполнения для каждого из четырех размеров задач и двух интерфейсов summarized на рис. 3. Выбросы были исключены для улучшения анализа и визуализации.
Чтобы оценить, являются ли различия во времени выполнения между задачами числовой и порядковой оценки statistically значимыми, мы провели two-sample t-test на среднее время выполнения для каждого из четырех размеров задач и двух интерфейсов. С интерфейсом независимого сбора средние различия между временем выполнения задач порядковой и числовой оценки составили 8.12, 15.28, 27.54 и 38.99 секунд для задач с 2, 3, 5 и 6 изображениями соответственно; с интерфейсом совместного сбора соответствующие средние различия составили 4.86, 15.42, 5.49 и 14.49 секунд.
Коллективная производительность
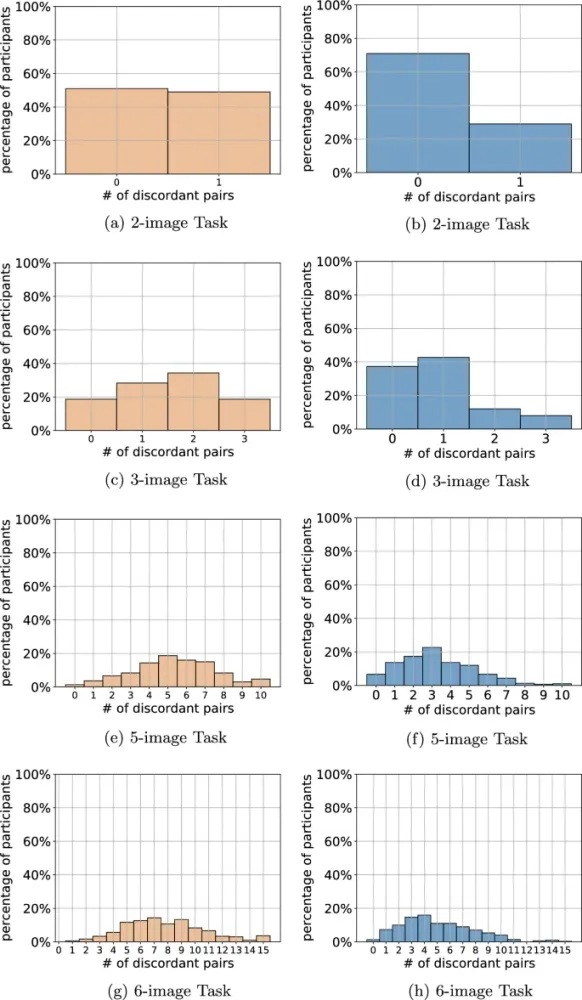
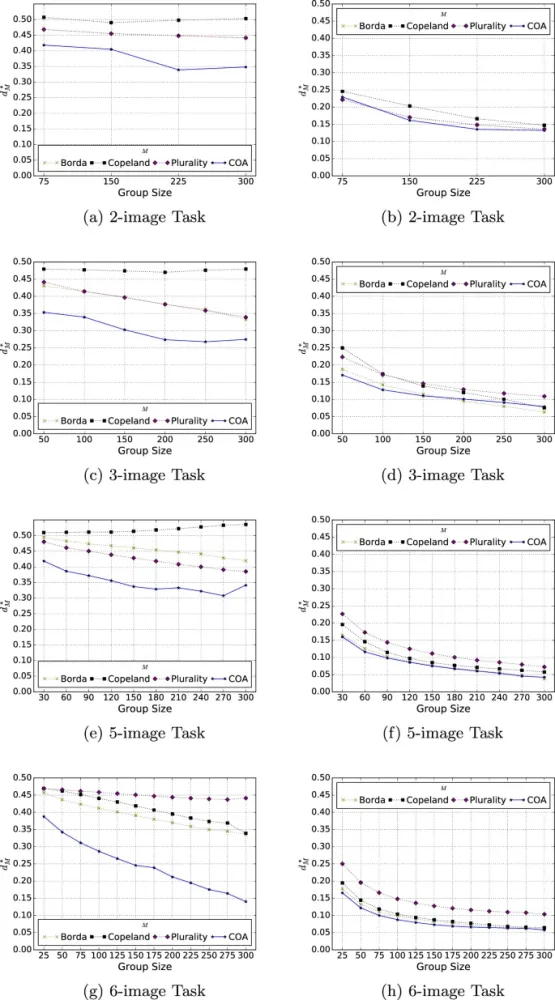
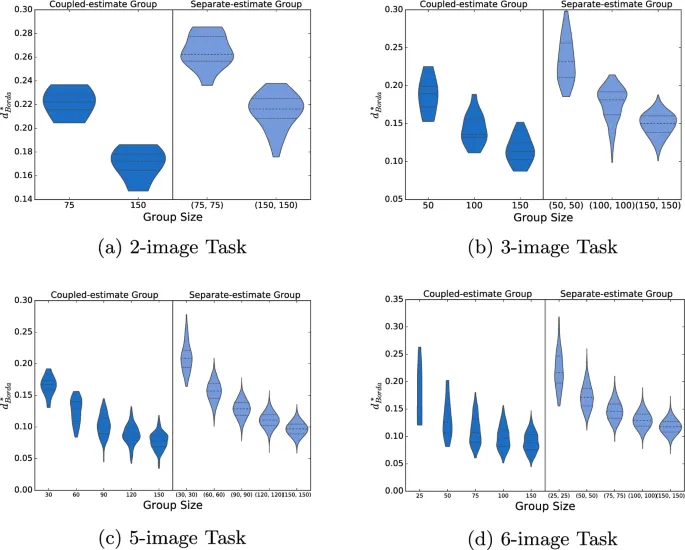
Коллективная производительность рассчитывалась путем агрегации оценок участников с использованием методов, описанных в разделе «Методы агрегации». Результаты представлены на рис. 6 с помощью eight двумерных графиков, соответствующих каждой возможной комбинации размера задачи и интерфейса. На каждом графике ось x указывает размер группы, который регулируется путем взятия подмножеств входных данных. Ось y reports расстояние Кемени-Снелла (Kemeny-Snell distance) (то есть количество discordant пар) между каждой коллективной оценкой и ground truth.
