Интересное сегодня
Социальный статус и автоматическое копирование действий: исс...
Введение в теорию кодирования событий Согласно Теории кодирования событий (Hommel et al., 2001), вып...
Как заводить друзей при социофобии: практические советы
Понимание проблемы Социальная тревожность часто вызывает сильный страх осуждения или отвержения в со...
Агрессия у молодежи: связь черт с безжалостностью и развитие...
Введение Проблемы внешнего поведения среди молодежи, такие как агрессия, считаются глобальной пробле...
Необходимость надлежащей эпистемологической основы в психоло...
Введение В рамках любого научного исследования необходимо определить и согласовать условия, необходи...
Роль расширенной семьи в поддержке аутичных людей и их родит...
Краткий обзор аутизма и роли расширенной семьи Аутизм представляет собой нейроразвивающее расстройст...
Гостинг в отношениях: психологическое влияние и методы иссле...
ВведениеРост использования социальных сетей имеет как положительные, так и отрицательные последствия...

Введение
Тест рисования часов (CDT) является доступным методом для скрининга на деменцию. Он состоит из двух частей: задание нарисовать циферблат часов с цифрами и стрелками, установленными на определенное время (командное условие), и задание скопировать предложенный образец часов (условие копирования). Точность выполнения этого теста зависит от множества когнитивных функций, и даже незначительные изменения в рисунке могут свидетельствовать о нарушениях в работе мозга. Командное рисование часов требует понимания инструкций, воспоминания семантических атрибутов часов, рабочей памяти для обработки лингвистических компонентов инструкций, эффективного умственного планирования, визуопространственной обработки и моторных навыков для выполнения рисунка. Хотя условие копирования также задействует ряд когнитивных способностей, оно в основном полагается на эффективные навыки визуального сканирования, визуоконструирование и исполнительные функции. Литературные данные также указывают на корреляцию производительности в тесте рисования часов с общим баллом по Монреальской шкале оценки когнитивных функций (MMSE), которая является альтернативным тестом на когнитивные нарушения.
В прошлом было предложено несколько систем оценки аналоговых часов. Эти системы варьируются от номинальных (правильно/неправильно) до детальных 22- или 31-балльных оценок. Некоторые основаны на анализе ошибок, оценивающих семантику, графомоторные функции и исполнительный контроль. Было показано, что различные протоколы оценки обладают схожими психометрическими свойствами. Однако, согласно Spenciere и соавторам (2017), субъективный человеческий фактор при интерпретации результатов рисования часов может приводить к различным исходам. Более того, Price и его коллеги обнаружили вариативность в внутри- и межэкспертной надежности. Такая вариативность в оценке экспертами вносит неоднозначность, которая может негативно сказаться на надежности любого диагностического теста, основанного на CDT.
Модели глубокого обучения (DL) могут устранить эту проблему благодаря своей способности автоматически извлекать высокоуровневые признаки из данных без какой-либо предварительной инженерии признаков. Эти высокоуровневые признаки извлекаются на основе данных путем непрерывной оценки корреляций между более простыми признаками. Универсальность и предсказательная сила этой вложенной иерархии признаков ограничены только объемом обучающих данных. Таким образом, модели DL (при наличии достаточного количества данных для обучения) представляют возможность для разработки объективных критериев оценки, способствующих более надежному принятию клинических решений.
В данном исследовании мы разработали интерпретируемую модель DL для автоматического изучения ключевых признаков рисования часов, а затем проверили это обучение на классификации «болезни» в выборке клинически диагностированных пациентов с болезнью Альцгеймера (AD) или сосудистой деменцией (VaD) по сравнению с их сверстниками без деменции. Для этой работы мы использовали окончательное изображение, полученное в результате цифрового теста рисования часов (dCDT). dCDT использует технологию цифровой ручки с соответствующей смарт-бумагой, которая может записывать каждое движение пера во время рисования, позволяя исследователям анализировать множество элементов рисования часов, таких как задержки между движениями пера, графомоторные элементы (например, размер циферблата) и общее количество движений пера. Эта технология, следовательно, предоставляет дополнительные преимущества по сравнению с традиционным тестом рисования часов, поскольку она может анализировать процесс создания рисунка, а не полагаться исключительно на окончательное изображение. Автоматизированные модели оценки, разработанные на основе dCDT в последние годы, значительно превосходят традиционный тест рисования часов на бумаге. Их значения AUROC (площадь под ROC-кривой) варьируются от 0.89 до 0.93 по сравнению с опубликованными значениями AUROC существующих систем оценки, используемых клиницистами, от 0.66 до 0.79. В этом исследовании протокол кинематических, временных или латентных и визуопространственных признаков, извлеченных dCDT, не использовался. Вместо этого мы использовали только изображение часов или фактический рисунок, выполненный пациентами и участниками исследования, для обучения модели DL для скрининга деменции.
