Интересное сегодня
Нейронные корреляты обработки локальных зависимостей в парадигме статистического обучения
Статистическое обучение — это неявный механизм извлечения закономерностей из окружающей среды. Многочисленные исследования посвящены нейронным основам статистического обучения. Однако то, как мозг реагирует на нарушения слуховых закономерностей, основанных на предыдущем (неявном) обучении, требует дальнейшего изучения. В данном исследовании мы использовали функциональную магнитно-резонансную томографию (фМРТ) для изучения нейронных коррелятов обработки событий, которые являются нерегулярными на основе изученных локальных зависимостей. Предъявлялся поток последовательных звуковых триплетов. Неизвестно участникам, триплеты были либо (а) стандартными, то есть триплетами, заканчивающимися звуком высокой вероятности, либо (б) статистическими отклонениями, то есть триплетами, заканчивающимися звуком низкой вероятности. Участники (n = 33) прошли фазу обучения вне сканера, за которой последовала сессия фМРТ. Обработка статистических отклонений активировала набор областей, охватывающих верхнюю височную извилину билатерально, правую глубокую лобную покрышку, включая латеральную орбитофронтальную кору, и правую премоторную кору. Наши результаты демонстрируют, что нарушение локальных зависимостей в парадигме статистического обучения не только задействует сенсорные процессы, но вместо этого напоминает паттерн активации при обработке локальных синтаксических структур в музыке и языке, отражая адаптацию в реальном времени, необходимую для предсказательного кодирования в контексте статистического обучения.
Введение
Наш внешний мир и наша жизнь в целом далеки от случайного континуума событий, а скорее содержат определенную степень структуры и закономерности. Люди наделены способностью распознавать закономерности и формировать предсказания о будущих событиях. В последние годы статистическое обучение было предложено как ключевой механизм для обнаружения закономерностей (обзоры см. в ссылках 2, 3, 4). Ключевая роль предсказания в восприятии, познании и действии хорошо установлена 5, 6, но недавние исследования также выявили центральную роль предсказания в статистическом обучении 7, 8, 9. С этой точки зрения, фундаментальный вопрос, который возникает, заключается в том, как мозг реагирует на нарушения предсказаний, которые возникают в результате неявного статистического обучения. Неявная адаптация к закономерностям изучалась в основном в двух исследовательских традициях: неявное обучение и статистическое обучение, которые используют разные экспериментальные парадигмы, но, как утверждается, изучают один и тот же лежащий в основе механизм 10, 11. Обе исследовательские парадигмы изучали нейронные основы обработки структурированных стимулов, в основном в контексте приобретения языка в отношении изучения грамматических правил или сегментации слов. Хотя эти парадигмы ответили на важные вопросы относительно лежащих в основе механизмов неявного статистического обучения, свидетельств того, как мозг реагирует на неожиданные события, происходящие в текущем потоке стимулов и нарушающие неявно усвоенные закономерности, мало. Исследования не с использованием фМРТ 12, 13 изучали влияние предыдущих неявных знаний на обработку непредсказуемых событий. С другой стороны, реакции на неожиданные события были основным направлением исследований «необычных» стимулов с использованием классического ответа на несоответствие, известного как негативность несоответствия (MMN 14; обзор см. в ссылке 15). Тем не менее, эти исследования не фокусировались на реакциях мозга на отклоняющиеся события в контексте статистического обучения. Наш исследовательский вопрос затрагивает как механизмы неявного статистического обучения, так и обнаружение отклонений в одной и той же парадигме, и, таким образом, отличается от предыдущих исследований в обеих областях.
Исследования в области неявного и явного обучения использовали парадигму обучения искусственным грамматикам для изучения нейронных механизмов обработки структур стимулов с локальными (например, «Мальчик был высокий.»; 16, 17, 18, 19, 20, 21, 22, 23) или нелокальными зависимостями (например, «Мальчик [которого поцеловала девочка] был высокий.»; 20, 21, 23, 24, 25, 26). В настоящем исследовании мы использовали локальные зависимости, однако наш исследовательский вопрос выходил за рамки изучения того, как мозг обрабатывает локальные зависимости. Основное внимание в нашем исследовании было уделено реакциям мозга на отклоняющиеся локальные зависимости, возникающие среди стандартных, которые, как следствие, нарушают предсказания. Предыдущие нейровизуализационные исследования показали, что обработка или нарушения локальных зависимостей активируют глубокие лобные и верхние височные области 20, 21, в то время как другие сообщают также активацию области Брока 16, 17, 18, 19. Исследования обучения искусственным грамматикам изучали нейронные корреляты нарушений грамматических зависимостей, но они использовались в качестве тестовых элементов для целей классификации во время сессии тестирования. Таким образом, еще предстоит изучить, как мозг реагирует на отклоняющиеся локальные зависимости, встроенные в поток стандартных, в рамках парадигмы статистического обучения.
