Интересное сегодня

Исследование взаимосвязей между обработкой букв, слов и предложений при чтении
Многочисленные предыдущие исследования в области чтения были сосредоточены на определенном уровне обработки, часто на уровне букв, слов или предложений. Здесь, впервые у взрослых читателей, представлено комплексное исследование этих трех ключевых составляющих процесса понимания прочитанного. Мы провели его, протестировав одну и ту же группу участников в трех задачах, которые, как предполагается, отражают обработку на каждом из этих уровней: буквенное решение (alphabetic decision), лексическое решение (lexical decision) и грамматическое решение (grammatical decision). Участники также выполнили задачу классификации, не связанную с чтением, с целью выделения общих процессов бинарного принятия решений из корреляций между тремя основными задачами. Мы исследовали парные частичные корреляции времени реакции (ВР) в трех задачах чтения. Результаты выявили сильные значимые корреляции между смежными уровнями обработки (т.е. буква-слово; слово-предложение) и незначимую корреляцию между несмежными уровнями (буква-предложение). Результаты предоставляют новый важный эталон для оценки вычислительных моделей, описывающих, как буквы, слова и предложения способствуют пониманию прочитанного.
Введение
Для читателей языка, использующего алфавитное письмо, беглое чтение по существу включает извлечение информации о буквах и их позициях для идентификации слов и порядка слов, а затем построение репрезентации на уровне предложения для понимания. Хотя это сознательное упрощение игнорирует хорошо установленные роли фонетики1,2 и морфологии3 в умелом чтении, а также процессы более высокого уровня, задействованные в понимании текста4, мы считаем, что оно точно освещает три ключевых компонента, участвующих в преобразовании визуальных признаков в значение при чтении. В настоящем исследовании мы впервые изучаем взаимодействия обработки между этими тремя уровнями. Предыдущие исследования были либо сосредоточены на одном уровне обработки, либо на взаимодействии между двумя уровнями (буква-слово или слово-предложение: эти взаимодействия соответственно проиллюстрированы на путях (a) и (b) на рис. 1). Тем не менее, мы отмечаем, что, в отличие от исследований взрослых, в исследованиях развития чтения обычно используются несколько задач, таких как чтение вслух, быстрое автоматизированное называние (RAN - Rapid Automatized Naming) и понимание прочитанного (например, Landerl et al.5, Lefèvre et al.6, Muter et al.7). Сосредоточение на обработке букв, слов и предложений позволило нам использовать три очень сопоставимые задачи при измерении обработки на каждом из этих уровней. Это задачи буквенного решения8, лексического решения9 и грамматического решения10. Все три задачи являются скоростными бинарными задачами принятия решений с четко определенной целевой категорией и четкими критериями для построения нецелевых стимулов (см. примеры на рис. 1).
Для изучения взаимодействий между этими тремя ключевыми компонентами процесса в настоящем исследовании участники выполняли задачи буквенного, лексического и грамматического решения, и мы исследовали корреляции между производительностью в каждой из трех задач с целью оценки взаимозависимости обработки между каждым из трех предполагаемых уровней: буква, слово, предложение. Затем мы использовали полученные корреляции для изучения возможных различий во взаимозависимостях между обработкой на уровне букв, слов и предложений. Таким образом, возможно, что распознавание слов сильно ограничено обработкой на уровне букв, в то время как подобная зависимость может быть не такой сильной для обработки на уровне слов и предложений. Теоретически также интересно спросить, может ли обработка на уровне букв напрямую ограничивать обработку на уровне предложений. Например, в модели чтения предложений OB1reader11 длина слова в количестве букв напрямую влияет на то, как различные идентификаторы слов назначаются определенной позиции в строке текста.