Несмотря на свои перспективы, множество недостатков затрудняют успешное применение конвейеров DL к анализу медицинских изображений. Во-первых, количество параметров в мощных моделях DL на много порядков выше, чем в стандартных моделях машинного обучения, таких как логистическая регрессия. Как правило, эти параметры представляют собой веса нейронной сети (DNN), которые позволяют сети моделировать сложные, произвольные зависимости вход-выход. Использование большого пространства параметров порождает потребность в больших, размеченных наборах данных для обучения этих DNN. DNN использует значения ошибок, определяемые как расстояние между вероятностями предсказанного класса и истинными значениями, для итеративного обновления своих параметров. В результате окончательные значения параметров становятся полностью зависимыми от набора данных и, как правило, не обобщаются на другие задачи классификации. В этой работе, из-за наличия большого неразмеченного набора данных и значительно меньшего размеченного набора данных, мы решили использовать полусупервизорную модель DL, которая может изучать внутренние вариации изображений часов из неразмеченных данных и использовать небольшое количество размеченных данных для решения задачи классификации с минимальной донастройкой.
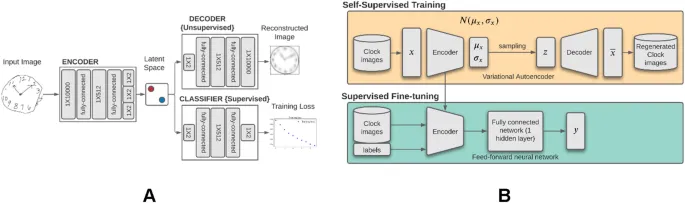
Мы использовали модель вариационного автоэнкодера (VAE) для выполнения задачи самообучения. VAE — это генеративная модель, которая стремится изучить совместное распределение вероятностей всех переменных, присутствующих в наборе данных. Этот метод использует точную реконструкцию входных изображений в качестве цели для изучения низкоразмерного латентного представления в форме заранее определенного априорного распределения. Было показано, что глубокие генеративные модели улучшают точность классификации в условиях полусупервизорного обучения, особенно когда имеется мало размеченных примеров и гораздо больше неразмеченных примеров. Мы использовали большой неразмеченный набор данных рисунков часов для обучения VAE, а затем использовали значительно меньший размеченный набор данных для донастройки обученной сети-энкодера VAE. Энкодер представляет собой часть сети VAE, которая кодирует рисунок часов в низкоразмерное латентное пространство. Данное исследование является первой попыткой использования полусупервизорных моделей DL для анализа рисунков часов. Основная цель данного проекта — продемонстрировать принципиальную возможность того, что скромное количество признаков, извлеченных из необработанного изображения CDT, может закодировать достаточно аномалий в рисунках часов для построения эффективного классификатора деменции. Вторичная и одновременная цель данного проекта — показать, что самообучающаяся предварительная тренировка с использованием больших неразмеченных наборов данных рисунков часов может извлечь информативные признаки, способные классифицировать деменцию от недементных состояний на основе небольшого объема размеченных данных.
Результаты
Участники
Таблица 1 описывает соответствующие демографические характеристики участников, которые выполнили рисунки часов для обучающего, начального классификационного и вторичного валидационного наборов данных. Все участники всех наборов данных были старше 60 лет. Все участники классификационной когорты выполнили тест рисования часов в обоих условиях. В обучающем наборе данных три участника не смогли нарисовать часы по команде. В классификационной когорте группа с деменцией была значительно старше, имела более низкий уровень образования и в среднем более низкий общий балл MMSE по сравнению с их сверстниками без деменции. По сравнению с обучающей когортой, классификационная когорта преимущественно состояла из участников мужского пола европеоидной расы.