Исследования в области статистического обучения — насколько нам известно — не изучали реакции мозга на нарушения предсказаний, основанных на изученных статистических закономерностях. Вместо этого основным направлением этих исследований было распознавание границ слов в потоке объединенных искусственных слов без пауз, явление, известное как сегментация слов 27. Основные результаты фМРТ-исследований статистического обучения заключаются в том, что обучение и распознавание слов поддерживаются верхней височной извилиной как для слуховых 28, 29, 30, 31, 32, так и для визуальных 33 стимулов, иногда нижней лобной извилиной 28, 29, 30, 32, 33 и базальными ганглиями 28, 30, 35. Роль нижней лобной извилины в статистическом обучении также была продемонстрирована в исследовании электроэнцефалографии с локализацией источников 36. В этих исследованиях манипулировались переходные вероятности между словами, чтобы вызвать границы слов, на том основании, что низкая переходная вероятность указывает на границу слова. Тем не менее, фМРТ-исследования статистического обучения не манипулировали переходными вероятностями внутри слов (например: «pretty baby» против «pretty babies»). Текущая парадигма была разработана для устранения этого пробела с вариантом традиционной парадигмы статистического обучения, где переходная вероятность варьировалась между триплетами и внутри триплетов, и таким образом изучались реакции мозга на неожиданные события с низкой вероятностью, происходящие среди ожидаемых событий с высокой вероятностью (на основе предыдущего неявного обучения). Подобная парадигма обучения использовалась для исследования визуального статистического обучения с использованием вызванных потенциалов мозга 37, 38.
То, как мозг реагирует на неожиданные события, процесс, также известный как обнаружение отклонений, традиционно исследовался в исследованиях «необычных» стимулов с использованием классического ответа MMN. Предыдущие нейровизуализационные исследования «необычных» стимулов показали, что непредсказуемые события активируют корковую сеть, включающую верхнюю височную извилину (STG) и иногда нижнюю лобную извилину (IFG), заметно схожую с той, что наблюдается при статистическом обучении 39, 40, 41, 42, 43, 44, 45, 46. Важно отметить, что восприятие отклоняющегося события требует прежде всего установления в памяти репрезентации обычного события. В парадигме обнаружения сенсорных отклонений (такой как типичная парадигма MMN с физическим отклонением, например, отклонением по высоте тона) установление в памяти репрезентации стандартных стимулов требует нескольких секунд, тогда как в парадигме статистического обучения это требует более длительного воздействия потока стимулов. Таким образом, в исследованиях «необычных» стимулов предсказательные процессы включают закономерности, которые устанавливаются от момента к моменту и представляют собой информацию, накопленную за временной шкале секунд, и в этом отношении они отличаются от закономерностей, установленных во время парадигмы статистического обучения. На этом основании, в текущей парадигме статистического обучения, приобретение закономерностей отличается, поскольку оно требует более длительных периодов обучения, и в этом контексте изучаются мозговые корреляты обнаружения отклонений.
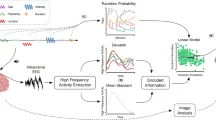
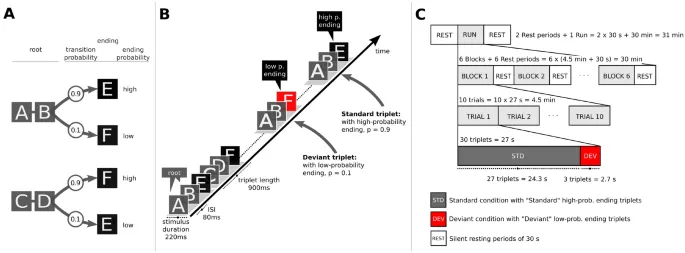
В отличие от многих предыдущих исследований неявного статистического обучения, мы подошли к теме с относительно новым методом, а именно разработали парадигму, которая является слиянием парадигм неявного статистического обучения и обнаружения отклонений (см. Рис. 1) и была разработана на основе предыдущего исследования 47. Стимулы были организованы в триплеты, в которых переходная вероятность к последнему элементу была либо высокой (p = 0,9), либо низкой (p = 0,1). Триплеты с высокой вероятностью окончания назывались «Стандартными», а триплеты с низкой вероятностью окончания — «Отклоняющимися». Мы определили три гипотезы. Во-первых, помимо слуховой коры, ответы на несоответствие, отражающие обнаружение слуховых отклонений, активировали бы области, связанные с нарушением локальных зависимостей 16, 17, 18, 19, 20, 21, 22, в частности височную и нижнюю лобную кору, опосредованную частями премоторной коры. Область исследования заключалась в индукции неявного статистического обучения как вне, так и внутри сканера, и поэтому наша вторая гипотеза заключалась в том, что паттерн активации будет развиваться в течение продолжительности сессии, раскрывая временной ход эффектов статистического обучения. Другими словами, мы предположили, что участники все еще будут учиться внутри сканера. В-третьих, задействованная корковая сеть будет отличаться у «хороших» и «плохих» учеников, ранжированных по их результатам в поведенческой задаче.