Общая теоретическая основа, направляющая это исследование, вдохновлена моделью интерактивной активации12,13,14,15. Здесь мы применяем эту модель в ее простейшей форме, ссылаясь исключительно на различные уровни обработки, постулируемые в ней, и оставляя в стороне некоторые центральные предположения о природе обработки (например, параллельная, каскадная, интерактивная). В отношении настоящего исследования ключевым аспектом этой модели является то, что обработка происходит иерархически, от одного уровня к следующему. Эта простая иерархическая модель чтения проиллюстрирована на рис. 1. Мы сразу признаем намеренно упрощенный характер этой архитектуры, которая игнорирует хорошо установленную роль фонетики и морфологии в чтении (например, Grainger16). Это упрощение было необходимо для генерации четких предсказаний относительно потенциальных связей в производительности между различными задачами чтения.
Эта иерархическая архитектура делает четкие предсказания о том, как обработка на данном уровне должна влиять на обработку на других уровнях. Если обработка на уровне букв является ключевым компонентом распознавания слов, и если задача буквенного решения точно отражает обработку на уровне букв, а задача лексического решения точно отражает обработку на уровне слов, то корреляция между производительностью в этих двух задачах должна быть очень высокой. То же рассуждение применимо к обработке на уровне слов и предложений, предполагая, что задача грамматического решения точно отражает обработку на уровне предложений. Изучение межзадачных корреляций между буквенным решением и лексическим решением, с одной стороны, и лексическим решением и грамматическим решением, с другой, позволит нам оценить относительный вклад различных компонентов процесса в общую задачу чтения.
Предыдущие исследования предоставляли доказательства интересных параллелей между обработкой буква-слово, с одной стороны, и обработкой слово-предложение, с другой. "Эффект превосходства слова"17,18,19 относится к более высокой точности идентификации отдельной буквы, когда целевая буква представлена в слове (например, буква B в TABLE), по сравнению с псевдословом (например, буква B в PABLE). Недавно был сообщен "эффект превосходства предложения"20,21, при котором идентификация целевого слова лучше, когда это слово представлено в контексте правильного предложения (например, цель BOY в предложении: "the boy runs fast"), по сравнению с идентификацией того же слова в той же позиции в неграмматичной последовательности (например, "runs boy fast the"). Дополнительным пунктом для сравнения, представляющим особый интерес для настоящей работы, являются эффекты транспонированных букв, наблюдаемые в задаче лексического решения (труднее классифицировать несуществующее слово, образованное транспозицией двух букв в реальном слове (например, "gadren", полученное из "garden"), по сравнению с несуществующими словами, образованными заменой двух букв (например, "gatsen")22,23,24, и эффекты транспонированных слов в задаче грамматического решения (труднее отвергнуть неграмматичные последовательности, образованные транспозицией двух слов в правильном предложении (например, "The white was cat big"), по сравнению с последовательностями, которые не могут быть преобразованы в правильное предложение путем транспонирования любых двух слов (например, "The white was cat slowly")10,25. Важным моментом, относящимся к настоящему исследованию, является тот факт, что подобные явления могут наблюдаться на стыках "буква-слово" и "слово-предложение".
В настоящем исследовании мы использовали три задачи, которые ранее применялись для изучения обработки на уровне букв, слов и предложений. Крайне важно, что все три задачи требуют скоростного бинарного решения о том, принадлежит ли целевой стимул к четко определенной категории (буквы, слова, предложения) относительно фона стимулов, разработанных для усложнения дискриминации. Настоящее исследование было мотивировано гипотезой, что эти три задачи могут предоставить сопоставимую информацию об обработке на уровне букв, слов и предложений соответственно. Задача буквенного решения включает скоростную дискриминацию "буква против не-буквы". В настоящем исследовании мы решили использовать псевдобуквы, предоставленные Vidal et al.26, как наилучшее сравнение с псевдословами, которые обычно используются в задаче лексического решения. Прямое доказательство того, что эта задача действительно отражает обработку на уровне букв, было предоставлено New и Grainger27, где были сообщены устойчивые эффекты частоты букв. Задача лексического решения — это, по сути, наиболее широко используемая задача для изучения распознавания одиночных слов. Скоростная версия задачи грамматического решения является более новым изобретением. Традиционно суждения о грамматичности или правильности формы использовались лингвистами в исследованиях на бумаге и карандаше о природе синтаксического знания. Mirault et al.10 использовали скоростную бинарную версию суждений о грамматичности (названную "задачей грамматического решения" Mirault и Grainger28), где они манипулировали природой неграмматичных последовательностей. Здесь мы использовали задачу грамматического решения как аналог на уровне предложений лексическим решениям для слов и буквенным решениям для букв. Таким образом, неграмматичные последовательности были выбраны так, чтобы они были похожи на предложения, так же как псевдослова были похожи на слова, а псевдобуквы — на буквы.