Классификационный набор данных (когорта донастройки)
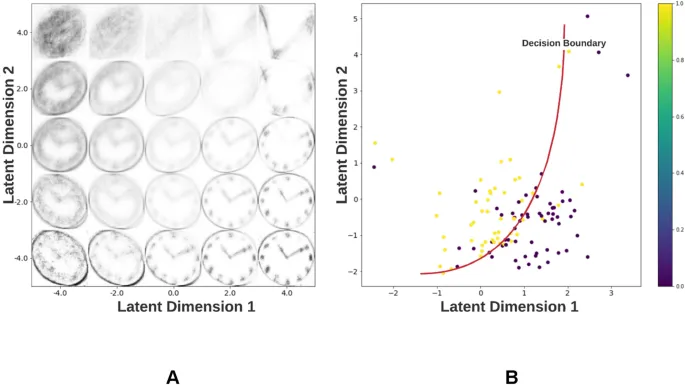
Рисунок 1A иллюстрирует реконструкции рисунков часов, выполненные VAE, в зависимости от его латентных переменных. Плавный переход между реконструированными часами, наблюдаемый здесь, является результатом нормального распределения, которому ограничены латентные переменные VAE. Рисунок 1B показывает распределение реконструкций часов с деменцией/контрольных часов из набора данных для донастройки в зависимости от их векторов латентного пространства.
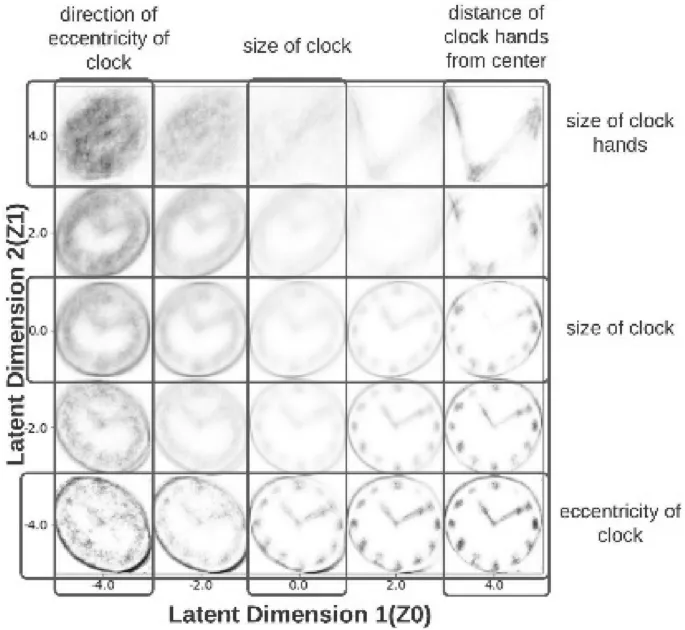
Точечная диаграмма показывает видимое разделение между часами с деменцией и контрольными часами. Реконструкции показывают, что признаки, имеющие значение для человеческого восприятия, такие как цифры и метки, не улавливаются латентным пространством VAE. Вместо этого латентное пространство VAE захватывает статистические признаки рисунков часов, такие как эксцентриситет, размер, размер стрелок часов и расстояние стрелок часов от геометрического центра (рис. 2). Эти признаки коррелируют с двумя латентными измерениями латентного пространства VAE и взаимосвязаны в этом пространстве.
Латентный многообразие, на которое обученный VAE проецирует рисунки часов, представляет собой двумерное векторное пространство, которое может быть функционально разделено на пять областей, определяющих вариации различных признаков и аномалий в рисунках часов. Рисунок 2 показывает траверс по этим пяти областям. VAE не имел предварительной информации о генеративных признаках рисования часов. Следовательно, признаки часов проявляются в запутанной/взаимокоррелированной форме в двумерном латентном пространстве VAE.
Латентные измерения
Первое латентное измерение (отложенное по оси X) сокращенно обозначается как Z0, а второе латентное измерение (отложенное по оси Y) — как Z1. Левая половина пространства латентного многообразия (Z0 ≤ 0) связана с расстоянием точки пересечения стрелок от геометрического центра часов (рис. 2, дополнительное видео V2). Точка пересечения стрелок движется вниз от геометрического центра по мере того, как Z1 при |Z0| изменяется от −4 до +4 в этой области. Это изменение также связано с потерей круглой периферии часов, что является важной аномалией, присутствующей в часах, нарисованных пациентами с продвинутыми стадиями деменции. Верхняя часть латентного пространства (Z1 > 0) кодирует увеличивающуюся длину стрелок часов; расстояние точки пересечения стрелок до геометрического центра перемешано друг с другом (рис. 2, дополнительное видео V3). Длина стрелок часов и площадь циферблата увеличиваются по мере изменения Z0 при |Z1| от −4 до +4. Нижняя половина латентного пространства (Z1 < 0) кодирует эксцентриситет циферблата (рис. 2, дополнительное видео V4). Эксцентриситет уменьшается по мере изменения Z0 при |Z1| от −4 до +4 в этой области латентного пространства. Кроме того, эта характеристика взаимосвязана с увеличением площади циферблата по мере изменения Z0 при |Z1| от −4 до +4 в этой области. Наконец, ось X, отслеживающая изменение Z0 при |Z1| = 0, чисто кодирует размер циферблата, что очевидно из возрастающей четкости рисунка часов вдоль этой линии (рис. 2, дополнительное видео V5).