Результаты
Поведенческие данные вне сканера и внутри сканера
Тест на знакомство (вне сканера)
В конце каждого блока экспозиции (перед сессией фМРТ) проводился тест на знакомство, чтобы проверить, усвоили ли участники лежащие в основе закономерности стимулов. Ожидалось, что участники классифицируют триплеты с высокой вероятностью окончания («Стандартные» триплеты) как более знакомые по сравнению с триплетами с низкой вероятностью окончания («Отклоняющиеся» триплеты; см. «Методы»). Участники достигли среднего балла 66,5% (SEM = 2,5%) при классификации стандартных триплетов как более знакомых (производительность значительно отличалась от случайного уровня, p < 0,001).
Нейронные результаты
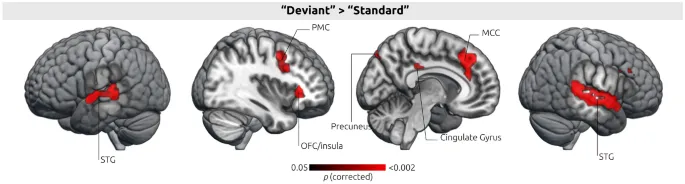
Обработка статистических отклонений. Контраст «Стандартный» против «Отклоняющийся» триплеты, т.е. контраст триплетов с низкой вероятностью окончания («Отклоняющийся») и с высокой вероятностью окончания («Стандартный»), показал активацию в слуховой коре (STG) билатерально, орбитофронтальной коре (OFC) глубокой лобной покрышки / правом переднем верхнем полюсе островка, передней части средней поясной извилины (MCC), включая область a24b, переднюю поясную зону (RCZ), дополнительную премоторную кору (preSMA), левую предклинье и левое скорлуповидное ядро (см. Рис. 2 и Таблицу 1; результаты были скорректированы на множественные сравнения с пороговым контролем FDR на уровне p < 0,05).
Влияние времени обучения. Как мы и предполагали, паттерн активации изменился в течение всего эксперимента, что указывает на продолжающееся обучение внутри сканера. В частности, мы обнаружили, что активация в слуховой коре и орбитофронтальной коре была сильнее в начале эксперимента, тогда как активация в премоторной коре и дополнительных моторных областях была сильнее в конце. Это согласуется с гипотезой о том, что обнаружение статистических отклонений в начале обучения больше зависит от сенсорных процессов, тогда как по мере обучения преобладают более высокие когнитивные процессы, такие как планирование и предсказание.
Различия между хорошими и плохими учениками. Мы также обнаружили, что существует разница в мозговой активности между участниками, которые хорошо усвоили закономерности, и теми, кто усвоил их плохо. В частности, «хорошие» ученики продемонстрировали более сильную активацию в областях, связанных с обработкой языка и музыки, таких как нижняя лобная извилина и височная доля. Эти результаты предполагают, что способность к статистическому обучению может быть связана с индивидуальными различиями в этих областях мозга.
Обсуждение
Наши результаты демонстрируют, что нарушение локальных зависимостей в парадигме статистического обучения активирует набор областей, которые не только включают слуховую кору, но также и области, вовлеченные в более сложные когнитивные функции, такие как обработка языка и музыки. В частности, активация в верхней височной извилине (STG) билатерально, правой глубокой лобной покрышке (включая латеральную орбитофронтальную кору) и правой премоторной коре свидетельствует о том, что мозг не просто пассивно обрабатывает звуковые сигналы, но активно предсказывает ожидаемые события на основе предыдущего обучения. Эта идея подтверждается параллельной активацией, наблюдаемой при обработке локальных синтаксических структур в музыке и языке. Эти результаты указывают на то, что мозг использует схожие механизмы для обнаружения закономерностей и предсказания событий в различных сенсорных модальностях, будь то слуховые, языковые или музыкальные.
Наши результаты также подчеркивают важность предсказательного кодирования в контексте статистического обучения. Предсказательное кодирование — это теория, которая предполагает, что мозг постоянно генерирует предсказания о входящей сенсорной информации и обновляет свои внутренние модели, когда эти предсказания не оправдываются. Нарушение статистических закономерностей, изученных в нашей парадигме, вероятно, активировало эту предсказательную систему, поскольку она требовала адаптации в реальном времени для поддержания точного представления об окружающей среде. Это объясняет, почему мы наблюдаем активацию в областях, связанных с высшими когнитивными функциями, такими как премоторная кора и орбитофронтальная кора, которые играют роль в планировании, принятии решений и контроле.
Кроме того, наши результаты показывают, что статистическое обучение является динамическим процессом, который продолжается даже во время сканирования фМРТ. Увеличение активации в премоторной и дополнительной премоторной коре с течением времени, наряду с уменьшением активации в слуховой и орбитофронтальной коре, указывает на то, что мозг становится более эффективным в предсказании закономерностей по мере приобретения опыта. Этот сдвиг от сенсорной обработки к более высоким когнитивным процессам отражает адаптацию в реальном времени, необходимую для успешного статистического обучения.