В настоящем исследовании мы ставили задачу изучить межзадачные корреляции с производительностью в трех вышеописанных задачах с одной и той же группой участников. Это первый случай, когда такие межзадачные корреляции исследовались на разных уровнях обработки. Поскольку ожидается, что объем общей обработки будет больше между двумя смежными уровнями (буква-слово; слово-предложение), чем между двумя несмежными уровнями (буква-предложение), мы предсказывали, что смежные уровни обработки (буква-слово; слово-предложение) должны демонстрировать более сильные корреляции, чем корреляция для несмежных уровней обработки (буква-предложение).
Участники также были протестированы в скоростной задаче принятия решений "животное / не-животное" с использованием рисунков знакомых животных и неодушевленных предметов. Цель заключалась в использовании производительности в этой не-чтенийской задаче для частичного исключения вклада общих механизмов бинарного принятия решений в корреляции между тремя задачами чтения. Эта конкретная задача, по сравнению, например, с простой задачей обнаружения стимула, имеет преимущество в том, что она включает большую глубину обработки при использовании нелингвистических стимулов. То есть, задача принятия решений о животном включает скоростное бинарное принятие решений на основе семантической информации (т.е. "животность"), извлеченной из визуальной информации, и мы считали это наилучшим средним приближением к объему обработки, задействованному в трех задачах чтения. Хотя буквенное решение, вероятно, не включает семантическую информацию, мы считаем, что задача принятия решений о животном является хорошей точкой сравнения для этой задачи в той степени, в которой обе задачи включают скоростное бинарное принятие решений на основе простых визуальных стимулов. Тем не менее, мы отмечаем, что мы, возможно, не нашли наиболее подходящую базовую (не-чтенийскую) задачу. Поэтому для будущих исследований будет важно изучить, как использование другой задачи здесь (или других задач) может повлиять на полученные результаты.
Результаты
Данные
Набор данных состоял из 29 520 наблюдений: 4920 для задачи буквенного решения (Alphabetical Decision Task, ADT), 9840 для задачи лексического решения (Lexical Decision Task, LDT), 9840 для задачи грамматического решения (Grammatical Decision Task, GDT) и 4920 для задачи не-чтения (NonReading Task, NRT). Во-первых, мы приводим описательную статистику по ВР и частоте ошибок, чтобы дать обзор производительности в каждой задаче. Средние значения для ВР и частоты ошибок представлены в Таблице 1. Основной анализ задачи лексического решения включал все слова, которые были протестированы, в том числе морфологически сложные слова. Дополнительные анализы, ограниченные только морфологически простыми словами, показали точно такую же закономерность.