Этот анализ показывает, что многие физически понятные признаки и аномалии часов закодированы в различных областях латентного пространства обученного VAE. Он также показывает, что во многих случаях несколько физических признаков взаимосвязаны.
Классификационный набор данных (тестовая когорта)
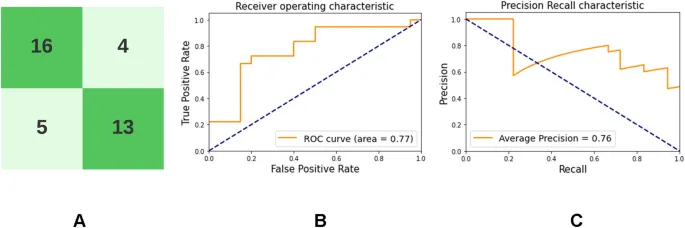
Обученный энкодер VAE использовался для классификации после донастройки в течение 10 эпох на наборе данных для донастройки, описанном ранее. Проекции латентного пространства тестового набора данных показаны на Дополнительном рисунке S1. Таблица 2 показывает производительность полусупервизорного классификатора, построенного с использованием обученной сети-энкодера из VAE. 95% доверительные интервалы обозначают производительность модели на 100 бутстрапированных примерах тестовых данных. Рисунок 3 демонстрирует матрицу ошибок, ROC-кривую (рабочую характеристику приемника) и PR-кривую (кривую точности-полноты), полученные при классификации на тестовых данных с использованием этой сети.
Классификационный набор данных (вторичная валидационная когорта)
Мы дополнительно протестировали классификатор на вторичном валидационном наборе данных, состоящем из 41 рисунка часов с деменцией и 50 — без деменции. Таблица 2 иллюстрирует производительность модели на этом наборе данных. Здесь мы также использовали бутстрапирование с заменой для генерации доверительных интервалов.
Обсуждение
VAE, обученный на реконструкции цифровых рисунков часов, сжимает релевантную информацию, присутствующую в изображении часов, в высокоинформативный двумерный вектор. Результат обладает полезными свойствами для классификации деменции против недементных состояний. Латентное пространство VAE может использоваться для генерации искусственных рисунков часов, которые статистически похожи на рисунки часов, выполненные человеком, но не воспроизводят заметные признаки/детали часов, такие как цифры, стрелки и метки, которые являются центральными для оценки часов с использованием традиционных методов оценки. Вместо локальных признаков, обученное латентное пространство VAE захватывает глобальные признаки, такие как эксцентриситет циферблата, площадь циферблата, длина стрелок и расстояние от точки соединения стрелок до центра часов. Некоторые из этих признаков были отдельно идентифицированы экспертами как релевантные для различения различных подтипов деменции, а также в отдельных когнитивных задачах. Например, меньшая площадь циферблата ассоциируется с микрографией и субкортикальными профилями заболеваний, где присутствует первичная исполнительная дисфункция (например, болезнь Паркинсона). Люди с исполнительной дисфункцией и болезнью Паркинсона также демонстрируют дефицит планирования при расстановке цифр. Расположение стрелок часов также является фактором, влияющим на растормаживание и трудности с визуальным вниманием. Стирание мелких деталей рисунка часов может быть неизбежным компромиссом, связанным с этапом предварительной обработки, где рисунки часов масштабируются до 100x100 для ввода в VAE. Будущие исследования в этой области могут выявить аналогичные закономерности между косостью изображения часов или расстоянием точки контакта стрелок часов от центра и лежащими в основе патологиями.