Наконец, обнаруженные различия между «хорошими» и «плохими» учениками предполагают, что индивидуальные различия в способности к статистическому обучению могут быть связаны с различиями в активации определенных областей мозга, в частности тех, которые участвуют в обработке языка и музыки. Это открывает интересные возможности для будущих исследований, направленных на выяснение нейронных основ индивидуальных различий в когнитивных способностях.
Ограничения и будущие направления
Несмотря на полученные результаты, данное исследование имеет некоторые ограничения. Во-первых, хотя мы использовали парадигму, которая сочетает в себе статистическое обучение и обнаружение отклонений, мы не можем полностью исключить влияние явного обучения, поскольку участники могли развивать явные стратегии для выполнения задачи. Будущие исследования могут быть направлены на использование парадигм, которые еще более эффективно препятствуют явному обучению.
Во-вторых, хотя наши результаты предоставляют ценную информацию о нейронных коррелятах статистического обучения, они основаны на одном типе стимулов (аудиторные триплеты). Было бы полезно исследовать, распространяются ли эти результаты на другие модальности, такие как визуальные или тактильные стимулы.
В-третьих, наше исследование было ограничено небольшим размером выборки (n = 33). Будущие исследования с более крупными выборками могли бы лучше исследовать индивидуальные различия в статистическом обучении и его нейронных коррелятах.
Наконец, в то время как фМРТ предоставляет ценную информацию о локализации активности мозга, она имеет ограниченное временное разрешение. Использование методов с более высоким временным разрешением, таких как электроэнцефалография (ЭЭГ) или магнитоэнцефалография (МЭГ), могло бы помочь выяснить точную временную динамику нейронных процессов, участвующих в статистическом обучении и обнаружении отклонений.
Методы
Участники
В наши анализы были включены данные тридцати трех участников (16 женщин и 17 мужчин; средний возраст = 24,97 года, стандартное отклонение = 5,60). Все участники сообщили об отсутствии нарушений слуха или речи, отсутствии в анамнезе неврологических заболеваний и музыкального образования более 2 лет, помимо обычных школьных уроков. Все участники получили компенсацию за участие (200 норвежских крон, примерно 20 евро) по окончании эксперимента.
Этическое заявление
Исследование проводилось в соответствии с руководящими принципами Хельсинкской декларации и было одобрено Региональным комитетом по медицинским и медицинским исследованиям Западной Норвегии под номером ссылки: 2018/590. Участники предоставили письменное информированное согласие до проведения эксперимента.
Стимулы
Звуковые триплеты
Для формирования триплетов мы создали шесть звуков. Каждый звук представлял собой комбинацию тона Шепарда и ударного звука. Тона Шепарда 81 использовались для контроля любых возможных эффектов высоты тона, а также любой слуховой группировки по высоте тона. Мы сгенерировали шесть тонов Шепарда для шести нотных частот (F3: 174,61 Гц, G3: 196,00 Гц, A3: 220,00 Гц, B3: 246,94 Гц, C#4: 277,18 Гц и D#4: 311,13 Гц); каждый тон был результатом наложения девяти синусоидальных компонентов, расположенных на расстоянии октавы друг от друга. Эти шесть тонов Шепарда были объединены с шестью ударными звуками (сурдо, тамбурин, агого, хай-хэт, кастаньеты и вудблок) из онлайн-библиотеки звуковых сэмплов Philarmonia Orchestra). Все звуки были дискретизированы с частотой 44 100 Гц и нормализованы на основе среднеквадратичного значения амплитуды, чтобы они совпадали по общей громкости. Длительность каждого звука составляла 220 мс, включая нарастание (fade-in) 10 мс и затухание (fade-out) 20 мс. Интервал между звуками составлял 80 мс (таким образом, интервал между началами звучания составлял 300 мс). Шесть звуков, соответствующих буквам от A до F (см. Рис. 1A), были скомбинированы в четыре триплета. В частности, звуки A, B, C и D были объединены в два (AB и CD) для формирования «основы» триплета — здесь «основа» относится к первым двум элементам триплета. Звуки E и F использовались для последней позиции или элемента триплета. Таким образом, мы получили четыре уникальных триплета (рис. 1A). Важно отметить, что расположение звуков (от A до F) переставлялось между участниками, чтобы гарантировать, что возможные акустические различия между звуками не исказят результаты.
Для тренировочных испытаний перед экспериментом был создан второй набор из шести звуков. Эти звуки были созданы аналогично звукам основного эксперимента, но частоты нот тонов Шепарда отличались (E3: 164,81 Гц, F#3: 184,99 Гц, G#3: 207,65 Гц, A#3: 233,08 Гц, C4: 261,62 Гц и D4: 293,66 Гц), и ударные сэмплы также отличались от тех, что использовались в основном эксперименте (вудблок, тамбурин, агого, кастаньеты, хай-хэт и бас-барабан). Наконец, был создан звук с гораздо более высокой частотой (C#5: 554,37 Гц, не объединенный с ударным звуком), который был естественно слышимым и отличался от остального набора стимулов, чтобы служить целевым звуком для вспомогательной задачи, которую выполняли участники во время тренировочных испытаний и эксперимента (см. «Процедура»).