Времена реакции (ВР)
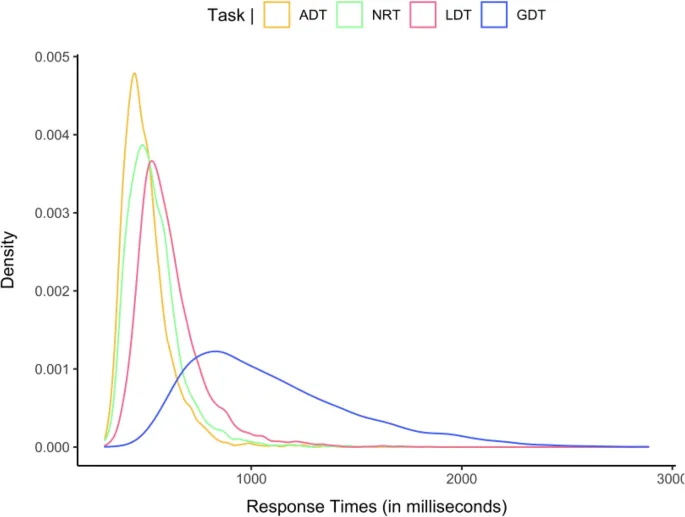
Перед анализом ВР были исключены некорректные ответы (ADT = 2,26%, LDT = 3,56%, GDT = 11,35% и NRT = 2,03%) и корректные ответы со ВР менее 300 мс (ADT = 0,06%, LDT = 0,11%, GDT = 0,03% и NRT = 0,02%). Затем были исключены испытания с выбросами, определенными как ВР более чем на 2,5 стандартных отклонения выше или ниже среднего значения участника в зависимости от типа ответа (ADT = 2,95%, LDT = 3,04%, GDT = 2,39% и NRT = 3,17%). Средние значения для корректных ответов "да" и "нет" по задачам представлены в Таблице 1, а распределения ВР для корректных ответов "да" показаны на рис. 2. Было обнаружено, что ВР увеличиваются по мере увеличения сложности задачи, а корректные ответы "да" были быстрее, чем корректные ответы "нет" во всех задачах. Более того, соотношение средних ВР между задачами показало, что для получения корректного ответа "да" требуется примерно одинаковое время в NRT и ADT (0,93), в то время как это соотношение увеличивалось по мере увеличения сложности задачи (ADT против LDT = 1,14, LDT против GDT = 2,05).
Частота ошибок
Средние значения частоты ошибок для ответов "да" и "нет" по задачам приведены в Таблице 1. Анализ частоты ошибок выявил относительно мало ошибок в NRT, ADT и LDT (частота ошибок ниже 5% как для корректных ответов "да", так и "нет"), в то время как более высокие частоты ошибок наблюдались в GDT (6,30% для корректного ответа "да" и 16,4% для корректного ответа "нет").
Межзадачные корреляции по ВР
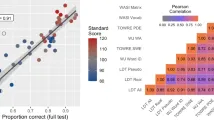
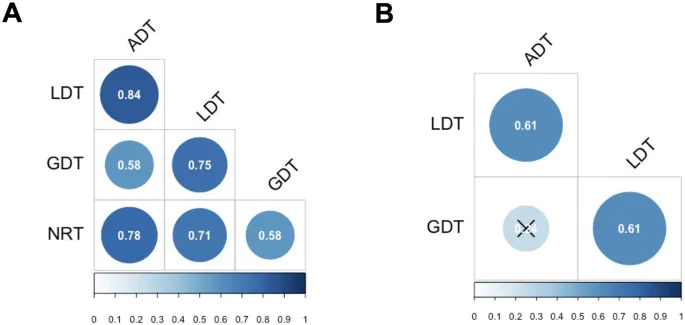
На рис. 2A представлены корреляции Пирсона между стандартизированными средними ВР на одного участника по корректным ответам "да" (N = 41), полученными в различных задачах, рассчитанные с помощью пакета Hmisc в R29. Как и предсказывалось, задачи, оценивающие иерархически смежные уровни обработки, показали более сильную корреляцию (r(ADT, LDT) = 0,83; r(LDT, GDT) = 0,76), чем задачи, оценивающие иерархически удаленные уровни обработки (r(ADT, GDT) = 0,56). Все эти корреляции были значимыми (p < 0,001). Более того, NRT коррелировал сильнее с ADT (r = 0,78) и LDT (r = 0,72), чем с GDT (r = 0,57). Эта описательная закономерность была подтверждена анализом статистической разницы между корреляциями с использованием пакета cocor R30. Разница между корреляциями, включающими смежные уровни, не была статистически значимой (r(ADT, LDT) = 0,83 против r(LDT,GDT) = 0,76, p = 0,35), в то время как различия между корреляциями, включающими несмежные уровни, были значимыми (r(ADT, GDT) = 0,56 против r(ADT, LDT) = 0,83, p < 0,001; r(ADT,GDT) = 0,56 против r(LDT,GDT) = 0,76, p < 0,01).