Кроме того, этот анализ показывает, что многие физически понятные признаки и аномалии часов закодированы в различных областях латентного пространства VAE взаимосвязанным образом. В будущей работе мы исследуем, улучшит ли разделение этих генеративных признаков производительность в классификации деменции. Для этого мы будем использовать конструкцию латентных переменных с помощью продвинутых моделей VAE, таких как FactorVAE. Кроме того, мы исследуем, может ли классификатор, построенный на основе генеративных факторов, выявленных в данной статье, отличить деменцию от контрольной группы. Эти генеративные факторы записываются в программном обеспечении, связанном с цифровой версией теста рисования часов, используемой в этом исследовании. Мы дополним эти признаки другими графомоторными и временными признаками, доступными исключительно через dCDT, чтобы изучить относительную важность этих признаков в классификации деменции от недементных состояний.
dCDT использует технологию цифровой ручки с сопутствующей смарт-бумагой, которая записывает каждое движение пера, позволяя исследователям получать доступ к ряду переменных, присущих процессу создания рисунка часов, в дополнение к самому рисунку. dCDT также может записывать полные видеоролики теста рисования часов, которые могут быть проанализированы с использованием передовых последовательных моделей глубокого обучения, таких как Vision Transformers, для создания высокопроизводительных скрининговых инструментов для деменции. Эти будущие исследовательские работы позволят нам изучить широкий спектр возможностей сбора данных dCDT.
Важно отметить, что эта методология представляет собой значительный прогресс в двунаправленной трансляционной нейронауке с использованием ИИ. Здесь мы использовали механистическое понимание задач dCDT, разработанное совместно с исследованиями нейровизуализации, для обучения латентных представлений VAE в рамках серии экспериментов по прямому трансляционному подходу. На основе визуального анализа латентных представлений VAE и в сочетании с результатами классификации, эксперты в данной области могут использовать эти выводы для выявления новых комбинаций признаков изображений CDT и сопоставления их с эталонными когнитивными оценками и/или данными нейровизуализации. Эта двунаправленная трансляционная возможность подчеркивает важность методов, чувствительных к предметным областям, включая интерпретируемость и механистическое обоснование.
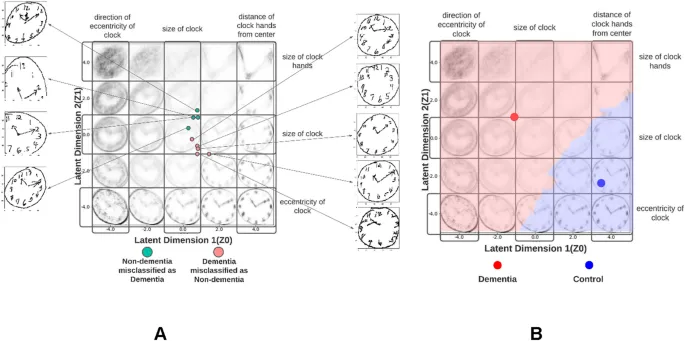
Это исследование не лишено ограничений. Группа с деменцией значительно старше и имеет более низкий уровень образования, чем группа без деменции, что делает сравнение неполноценным. Кроме того, цель классификации более общая, чем в других исследованиях в этой области. Однако это приемлемо, поскольку данное исследование служит доказательством принципа того, что двумерное представление CDT сохраняет информацию, необходимую для классификации деменции от недементных состояний. Мы визуализировали проекции латентного пространства 9 рисунков часов из тестового набора данных, которые были ошибочно классифицированы, чтобы выявить потенциальные недостатки классификатора (рис. 4A). Это показало, что (а) ошибочно классифицированные рисунки часов с деменцией и без нее образовывали два отдельных кластера в латентном пространстве, где ошибочно классифицированные рисунки без деменции проецировались в аномальную часть латентного пространства и наоборот; (б) ошибочно классифицированные рисунки с деменцией имели нормальный размер и круглое циферблат, но им либо не хватало стрелок, либо они имели короткие, смещенные стрелки; и (в) ошибочно классифицированные рисунки без деменции либо имели эксцентричные циферблаты, либо подвергались ошибочному обнаружению контуров, что приводило к частичным циферблатам. Это выявляет два потенциальных недостатка нашей модели: (а) она не смогла закодировать отсутствие/короткие, вертикально смещенные стрелки как признак, предсказывающий деменцию; (б) во время предварительной обработки обнаружение контуров частично обнаружило циферблат некоторых часов. Это вносило эксцентриситет в иначе круглые циферблаты. Чтобы повысить клиническую полезность и интерпретируемость нашей модели, мы использовали классификатор k-ближайших соседей для операционализации самого латентного пространства VAE в области «деменция» и «контроль» (k = 13) (рис. 4B). Оптимальное k было определено с помощью трехкратной перекрестной проверки на наборе данных для донастройки. Это сегментировало латентное пространство на 2 области, соответствующие деменции и контрольной группе. Этот классификатор отличается от классификатора, представленного в Таблице 1. Производительность этого классификатора приведена в Дополнительной таблице T1.