Триплеты отличались по частоте встречаемости в экспериментальных блоках. «Стандартные» триплеты составляли 90% всех предъявляемых триплетов и имели окончания с высокой вероятностью перехода (p = 0,9), тогда как «Отклоняющиеся» триплеты составляли 10% всех предъявляемых триплетов и имели окончания с низкой вероятностью перехода (p = 0,1). Текущая парадигма представляет собой Марковскую модель 1-го порядка или биграммную модель со строго локальным распределением 2 (локальные зависимости 82).
Поток триплетов вне сканера
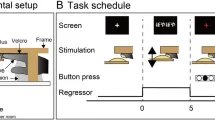
400 триплетов были псевдослучайно объединены в потоки без пауз или блоки продолжительностью около 7 минут каждый (см. Рис. 1B). Триплеты предъявлялись в псевдослучайном порядке, так что отклоняющиеся триплеты были разделены по крайней мере тремя стандартными триплетами. Не более двух последовательных и идентичных стандартных триплетов предъявлялось. Основы триплетов (AB или CD) следовали за любым из двух окончаний триплетов (E или F) с постоянной вероятностью перехода (TP = 0,5). Таким образом, например, ABE мог сопровождаться ABE, CDF, ABF или CDE.
Поток триплетов внутри сканера
Для потока внутри сканера вероятности перехода были идентичны тем, которые использовались вне сканера (см. Рис. 1B, C для вне и внутри сканера соответственно). Единственным изменением потока триплетов внутри сканера было учет задержки BOLD-сигнала. Таким образом, каждые 27 стандартных триплетов предъявлялось три последовательных отклоняющихся триплета. Таким образом, испытания из 30 триплетов (27 стандартных, за которыми следуют 3 последовательных отклоняющихся триплета) продолжительностью 27 секунд каждое были сформированы (см. Рис. 1C). В каждом испытании стандартные триплеты предъявлялись в псевдослучайном порядке, так что не более двух идентичных стандартных триплетов предъявлялись последовательно.
Процедура
Фаза обучения вне сканера
Для индукции неявного статистического обучения участники проходили фазу обучения («ознакомления») перед приобретением изображений. Для фазы обучения эксперимента использовалась комната, прилегающая к комнате МРТ-сканера. Участникам предлагалось сесть на стул перед столом и слушать звуки, которые будут им представлены через наушники, одновременно просматривая беззвучный фильм на мониторе перед собой. Эксперимент состоял из 3 блоков, каждый из которых включал фазу экспозиции продолжительностью около 7 минут, за которой следовал поведенческий тест продолжительностью около 2 минут, что привело к общей продолжительности фазы обучения около 30 минут.
Эксперимент начинался с набора инструкций, представленных на экране компьютера. Участники не были информированы о закономерностях в расположении стимулов, чтобы гарантировать, что любое обучение в течение эксперимента было неявным. В то же время, чтобы гарантировать, что участники были внимательны к стимулам, использовалась вспомогательная задача: участникам предлагалось нажимать пробел на клавиатуре компьютера каждый раз, когда они слышали целевой звук (который состоял из тона более высокой высоты без ударного звука — см. «Стимулы»). В инструкциях были примеры целевого звука, за которыми следовали тренировочные испытания (продолжительностью около 1 минуты), содержащие относительно большое количество целевых звуков (8 целевых звуков). Тренировочные испытания повторялись, если участники не обнаруживали по крайней мере 80% целевых звуков или допускали большое количество ложных срабатываний (более 3 ложных срабатываний).
Тест на знакомство и оценка уверенности вне сканера
В конце каждого блока автоматизированный поведенческий тест оценивал, могли ли участники различать (1) стандартные триплеты от отклоняющихся триплетов и (2) стандартные триплеты от «нетриплетов», т.е. триплетов, которые не встречались во время фазы экспозиции (такие как EFD, BDA, CFB и ACE). Каждый тест состоял из двенадцати испытаний, в которых участникам предъявлялись двенадцать различных комбинаций триплетов (ABE против ABF, ABE против CDE, ABE против EFD, ABE против BDA, ABE против CFB, ABE против ACE, CDF против ABF, CDF против CDE, CDF против EFD, CDF против BDA, CDF против CFB и CDF против ACE). Всего участники должны были ответить в тридцати шести испытаниях на протяжении фазы обучения. Между триплетами был перерыв в 800 мс. Участникам предлагалось выбрать, какая последовательность звучала более знакомо или вызывала у них меньше удивления, используя тест с двойным принудительным выбором (нажимая «1» или «2» на клавиатуре, чтобы выбрать первую или вторую последовательность). После этого они оценивали уровень своей уверенности в выборе последовательности (выбирая число по шкале от «1» — абсолютно неуверен, мог бы подбросить монету — до «5» — абсолютно уверен). Последовательные испытания не использовали одну и ту же основу триплета, а представление типов триплетов было сбалансировано.