Эти результаты можно объяснить тем, что бинарный процесс принятия решений, общий для всех задач, оказывает большее влияние на задачи с наименьшим когнитивным требованием, как в ADT и LDT, где обработка букв и слов высоко автоматизирована, по сравнению с GDT. Чтобы контролировать влияние этого бинарного процесса принятия решений на корреляции, мы вычислили частичные корреляции между ADT, LDT, GDT, контролируя влияние NRT. Результаты (см. рис. 2B) показали, что все корреляции оставались значимыми (r(ADT, LDT) = 0,61, p < 0,001; r(LDT, GDT) = 0,61, p < 0,001). Однако, когда компонент бинарного принятия решений был контролируем, корреляция между несмежными уровнями обработки больше не была значимой (r(ADT, GDT) = 0,24, p = 0,14).
Сравнение распределений ВР
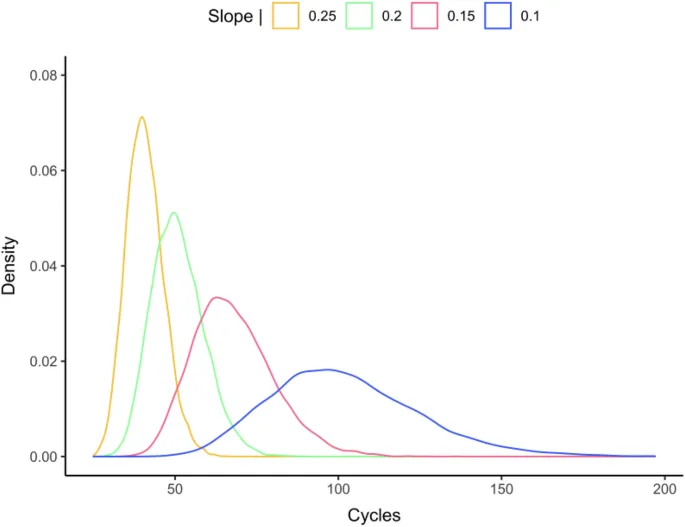
Чтобы предоставить неформальную демонстрацию того, что производительность в четырех задачах сопоставима, несмотря на различия в средних ВР, на рис. 3 представлены распределения ВР для этих задач. Хотя форма распределений менялась между четырьмя задачами, мы подозреваем, что это связано с изменением сложности задачи (изменение общего среднего ВР), которое затем влияет на разброс распределений. Наиболее прямое объяснение этого изменения распределения ВР заключается в том, что увеличение сложности задачи приводит к падению скорости накопления информации. Более медленная скорость накопления информации привела бы к увеличению среднего ВР, а также к более плоским распределениям ВР, как видно из эмпирических распределений на рис. 3. На рис. 4 мы предоставляем неформальное доказательство концепции, что это вполне может быть так. Для этого мы сгенерировали теоретические распределения ВР с использованием простой модели случайного блуждания с фиксированным критерием принятия решений, фиксированной начальной точкой и фиксированной дисперсией для случайного блуждания, изменяя только наклон случайного блуждания (т.е. скорость накопления информации) в четырех симуляциях. Изменение скорости накопления информации гипотетически отражало различия в сложности каждой задачи, причем наклон уменьшался по мере усложнения задачи. Теоретические распределения ВР, показанные на рис. 4, показали, что при прочих равных условиях снижение наклона случайного блуждания (от 0,25 до 0,1) имитировало закономерность, наблюдаемую в эмпирических распределениях, с увеличением среднего ВР, связанным с более плоским распределением.
Обсуждение
В настоящем исследовании участники выполняли три задачи с визуальными стимулами, которые, как предполагалось, в первую очередь отражают обработку на уровне букв, слов и предложений. Это были задачи буквенного решения (ADT), лексического решения (LDT) и грамматического решения (GDT). Четвертая задача, не связанная с чтением (NRT), классификация "животное / не-животное", была включена в качестве контрольной задачи для скоростного бинарного принятия решений, включающего семантическую обработку, но с нелингвистическими визуальными стимулами (т.е. изображениями животных и неодушевленных предметов). Предыдущие исследования, обобщенные во введении, предполагали, что эти три задачи чтения хорошо отражают обработку на уровнях букв, слов и предложений соответственно. Более того, три задачи очень сопоставимы в том, что все они включают принятие скоростного бинарного решения, которое дискриминирует между данной целевой категорией (т.е. ответ "да" на буквы, слова или предложения, в зависимости от задачи) против фона псевдостимулов из той же категории (псевдобуквы, псевдослова и неграмматичные последовательности слов). Поэтому мы предположили, что сравнение производительности в этих задачах в одной и той же группе участников прольет свет на взаимосвязи между обработкой на уровне букв, слов и предложений во время чтения.