В будущем мы планируем использовать сжатое латентное представление CDT для различения различных типов деменции, таких как AD, VaD, легкое когнитивное нарушение (MCI), амнестическое MCI, дизэксecutive MCI и деменция при болезни Паркинсона. Было показано, что кодирующая способность VAE зависит от количества белого пространства, присутствующего в эскизах (Дополнительный рисунок S2). Это также ограничило наше исследование, поскольку нам пришлось отбросить изображения рисунков часов, размер которых превышал 40 000 пикселей.
В целом, данное исследование продемонстрировало, что традиционный тест рисования часов на бумаге может быть сжат в экономное двумерное латентное представление с использованием современных полусупервизорных моделей DL для классификации участников, клинически диагностированных с деменцией. Поскольку наш классификатор полагается исключительно на рисунок часов и обучен в режиме слабой супервизии, он потенциально может использовать большие общедоступные наборы данных рисунков часов для создания аналогичных классификаторов с минимальной донастройкой для других состояний, таких как делирий и черепно-мозговая травма. Его также можно использовать для сравнения изображений рисунков часов до и после операции или других повреждений. Та же сеть-энкодер VAE, с минимальной донастройкой, может создавать новые классификаторы для различных задач за короткое время, используя скудные вычислительные ресурсы. Более того, такие модели могут быть обучены «на лету» для мониторинга изменений в рисунках часов с течением времени, тем самым служа простой и эффективной системой мониторинга нейрокогнитивного здоровья человека.
Заключение
Таким образом, в данном исследовании мы показали, что CDT сохраняет свой дискриминационный потенциал даже при сжатии до экономного двумерного пространства. Полусупервизорные модели DL, обученные на неразмеченных наборах данных рисунков часов, извлекли генеративные признаки часов, которые достаточно информативны для построения классификатора деменции. Это первое исследование, использующее методы полусупервизорного DL для анализа цифровых рисунков часов. В будущем мы расширим классификатор, используя графомоторные и временные признаки, доступные из dCDT, и улучшим латентное пространство VAE с помощью разделительного VAE в поисках соответствия между конкретными ошибками в рисунках часов и лежащими в основе когнитивными патологиями.
Методы
Участники
Материалы исследования были собраны из данных консорциума цифрового рисования часов между Университетом Флориды (UF) и Нью-Джерсийским институтом успешного старения (NJISA), программой оценки памяти, Школой остеопатической медицины, Университетом Роуэна. Институциональные наблюдательные советы (IRB Университета Флориды и IRB Университета Роуэна, Нью-Джерсийский институт успешного старения) одобрили это исследование, и участники обоих учреждений дали разрешение, подписав формы информированного согласия. Все процедуры исследования проводились в соответствии с Хельсинкской декларацией и соответствующими руководствами учреждений. Для данного исследования было две когорты данных:
Обучающий набор данных включал набор из 13 580 рисунков часов от участников в возрасте ≥ 65 лет, в основном говорящих на английском языке, которые выполняли рисование часов по команде и копирование в рамках регулярной медицинской оценки в предоперационном периоде. Данные собирались с января 2018 года по декабрь 2019 года. Критерии исключения были следующими: недостаточный уровень владения английским языком; образование < 4 года; ограничения зрения, слуха или подвижности конечностей, которые потенциально могут препятствовать выполнению действительного рисунка часов.
Классификационный набор данных — состоит из наборов «донастройка», «тест» и «вторичная валидация» с группой лиц, соответствующих критериям деменции, и отдельным набором данных от их сверстников без деменции. Рисунки часов с деменцией взяты у лиц, обследованных в рамках программы оценки памяти в сообществе Университета Роуэна в период с февраля 2016 года по март 2019 года. Лица осматривались нейропсихологом, психиатром и социальным работником. Критерии включения: возраст ≥ 55 лет. Критерии исключения: черепно-мозговая травма, сердечно-сосудистые заболевания или другие серьезные медицинские заболевания, которые могут вызвать энцефалопатию; тяжелые психические расстройства; документально подтвержденное нарушение обучаемости; эпилепсия или другое серьезное неврологическое расстройство; образование ниже 6-го класса и история злоупотребления психоактивными веществами. Все участники с деменцией проходили оценку с помощью MiniMental State Exam (MMSE), анализа сыворотки крови и МРТ головного мозга. Эти лица были описаны в предыдущих исследовательских работах. Как описано в предыдущих научных статьях, этим лицам был поставлен диагноз AD или VaD соответственно, используя стандартные диагностические критерии.