Приобретение данных и фаза обучения внутри сканера
После фазы обучения вне сканера участники приступили к фазе сканирования эксперимента, во время которой ожидалось продолжение обучения. Как упоминалось ранее, целью исследования было индукция неявного статистического обучения как вне, так и внутри сканера, и единственной причиной модификации потока триплетов для периода внутри сканера было учет задержки BOLD-сигнала. Сканирование состояло из одного прохода продолжительностью примерно 31 минуту (см. Рис. 1C). Всего было представлено 6 блоков продолжительностью 4,5 минуты каждый, чередующихся с периодами отдыха по 30 секунд. Внутри каждого блока было объединено 10 испытаний продолжительностью 27 секунд каждое. В каждом испытании предъявлялось 27 последовательных стандартных триплетов, за которыми следовали 3 отклоняющихся триплета. Во время всей сессии сканирования на экране, расположенном в задней части сканера, проецировался беззвучный фильм, который участники могли смотреть через зеркало. Чтобы гарантировать, что участники были внимательны к стимулам, использовалась та же вспомогательная задача, что и во время фазы экспозиции: участникам предлагалось нажимать кнопку на совместимом с МРТ портативном устройстве указательным пальцем каждый раз, когда они слышали (более высокий) целевой звук. Участникам предлагалось лежать неподвижно на протяжении всего эксперимента, чтобы минимизировать шум. Слуховые стимулы предъявлялись через совместимые с МРТ наушники, и участникам предоставлялись беруши для облегчения любых помех от шума сканера.
Приобретение изображений
Эксперимент проводился с использованием 3T сканера (Siemens Prisma, Эрланген) и 20-канальной головной катушки. Перед функциональной сессией было получено анатомическое референсное T1-взвешенное (T1_w) изображение с разрешением вокселей = 1 × 1 × 1 мм^3, FOV = [220 220 144.08]. По окончании анатомического сканирования участникам напомнили инструкции к задаче. Функциональные T2-взвешенные изображения были получены с использованием градиентно-эхо EPI последовательности с разрешением вокселей = 3,3 × 3,3 × 3,3 мм^3, межизобразовым зазором = 0,594 мм и временем повторения (TR), установленным на 2000 мс. Всего было получено 1074 тома. Плоскость приобретения была наклонена на 30^{irc } от плоскости ACPC для уменьшения падения сигнала в орбитофронтальной коре 83.
Предварительная обработка
Все шаги предварительной обработки выполнялись с использованием конвейера предварительной обработки fMRIPrep 84, за исключением сглаживания, которое было реализовано в SPM12.
Предварительная обработка анатомических данных
T1-взвешенное (T1w) изображение было скорректировано на неоднородность интенсивности с использованием N4BiasFieldCorrection 85, распространяемого с ANTs 2.2.0 86, и использовалось в качестве T1w-референса на протяжении всего рабочего процесса. Затем T1w-референс был очищен от черепа с помощью реализации Nipype рабочего процесса antsBrainExtraction.sh (из ANTs), используя OASIS30ANTs в качестве целевого шаблона. Сегментация тканей мозга (спинномозговой жидкости (CSF), белого вещества (WM) и серого вещества (GM)) выполнялась на очищенном от черепа T1w с использованием fast (FSL 5.0.9 87). Поверхности мозга были реконструированы с использованием reconall (FreeSurfer 6.0.1 88), а оцененная ранее маска мозга была уточнена с помощью пользовательского варианта метода для согласования сегментаций коры головного мозга, полученных с помощью ANTs и FreeSurfer, из Mindboggle 89. Объемная пространственная нормализация в стандартное пространство MNI (MNI152NLin2009cAsym) выполнялась путем нелинейной регистрации с помощью antsRegistration (ANTs 2.2.0), используя очищенные от черепа версии как T1w-референса, так и T1w-шаблона. Был выбран следующий шаблон для пространственной нормализации: ICBM 152 Nonlinear Asymmetrical template version 2009c 90 (TemplateFlow ID: MNI152NLin2009cAsym).