Первоначальная качественная оценка обработки в трех задачах чтения (см. Таблицу 1) выявила, что, как и ожидалось, сложность задачи увеличивалась (более длительные ВР и больше ошибок как для ответов "да", так и "нет"), по мере увеличения сложности задачи — от ADT к LDT, к GDT. Производительность в задаче не-чтения (NRT) была ближе к ADT, и анализ корреляций выявил ту же закономерность (см. рис. 2). Эта закономерность указывает на добавление лексической (LDT) и предложенческой (GDT) обработки поверх скоростного бинарного принятия решений на основе простых визуальных стимулов, требуемых как в ADT, так и в NRT.
Мы также сравнили распределения ВР в четырех задачах и обнаружили, что по мере увеличения среднего ВР происходило соответствующее увеличение разброса распределения ВР (рис. 3). Затем мы проверили гипотезу, что одним из ключевых лежащих в основе механизмов является скорость накопления информации в пользу ответа "да", которая варьируется в зависимости от сложности задачи, с более медленными скоростями накопления по мере усложнения задачи. Симуляции, проведенные на простой модели случайного блуждания, подтвердили эту интерпретацию, показав, что по мере снижения наклона случайного блуждания (при постоянстве всех остальных параметров) среднее значение и разброс распределения ВР увеличивались, тем самым обеспечивая качественное соответствие закономерности, наблюдаемой в эмпирических распределениях (см. рис. 4).
Однако ключевые результаты настоящего исследования касаются обнаруженных межзадачных корреляций. Эти анализы выявили значимые корреляции между всеми задачами, хотя и с более слабыми корреляциями между ADT и GDT, а также между NRT и GDT. Крайне важно, что после исключения производительности в NRT корреляция между ADT и GDT больше не была значимой. Это отсутствие корреляции между несмежными уровнями обработки (т.е. буквами и предложениями) является явным свидетельством в пользу центральной роли распознавания слов в процессе чтения. Более того, без частичного исключения производительности в NRT, статистические тесты размера корреляций показали, что корреляции между смежными уровнями не отличались статистически значимо, в то время как контрасты между корреляциями смежных уровней и корреляцией несмежного уровня были значимыми.
Настоящие результаты подтверждают простую иерархическую модель чтения, показанную на рис. 1, согласно которой распознавание слов играет центральную роль в процессе чтения, обеспечивая ключевое взаимодействие между начальной обработкой на уровне букв и заключительными этапами обработки на уровне предложений. Несколько моделей чтения текстов отводят центральную роль распознаванию слов в общем процессе чтения предложений (например, EZ Reader31), и несколько также подчеркивают критическую роль орфографической обработки (например, Glenmore13; OB1reader11). Модель OB1reader11 реализует принцип, согласно которому значительная часть читательского поведения может быть охвачена орфографической обработкой, реализованной как обработка букв, буквенных комбинаций и орфографических слов (см. также Grainger16). Настоящие результаты явно благоприятствуют этому общему подходу к чтению. Более того, наши результаты предполагают, что задачи буквенного, лексического и грамматического решения предоставляют ценное окно для обработки на уровне букв, слов и предложений, и позволяют проводить важные сравнения между обработкой (и механизмами, лежащими в основе такой обработки) на этих различных уровнях.
