Интересное сегодня

Введение
Известно, что читатели испытывают большие трудности при обработке слов, которые менее предсказуемы в контексте предшествующих слов. За последние годы накопилось множество доказательств, подтверждающих идею вероятностного вывода во время обработки языка (Staub, 2024). Эта концепция чтения как непрерывного процесса формирования и проверки гипотез о следующем слове была названа «психолингвистической игрой в угадывание» (Goodman, 1967). Вопросы о том, как и почему читатели используют вероятностный вывод, вызвали дискуссию, которая продолжается по сей день (Federmeier, 2007; Huettig, 2015; Pickering & Gambi, 2018; Pickering & Garrod, 2007; Ryskin & Nieuwland, 2023).
Сурпризальная теория
Наиболее влиятельной теорией вероятностного вывода является сурпризальная теория (Hale, 2001; Levy, 2008). Эта теория постулирует логарифмическую зависимость между контекстуальной вероятностью языковой единицы и когнитивными усилиями, необходимыми для её обработки. Она реализуется как процесс, при котором читатели создают ранжированный набор возможных продолжений предложения. Сложность обработки нового слова связана с количеством перераспределения в обновлённом рейтинге предпочтений (Levy, 2008). Другими словами, чем больше вероятность смещается при интеграции нового слова с предыдущим контекстом, тем сложнее будет обработать это слово (Staub, 2024). Формально влияние слова на распределение вероятностей следующих слов выражается как отрицательный логарифм условной вероятности этого слова — его сурпризальное значение (Levy, 2008). Таким образом, сурпризальность предлагается в качестве третьего ключевого предиктора в дополнение к хорошо изученным эффектам частоты слов (Brysbaert et al., 2018) и длины слов (Hauk & Pulvermüller, 2004).
Оценка предсказуемости слов
Для оценки предполагаемой сложности обработки слова (т.е. сурпризального значения; Smith & Levy, 2013) с использованием его условной вероятности было разработано несколько методов. Изначально вероятности слов оценивались с помощью человеческих экспертов с использованием метода «клоуз-теста» (Taylor, 1953). Эта практика остаётся распространённой (Schuster et al., 2021; Tiffin-Richards & Schroeder, 2020). Позже появились вычислительные альтернативы, такие как N-граммные модели и модели на основе нейронных сетей (Armeni et al., 2017).
Трансформерные модели
В 2017 году была представлена трансформерная модель (Vaswani et al., 2017), которая значительно отличается от предыдущих вероятностных языковых моделей. Основное отличие заключается в механизме внимания, который позволяет модели учитывать наиболее информативные предыдущие слова без размытия влияния более удалённых слов во входной последовательности. В результате модель учится точно представлять зависимости между словами и контекстуальные связи в широком окне контекста. Например, базовая версия GPT-2 имеет окно контекста в 1,024 слова, тогда как более современные модели, такие как Gemini 1.5 Pro, могут обрабатывать до миллиона слов.
Объяснительная сила предсказаний больших языковых моделей (LLM)
Интуитивно кажется, что трансформерная модель с механизмом внимания противоречит человеческому познанию, поскольку она моделирует связи между словами в окне контекста, значительно превышающем объём рабочей памяти человека. Тем не менее, сурпризальные оценки трансформерных моделей лучше отражают человеческие суждения и данные о времени чтения, чем другие вычислительные оценки. Например, Goldstein et al. (2022) обнаружили, что предсказания GPT-2 сильно коррелируют с оценками клоуз-теста носителей английского языка (r = 0.79), а в 50% случаев и человек, и модель присваивали одному и тому же слову наибольшую вероятность.