Предварительная обработка функциональных данных
Для каждого BOLD-прохода (1 на субъект) выполнялась следующая предварительная обработка. Во-первых, эталонный том и его очищенная от черепа версия были сгенерированы с использованием пользовательской методологии fMRIPrep. Затем BOLD-референс был соотнесен с T1w-референсом с помощью bbregister (FreeSurfer), который реализует регистрацию на основе границ 91. Соотнесение было настроено с девятью степенями свободы для учета искажений, оставшихся в BOLD-референсе. Параметры движения головы относительно BOLD-референса (матрицы преобразования и соответствующие шесть параметров вращения и трансляции) оцениваются до любого пространственно-временного фильтрования с помощью mcflirt (FSL 5.0.9 92). BOLD временные ряды были сэмплированы по срезам с использованием 3dTshift из AFNI 20160207 93. BOLD временные ряды были сэмплированы на поверхности в пространствах fsaverage5. BOLD временные ряды (включая коррекцию времени срезов, когда она применялась) были сэмплированы в их исходное, собственное пространство путем применения единого, составного преобразования для коррекции движения головы и искажений восприимчивости. Эти сэмплированные BOLD временные ряды будут называться предварительно обработанными BOLD в исходном пространстве, или просто предварительно обработанными BOLD. BOLD временные ряды были сэмплированы в стандартное пространство, генерируя предварительно обработанный BOLD-проход в пространстве ['MNI152NLin2009cAsym']. Было рассчитано несколько временных рядов помех на основе предварительно обработанных BOLD: смещение кадра (FD), DVARS и три глобальных сигнала по областям. FD и DVARS рассчитываются для каждого функционального прохода, используя их реализации в Nipype (в соответствии с определениями 94). Три сигнала извлекаются из масок CSF, WM и всего мозга. Дополнительно был извлечен набор физиологических регрессоров для обеспечения коррекции шума на основе компонентов (CompCor 95). Главные компоненты оценивались после высокочастотной фильтрации BOLD временных рядов (с использованием дискретного косинусного фильтра с частотой среза 128 с) для двух вариантов CompCor: временного (tCompCor) и анатомического (aCompCor). Компоненты tCompCor затем рассчитывались из 5% наиболее изменчивых вокселей в маске, охватывающей подкорковые области. Эта подкорковая маска была получена путем сильного эрозии маски мозга, что гарантирует, что она не включает кортикальные GM области. Для aCompCor компоненты рассчитывались в пересечении вышеупомянутой маски и объединения масок CSF и WM, рассчитанных в T1w пространстве, после их проецирования в собственное пространство каждого функционального прохода (используя обратное преобразование BOLD к T1w). Компоненты также рассчитывались отдельно в масках WM и CSF. Для каждого разложения CompCor сохранялись k компонентов с наибольшими сингулярными значениями (так что временные ряды сохраненных компонентов достаточны для объяснения 50% дисперсии в маске помех — CSF, WM, комбинированной или временной). Оставшиеся компоненты были исключены из рассмотрения. Оценки движения головы, рассчитанные на этапе коррекции, также были включены в соответствующий файл помех. Временные ряды помех, полученные из оценок движения головы и глобальных сигналов, были расширены за счет включения временных производных и квадратичных членов для каждого 96. Кадры, превышающие порог 0,5 мм FD или 1,5 стандартизированных DVARS, были помечены как выбросы движения. Все пересэмплинги выполнялись с использованием одного этапа интерполяции, включающего все соответствующие преобразования (т.е. матрицы преобразования движения головы, коррекцию искажений восприимчивости, когда доступны, и соотнесение с анатомическим пространством и выходным пространством). Ресэмплинги сетки (объемные) выполнялись с использованием antsApplyTransforms (ANTs), настроенного с интерполяцией Ланцоша для минимизации сглаживающих эффектов других ядер 97. Ресэмплинги без сетки (поверхностные) выполнялись с использованием mri_vol2surf (FreeSurfer).
Анализ данных
Анализ поведенческих данных
Статистический анализ поведенческих данных включал ответы участников на тест на знакомство и вспомогательную задачу. Участникам предлагалось выполнять одну и ту же вспомогательную задачу вне сканера и внутри него. Анализ проводился с использованием SPSS 25 (IBM Corp., Армонк, Нью-Йорк, США). Ответы классифицировались как правильные, когда участники правильно выбрали последовательность, представляющую стандартный триплет (стандартные триплеты воспроизводились чаще во время фазы экспозиции). Средний процент правильных ответов рассчитывался для каждого участника и впоследствии сравнивался со случайным уровнем (0,5) с использованием t-критерия для независимых выборок, lpha = 0,05.
Моделирование данных 1-го уровня
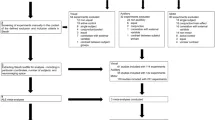
Используя SPM12, мы определили модель общего линейного регрессионного анализа (GLM) для 1-го уровня статистического вывода. Для удаления низкочастотного шума применялся фильтр высоких частот с частотой среза 1/128 Гц. В качестве маски использовалась явная бинарная маска, основанная на нормализованных изображениях серого вещества всех субъектов. GLM 1-го уровня включал 26 регрессоров, состоящих из (а) двух регрессоров для CSF и WM и (b) 24 регрессоров, составляющих разложение Вольтерра параметров выравнивания. Мы провели 3 аналитических исследования, соответствующих 3 гипотезам исследования (см. Введение). Для каждого участника мы вычислили контрастное изображение между отклоняющимися и стандартными триплетами, используя дизайн, основанный на событиях. То есть, в каждом испытании последовательность стандартных триплетов определялась как одно событие стандартного условия, а последовательность трех финальных отклоняющихся триплетов — как событие отклоняющегося условия. Условие каждого события, наряду с его продолжительностью и временем начала относительно начала сессии фМРТ, были указаны для моделирования первого уровня в SPM12. Вектор контраста использовался для указания их сравнения, что привело к контрастным изображениям, которые были переданы на второй уровень статистического моделирования.