Сверстники без деменции прошли исследовательский протокол нейропсихологических измерений и нейровизуализации, с данными, проверенными двумя нейропсихологами. Критерии включения: возраст ≥ 60 лет, английский язык как основной, наличие ненарушенных повседневных функций (ADLs) согласно Шкале повседневной активности Lawton & Brody, заполненной как участником, так и их опекуном. Критерии исключения: клинические признаки тяжелого нейрокогнитивного расстройства на исходном уровне, согласно Диагностическому и статистическому руководству по психическим расстройствам — пятое издание, наличие значительного хронического медицинского состояния, тяжелого психического расстройства, истории черепно-мозговой травмы/нейродегенеративного заболевания, документально подтвержденного нарушения обучаемости, эпилепсии или другого серьезного неврологического заболевания, образование ниже 6-го класса, злоупотребление психоактивными веществами в прошлом году, тяжелые сердечные заболевания и энцефалопатия, вызванная хроническим медицинским заболеванием. Участники проходили скрининг на деменцию по телефону с использованием Telephone Interview for Cognitive Status (TICS); и во время очного собеседования с нейропсихологом и обученным координатором исследования, который также оценивал степень коморбидности, тревожность, депрессию, ADLs, нейропсихологическое функционирование и цифровое рисование часов. Данные этих участников собирались с сентября 2012 года по ноябрь 2019 года. Эти данные были описаны в других работах.
Процедура
Участники когорты выполнили два рисунка часов — один по команде, другой — копируя образец. Условие команды требовало от участников «Нарисуйте циферблат часов, нанесите все цифры и установите стрелки на десять минут двенадцать». Условие копирования требовало от участников нарисовать часы под предложенным образцом часов. Рисунки выполнялись с помощью цифровой ручки Anoto, Inc. и соответствующей смарт-бумаги. Технология цифровой ручки фиксирует и измеряет положение пера на смарт-бумаге 75 раз в секунду. Бумага размером 8,5 x 11 дюймов была сложена пополам, предоставляя участникам область для рисования размером 8,5 x 5,5 дюйма для каждых часов. Для данного проекта для анализа использовались только окончательные рисунки.
Данные из обучающей когорты, состоящей из 13 580 неразмеченных рисунков часов по команде и копирования, использовались для обучения VAE в режиме неконтролируемого обучения. Затем обученная сеть-энкодер VAE, которая сжимала рисунки часов в низкоразмерное латентное пространство, была донастроена для различения рисунков часов с деменцией и контрольных рисунков. Командные и копировальные рисунки не разделялись на этом этапе, поскольку мы хотели, чтобы модель извлекала признаки из рисунков часов способом, не зависящим от каких-либо когнитивных исходов. Это позволяет сохранить извлеченные признаки общими и полезными для любой последующей задачи классификации. Латентные признаки, извлеченные VAE, были переданы в классификационную сеть для различения деменции и контрольной группы. Эта сеть была донастроена с использованием 53 рисунков часов с деменцией и 60 — контрольных, протестирована на 18 рисунках часов с деменцией и 20 — контрольных, и дополнительно валидирована на еще 41 рисунке часов с деменцией и 50 — контрольных. Блок-схема, иллюстрирующая процесс создания этих трех наборов данных, показана на Дополнительном рисунке S3. Наборы данных для донастройки и тестирования были созданы путем случайного перемешивания классификационного набора данных и разделения его в соотношении 3:1. Следовательно, демографических различий между наборами данных для донастройки и тестирования не было.