Связь сурпризальности и времени чтения
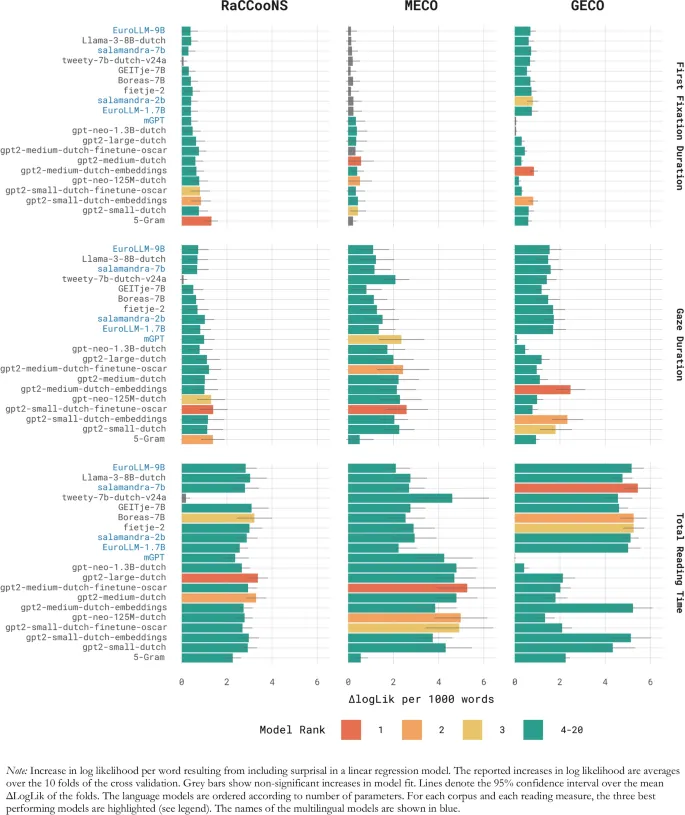
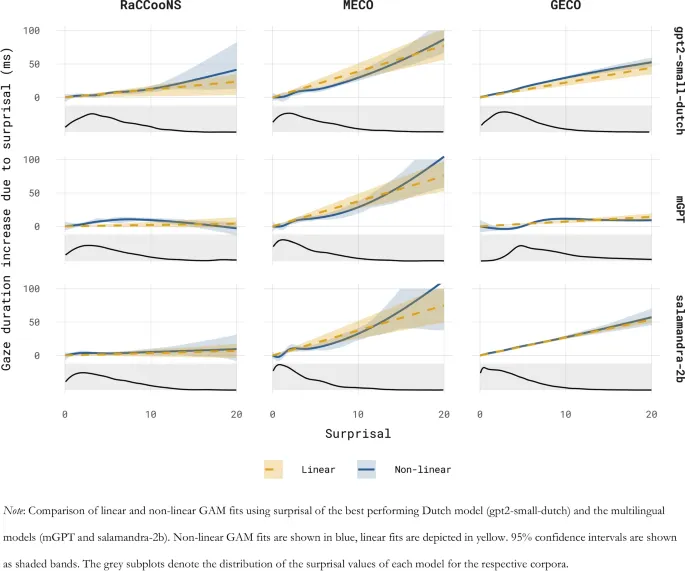
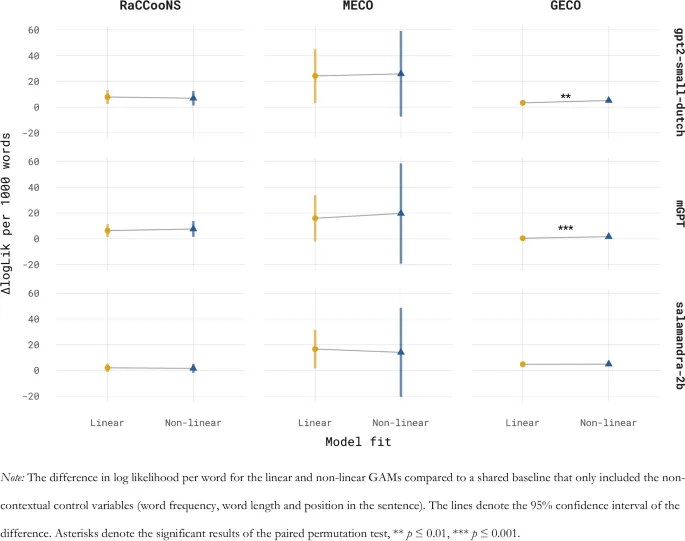
При анализе данных о времени чтения картина оказывается более сложной. Преимущество трансформерных моделей проявляется в более специфических аспектах прогнозирующей обработки. Например, при моделировании времени чтения на английском языке с использованием модели OB1-reader включение вычислительных оценок предсказуемости из трансформерных моделей (например, LLaMA и GPT-2) дало лучшее соответствие, чем оценки клоуз-теста (Rego et al., 2024).
Заключение
В данной статье представлено всестороннее сравнение голландских языковых моделей с общепризнанными многоязычными моделями. Как первый ресурс такого рода, она предлагает ценный инструмент для исследователей, ищущих психометрически валидную языковую модель для голландского языка. Результаты подчёркивают, что оценки сурпризальности, основанные на LLM, требуют тщательного изучения, поскольку их соответствие времени чтения сильно зависит от модели и типа данных.