Наконец, мы отмечаем, что одной из популярных альтернатив иерархическому подходу, описанному в настоящей работе, является так называемая "треугольная модель" чтения, впервые предложенная Seidenberg и McClelland32. В этой модели неиерархическая треугольная архитектура соединяет орфографию с фонологией, с одной стороны, и орфографию с семантикой, с другой. Можно было бы расширить это на случай букв, слов и предложений, как исследовалось в настоящей работе, в этом случае модель предсказала бы эквивалентные корреляции между временами обработки букв и слов, слов и предложений, а также между временами обработки букв и предложений. Однако важно подчеркнуть, что ключевая новизна, введенная в треугольную модель, касалась механизмов обучения, а не ментальной хронометрии. Можно также утверждать, что настоящие выводы указывают на общий механизм, лежащий в основе обработки во всех трех задачах чтения, и одной из возможных интерпретаций здесь является понятие "качества" репрезентаций, предложенное Perfetti и Hart33 для лексической обработки. Возможно, что то же понятие "качества" может применяться как к репрезентациям на уровне букв, так и на уровне предложений. Однако этот подход "общего механизма" (и то же самое относится к объяснению "индивидуальных различий" — т.е. лучшие читатели лучше справляются со всеми тремя задачами чтения) должен был бы объяснить различия в корреляциях, которые мы наблюдали между смежными и несмежными уровнями обработки.
Выводы
Мы исследовали иерархическую природу обработки на трех уровнях (буква, слово, предложение), которые, как считается, составляют основу чтения в алфавитном письме. Участники выполнили три задачи, каждая из которых, как предполагалось, отражает обработку на одном из трех уровней. При частичном исключении производительности в скоростной задаче бинарного принятия решений, не связанной с чтением (классификация животных/не-животных по картинкам), мы обнаружили значимые корреляции в производительности на смежных уровнях обработки (буква-слово; слово-предложение), но не между несмежными уровнями (буква-предложение). Более того, размер корреляций статистически значимо отличался при сравнении корреляций между смежными и несмежными уровнями, но не при сравнении смежных уровней. В целом, наши результаты указывают на центральную роль процессов идентификации слов в опосредовании между сублексической обработкой низкого уровня и обработкой высокого уровня на уровне предложений во время понимания прочитанного.
Методы
Участники
Онлайн-исследование, состоящее из трех задач чтения (буквенное решение, лексическое решение, грамматическое решение) и одной задачи не-чтения, было запрограммировано и размещено на сервере Labvanced34. Сорок восемь участников (28 женщин, 20 мужчин) были набраны через Prolific, онлайн-платформу, посвященную набору участников. До начала эксперимента участники были проинформированы о том, что данные будут собираться анонимно, и они предоставили информированное согласие до начала эксперимента. Исследование было одобрено комитетом по этике Comité de Protection des Personnes SUDEST IV (№ 17/051). Эксперимент проводился в соответствии с соответствующими руководящими принципами и правилами, а также в соответствии с Хельсинкской декларацией.
Порядок задач был контрбалансирован между участниками. Семь участников были исключены, поскольку они не показали минимального уровня в 75% корректных ответов во всех задачах. Кроме того, участники заполнили анкету в начале исследования, запрашивающую возраст, пол, родной язык и доминирующую руку. Самоотчет о возрасте дал медианное значение 25 лет (диапазон [18; 31]). Все участники сообщили, что они являются носителями английского языка и правшами. Уровень владения английским языком участников был оценен с помощью компьютерной версии теста на словарный запас Lextale35, проведенного до четырех экспериментальных задач (минимальное количество корректных ответов (CR): 62%, максимальное CR: 100%, среднее CR: 88%, стандартная ошибка: 9%).
Общая процедура
Мы применяли одну и ту же общую процедуру для всех четырех задач. Стимулы отображались черным цветом на сером фоне в центре экрана. Каждое испытание начиналось с 500-миллисекундного фиксационного креста, за которым следовал стимул, который оставался видимым в течение 3000 мс или до тех пор, пока участник не отвечал. Участникам было предложено нажать клавишу "L" для ответа "да" и клавишу "S" в противном случае. Затем экран оставался пустым в течение 800 мс перед следующим испытанием. Все испытания были представлены в случайном порядке. Перед началом каждой задачи участнику предлагалась короткая практическая сессия. Продолжительность каждой задачи составляла около 6 минут для ADT, 12 минут для LDT, 12 минут для GDT и 6 минут для NRT, что в общей сложности составило около 45 минут для всего эксперимента, включая короткие перерывы между задачами.