Результаты поддерживают эффект мудрости толпы, то есть точность tends улучшаться по мере агрегации большего количества индивидуальных оценок. Это справедливо для обоих интерфейсов и across всех tested размеров задач и методов агрегации. Однако коллективные оценки, связанные с интерфейсом независимого сбора, significantly превзошли those, связанные с интерфейсом совместного сбора; на самом деле, почти каждая коллективная оценка, полученная с интерфейсом независимого сбора, более accurate, чем лучшая коллективная оценка, полученная с интерфейсом совместного сбора.
Обсуждение результатов
Практические implications
Это исследование вносит вклад в понимание того, как совместный сбор и агрегация мультимодальных входных данных могут enhance эффекты мудрости толпы на порядковых задачах. Во-первых, мы показываем, что модальность сбора входных данных влияет на качество информации и any последующую агрегацию thereof. Участники, которые предоставляли числовые оценки independently от своих порядковых оценок over подмножеству изображений с точками (то есть те, кто received интерфейс независимого сбора), предоставили considerably лучшие оценки, чем те, кто completed их совместно.
Во-вторых, мы демонстрируем, что enhanced эффекты WOC от мультимодальных оценок, задокументированные herein, не reserved для optimization-based методов. Они также accessible к commonly используемым правилам голосования, following подходящее преобразование данных, relevant к порядковым задачам. Действительно, хотя оптимизационная модель produced лучшие коллективные оценки, когда relatively few входных данных было available, модифицированные правила голосования yielded nearly тот же уровень точности за доли секунды, и они entailed несколько строк кода, reproducible с настольными программами.
Теоретическая значимость
В-третьих, вычислительные эксперименты highlight добавленную стоимость совместного сбора multiple модальностей оценок от single группы участников, as opposed к mixing входных данных от двух групп, которые each предоставляют оценки single но distinct модальности. Первый tends yield лучшие коллективные оценки даже когда there is equal или higher количество общих оценок, агрегированных от последнего. Иными словами, дизайн совместной оценки одной группы enables извлечение оценок более высокого качества с меньшими ресурсами.
В-четвертых, другой вклад relates к burgeoning концепции мудрости толпы в одном разуме (wisdom of the inner crowd), которая holds, что лучшие индивидуальные (и коллективные) оценки могут be attained путем сбора и агрегации multiple оценок от каждого участника в толпе. Предыдущие работы lent поддержку этому явлению mostly путем сбора оценок относительно того же вопроса в различные временные интервалы. Более advanced реализации demonstrated, что сбор ответов на логически equivalent перефразирование original вопроса outperforms задавание того же вопроса в separate случаях. Метод сбора мультимодальных входных данных, представленный herein, further поддерживает эту идею.
Заключение и дальнейшие исследования
Результаты этого исследования вызывают compelling вопросы для further исследований. Для начала, представленное исследование used числовые оценки для complement и enhance коллективные порядковые оценки на порядковых задачах, но оно не углубилось в обратное, то есть, whether и how порядковые оценки могут be leveraged для задач numerosity. Кроме того, представленные задачи involved человеческие вычислительные деятельности с known ground truth — то есть упорядочивание наборов изображений известно a priori. Во многих реальных задачах, которые harness силу краудсорсинга и коллективного интеллекта, ground truth может быть не immediately available — например, предсказание акций — или он может не существовать altogether — например, краудсорсинговое мнение. Следовательно, интересное направление исследований — изучить, будут ли предложенные методы beneficial в those контекстах as well.
Наконец, практические benefits мультимодальной агрегации мотивируют теоретические вопросы beyond мудрости толпы, включая socio-theoretic анализ правил голосования, которые принимают как числовые, так и порядковые входные данные, и изучение polyhedral структуры, лежащей в основе оптимизационной модели.