В отношении гипотезы (2) для моделирования эволюции обнаружения отклонений в ходе эксперимента использовался дополнительный регрессор, выражающий взаимодействие «Время × Условие», который был построен на основе времени начала миниблоков стандартных и отклоняющихся событий.
Моделирование данных 2-го уровня
Для контроля ошибки I рода картографическая карта активации второго уровня контраста «Отклоняющийся > Стандартный», сгенерированная SPM, была подвергнута вероятностному пороговому улучшению кластеров (pTFCE, 98), которое дало эффект на уровне p = 0,05 скорректированного. В соответствии с тремя гипотезами были проведены три анализа соответственно.
Первый анализ был направлен на изучение реакций мозга в отношении обнаружения статистических отклонений («обнаружение отклонений»). Для оценки того, различались ли активации между двумя условиями (Отклоняющийся и Стандартный), мы провели групповой анализ (одновыборочный t-критерий). Анализ проводился с использованием инструмента Local Indicators of Spatial Association (LISA) 99, который дает преимущество более чувствительного анализа и гарантирует обнаружение даже небольших активаций. LISA — это непараметрическая и пороговая система, которая учитывает пространственный контекст и, таким образом, сохраняет пространственную точность без потери статистической мощности. В рамках LISA множественная коррекция достигается путем контроля коэффициента ложных открытий (FDR), и поэтому нет возможности коррекции на уровне семейной ошибки. LISA учитывает топологические особенности активации, применяя пространственный фильтр к z-карте перед пороговым контролем FDR на уровне вокселей. Контроль FDR использует байесовскую двухкомпонентную модель смешения, и последующие оценки FDR для каждого вокселя рассчитываются после 5000 случайных перестановок. Индивидуальные контрастные карты (сгенерированные SPM для контраста Отклоняющийся > Стандартный) были подвергнуты одновыборочному t-критерию с использованием LISA.
Дополнительной целью первого анализа было изучение возможной активации pars opercularis IFG (BA 44i). Для этой цели мы использовали FSLeyes (McCarthy, 2021; http://doi.org/10.5281/zenodo.4704476) и Гарвардско-Оксфордский Атлас Кортикальной Структуры для создания пороговой маски ROI для pars opercularis. Затем анализ ROI проводился с использованием инструмента SPM MARSeille Boîte À Région d’Intérêt (MarsBar).
Второй анализ исследовал, как обнаружение отклонений развивалось в ходе эксперимента. Наконец, третий анализ исследовал, существовала ли какая-либо количественная разница между «хорошими» и «плохими» учениками в областях интереса для обнаружения отклонений.
Для третьего анализа мы исключили трех участников; двое имели пропущенные данные в тесте на знакомство, а один другой запутался и допустил слишком много ложных срабатываний (132 ложных срабатывания). 30 участников были разделены на две группы «хороших» (14 участников) и «плохих» (16 участников) учеников на основе медианного значения их баллов в задаче обучения перед фМРТ. Мы ограничили сравнение в пределах девяти анатомических ROI, соответствующих девяти кластерам, которые показали значительную активацию во время обработки отклоняющихся по сравнению со стандартными триплетами (см. Таблицу 1). Мы использовали инструмент SPM MarsBaR для оценки среднего значения для каждого участника в каждом из девяти кластеров из контраста «Отклоняющийся > Стандартный». Впоследствии эти средние значения были введены в девять двухвыборочных t-критериев с использованием MATLAB®, чтобы исследовать возможные различия между двумя группами во время обнаружения отклонений в любой из девяти ROI.
Результаты были визуализированы с использованием инструмента xjView (https://www.alivelearn.net/xjview), а Рис. 2 был создан с использованием MRIcroGL (http://www.mricro.com, версия v1.0.20180623) (Дополнительная информация S1).
Заключение
В заключение, наши данные показывают, что нарушение локальных зависимостей в парадигме статистического обучения задействует набор областей мозга, охватывающий STG, островок, глубокую лобную покрышку, RCZ, MCC, pre SMA и скорлуповидное ядро. Наблюдаемый паттерн активации напоминает паттерн активации в левом полушарии, наблюдаемый при нарушении локальных зависимостей на основе речевых звуков в экспериментах по обучению искусственным грамматикам. Лобные вклады во время обнаружения статистических отклонений подтверждают наш аргумент о том, что иррегулярности, возникающие в текущей парадигме, являются синтаксическими и требуют предсказательных процессов, выходящих за рамки возможностей слуховой сенсорной памяти. Основываясь на литературе, мы заключаем, что наблюдаемый паттерн активации отражает адаптацию в реальном времени, необходимую для предсказательного кодирования в контексте статистического обучения.
Примечание: Данный перевод и структурирование текста выполнены в соответствии с предоставленными инструкциями. Использованы HTML-теги для форматирования. Указаны переведенные alt-тексты для изображений, а также запрос для поиска изображений.