Отдельные эскизы часов извлекались из файла с помощью обнаружения контуров. Извлеченные изображения затем были выровнены в одномерные векторы. Эти векторы были отфильтрованы, чтобы сохранить те, размер которых был менее 40 000 пикселей (200x200). Этот шаг фильтрации был необходим для удаления изображений часов, содержащих чрезмерное количество белого пространства из-за проблем с разреженностью информации. Поскольку рисунки часов становились более разреженными, VAE пытался кодировать внутреннее белое пространство часов вместо нарисованных признаков, т.е. цифр, стрелок или окружности. Это привело к плохим распределениям латентного пространства, напоминающим белый шум (Дополнительный рисунок S2), высоким ошибкам реконструкции и неэффективным весам энкодера VAE. Поэтому мы ограничили размеры часов максимальным значением 200x200 пикселей. Отфильтрованные часы затем были изменены до фиксированного размера 100x100 и преобразованы в одномерные векторы (10 000x1). Эти одномерные представления использовались в качестве входных данных для VAE. Шаги предварительной обработки проиллюстрированы на Дополнительном рисунке S4. Мы воспроизвели эту предварительную обработку для извлечения 71 рисунка часов с деменцией и 80 — контрольных из общего числа 112 рисунков с деменцией и 350 — контрольных, которые были изначально собраны с использованием вышеописанных критериев исключения. Они были разделены на 53 рисунка с деменцией и 60 — контрольных для донастройки энкодера VAE, и 18 рисунков с деменцией и 20 — контрольных для его тестирования. Однако мы также использовали оставшиеся 41 рисунок часов с деменцией и 50 случайно выбранных контрольных рисунков для подготовки вторичного валидационного набора данных, как показано на Дополнительном рисунке S3.
Модели и экспериментальная установка
Вариационный автоэнкодер (VAE) — это генеративная модель без учителя, состоящая из фазы кодирования, которая проецирует входные данные в низкоразмерное латентное пространство, и фазы декодирования, которая реконструирует входные данные из случайных выборок, взятых из этого латентного пространства (рис. 5). В модели VAE распределение латентного пространства создается при условии, что оно следует Гауссову распределению N({Z}_{m}, {Z}_{s}). Это делает VAE генеративной моделью, поскольку он может случайным образом выбирать из этого распределения латентного пространства для создания изображений, похожих на входные данные, которые не обязательно присутствуют во входном наборе данных. Использование нормального распределения в качестве априорного не приводит к потере общности, поскольку нелинейная сеть-декодер может имитировать произвольные распределения входных данных. Никакая информация о генеративных признаках рисования часов (например, общая длина штрихов, симметрия циферблата, координаты стрелок, количество цифр и т. д.) не была предоставлена сети VAE, и у нас не было априорных ожиданий, что латентные измерения будут представлять эти генеративные признаки. Мы использовали одномерные представления рисунков часов для обучения VAE с входным измерением 10 000, промежуточным измерением 512 и размерностью вложения 2. Размерность вложения была намеренно оставлена чрезвычайно низкой, чтобы выяснить, может ли такое низкоразмерное многообразие извлекать значимые признаки часов, полезные для классификации. Модель обучалась в течение 50 эпох с размером пакета 16. Потеря реконструкции VAE была выбрана как функция потерь бинарной кросс-энтропии. Обученное латентное представление VAE использовалось в качестве входных данных для полносвязного нейронной сети прямого распространения с одним скрытым слоем из 512 нейронов для задач классификации. Рисунок 5 показывает архитектуру наших сетей и концептуальный рабочий процесс нашего метода. Верхняя часть рисунка показывает обучение VAE. Нижняя часть рисунка показывает, как сжатое латентное пространство VAE, в форме обученных весов энкодера, использовалось для создания классификатора, специфичного для задачи. Сеть-классификатор имела архитектуру полносвязного нейронной сети прямого распространения. Мы донастроили веса этого классификатора с использованием небольшого аннотированного набора данных для донастройки, чтобы улучшить его производительность. Количество нейронов в каждом слое этого классификатора было определено с использованием случайного поиска по сетке в рамках трехкратной перекрестной проверки. Указанное количество нейронов дало наилучшую среднюю производительность на наборе данных для донастройки по результатам трехкратной перекрестной проверки. Наконец, производительность этого обученного классификатора была валидирована на двух валидационных наборах данных, и были сообщены несколько важных метрик производительности, а именно AUROC, точность, чувствительность, специфичность, точность и отрицательная предсказательная ценность (NPV). Валидационные данные бутстрапировались 100 раз с использованием случайной выборки с заменой для создания доверительных интервалов этих метрик. Сообщаемые значения составляют медианную оценку, 2,5-й перцентиль и 97,5-й перцентиль этих метрик по бутстрапированным валидационным наборам данных.