Дизайн и стимулы
Задача буквенного решения (ADT)
Было выбрано двадцать согласных букв и двадцать псевдобукв из наборов искусственных символов Брюсселя (Brussels Artificial Characters Sets, BACS)26. Мы использовали псевдобуквы из второго набора (BACS2), где каждая псевдобуква была сопоставлена с соответствующей буквой по размеру, количеству штрихов, наличию/отсутствию симметрии, количеству соединений и количеству окончаний. Буквы были представлены шрифтом Lucida Sans Unicode, а псевдобуквы — шрифтом BACS2 sans serif. Каждая буква и псевдобуква были представлены трижды для каждого из трех различных размеров (размер 1: 100×100 пикселей, размер 2: 120×120 пикселей, размер 3: 140×140 пикселей), что составило в общей сложности 120 испытаний.
Задача лексического решения (LDT)
Сто двадцать английских слов были выбраны из тех, которые использовались в грамматически правильных последовательностях задачи грамматического решения (см. следующий раздел). Эти слова были обозначены как прилагательные, существительные или глаголы. Из-за этих критериев отбора некоторые высокочастотные слова, использованные в GDT (такие как определители, артикли, предлоги), не использовались в LDT. Согласно базе данных SubtlexUK36, слова имели среднюю логарифмическую частоту 2,17 (SD = 0,14) и среднюю длину 6,05 буквы (SD = 1,26 буквы). Псевдослова были выбраны из тех, которые использовались в English Lexicon Project37, и были сопоставлены со словами по количеству букв. Стимулы были представлены шрифтом Lucida Sans Unicode размером 14 пунктов.
Задача грамматического решения (GDT)
Стимулы состояли из 240 английских 4-словных последовательностей, образующих грамматически правильную структуру, такую как "alcohol is a toxin". Последовательности были взяты из базы данных Google 4gram English38, где термин "gram" относится к слову.
Отбор стимулов проводился следующим образом. Во-первых, мы выбрали 4-граммы, все слова которых фигурировали в базе данных SubtlexUK39. Затем мы исключили 4-граммы, содержащие прилагательные, существительные или глаголы длиной менее 3 букв или более 8 букв, и частота которых находилась в пределах ±1,75 стандартных отклонения от средней частоты слов. Кроме того, мы убедились, что средняя логарифмическая частота лемм слов на 4-грамму находилась в стандартном интервале [1; 1]. Наконец, мы сохранили 4-граммы со значениями Standard Frequency Index (SFI)40 в диапазоне от 1,83 до 3,83, и удалили 4-граммы, заканчивающиеся определителями, артиклями, предлогами, послелогами и частицами. Для исследования были отобраны двести сорок 4-словных последовательностей. Сто двадцать 4-грамм использовались как корректные грамматические последовательности. Оставшиеся 120 4-грамм использовались для формирования неграмматичных последовательностей путем замены одного или нескольких слов другим действительным английским словом той же длины. Это привело к 120 грамматичным и 120 неграмматичным последовательностям, которые были случайным образом представлены участникам. Стимулы были представлены шрифтом Lucida Sans Unicode размером 14 пунктов.
Задача не-чтения (NRT)
Сорок черно-белых рисунков были отобраны из базы данных MultiPic41. MultiPic — это нормативная база данных из 750 изображений конкретных концепций, предназначенная для исследования процессов языка, зрения, памяти и/или внимания. Из этих 40 рисунков 20 изображали живое существо (например, пингвина), а 20 — неодушевленный предмет (например, зонтик). Живые и неодушевленные рисунки были сопоставлены по всем переменным, доступным в MultiPic: меры согласованности названий, процент действительных ответов, количество различных ответов, процент неизвестных ответов, процент идиосинкратических ответов и визуальная сложность. Рисунки были представлены трижды в трех различных размерах (размеры были сопоставлены с размером букв и псевдобукв, использованных в задаче буквенного решения), что составило 120 испытаний.