Интересное сегодня
Контроль внимания: существует ли он как психометрический кон...
Введение Более 20 лет исследователи индивидуальных различий рассматривали контроль внимания как когн...
Как здоровье мозга влияет на стресс, общение и образ жизни
Почему здоровье мозга важно для борьбы со стрессом и общения Чувство перегруженности из-за ежедневно...
Как аудиовизуальные стимулы вызывают иллюзию внетелесного оп...
Иллюзия внетелесного опыта и мультисенсорная интеграцияВиртуальная реальность (VR) позволяет пользов...
Влияние коротких видео в соцсетях на тревожность внешности у...
Введение С розвитком глобальных медиа, использование коротких видео в социальных сетях пережи...
Эффективные стратегии обучения двигательной активности для д...
Введение Двигательные навыки включают широкий спектр способностей, от простых движений, таких как за...
Влияние офисных интриг на конфликт между работой и семьей: р...
Введение В современных условиях растущей сложности деловой среды и размывания границ между профессио...


Введение
Видеозаписи повсеместно используются для изучения поведения человека и животных (Bednarski et al., 2022; Lauer et al., 2022), поскольку они предоставляют надежную запись событий, которую можно просматривать и анализировать в удобное время. В клинических исследованиях, в частности, возникают значительные трудности с видеозаписями и их аннотацией, которые усугубляются при изучении детей. Сценарии записи, как правило, либо срежиссированы, либо полуструктурированы, чтобы изолировать и оценить конкретные (дис)функции. Позиция участников часто ограничена, например, фронтальным положением. Для отслеживания движений или жестов могут использоваться датчики или другие внешние устройства (Muñoz-Organero et al., 2018; Wood et al., 2009). Такие неестественные условия могут исказить восприятие и запись исследуемого поведения (FitzGibbon et al., 2024). Это усугубляется эффектом аудитории (Hamilton & Lind, 2016), предвзятостью в отношениях между участником и исследователем (Moffett et al., 2020; SonugaBarke et al., 2013), культурным фоном участников (Quintela Do Carmo et al., 2024), лингвистическими способностями и использованием родного языка (Cormier et al., 2022; Fernald et al., 2013), а также дополнительным стрессом от наблюдения/съемки незнакомым экспериментатором или клиницистом (Quintela Do Carmo et al., 2024). Поэтому нельзя игнорировать предположения о реальной и повседневной релевантности полуструктурированных интервью, и они вызывают вопросы относительно того, насколько такие инструменты надежно оценивают поведение человека, клинический статус (Gualtieri & Johnson, 2005; Reinecke et al., 1999) или эффективность терапевтических подходов (SempereTortosa et al., 2020).
Техники наблюдения, применяемые к детям, должны учитывать эти сложности (Minder et al., 2018) и проводиться в их естественной среде, как дополнение к полуструктурированным условиям, для количественной оценки повседневного поведения (FitzGibbon et al., 2024; Posserud et al., 2014). Эти соображения также применимы к техникам аннотации. В настоящее время оценка видеозаписей остается преимущественно ручной (Molloy et al., 2011). Успешное выполнение требует наличия достаточного количества обученных специалистов и поддержания их экспертизы. Ручная аннотация громоздка и затратна как финансово, так и по времени (Bulling et al., 2023). Прогресс достигнут во внедрении методов видеоаннотации для распознавания особенностей и жестов, связанных с клиническими симптомами (Kojovic et al., 2021; Watson et al., 2024). Например, Lee et al. (Lee et al., 2023) снимали детей, играющих в серию игр в специфической лабораторной обстановке, чтобы классифицировать детей с синдромом дефицита внимания и гиперактивности (СДВГ) и без него. Ограничением их подхода было то, что ребенок снимался один и без перекрытий. Кроме того, путь и действия были срежиссированы и продемонстрированы роботом, которого дети должны были имитировать. Аналитически, их подход использовал несколько камер для отслеживания скелета и цветные куртки для точной идентификации. Несмотря на эти достижения, методы были продемонстрированы на индивидах, выполняющих срежиссированные движения, и полагаются на множество датчиков записывающих камер (в частности, RGBD). Такие ситуации могут быть неприменимы к стандартным сценариям записи или к естественному поведению нескольких человек, включая случаи, когда человек выходит из поля зрения камеры, а затем возвращается, что создает проблему «повторной идентификации» в компьютерном зрении. В более общем плане, поскольку такие методы нацелены на диагностику, они часто уделяют меньше внимания детальному описанию характеристик движений каждого человека, их изменению со временем, в естественных или межличностных контекстах, или в результате терапевтических вмешательств.
Современные подходы к отслеживанию и повторной идентификации людей в видеоанализе сталкиваются со значительными ограничениями при применении в естественных клинических или поведенческих условиях. Популярные инструменты с открытым исходным кодом, такие как StrongSORT (Du et al., 2023), хотя и эффективны в краткосрочном отслеживании, как правило, переоценивают количество уникальных индивидов из-за чувствительности к длительным перекрытиям и неспособности ограничить максимальное количество идентичностей. Альтернативные методы, такие как DeepLabCut (Lauer et al., 2022; Mathis et al., 2018), требуют обширной ручной аннотации кадров видео, что делает их трудоемкими и непригодными для масштабируемых или автоматизированных решений. Эти недостатки особенно проблематичны в клинических приложениях, где точное и эффективное отслеживание свободно движущихся людей необходимо для понимания сложного поведения без внесения искусственных ограничений или предвзятостей. Кроме того, такие приложения ограничены максимальным количеством людей в данной сессии, поэтому любое методологическое решение должно выигрывать от этого ограничения, а не препятствовать ему. Преодоление этих трудностей требует методов, которые могут надежно отслеживать и повторно идентифицировать людей после перекрытий, работать без необходимости в больших, аннотированных наборах данных и сохранять точность, минимизируя при этом переобнаружение идентичностей.
Представляем ADVANCE: Автоматизированный конвейер для отслеживания и повторной идентификации
Учитывая эти соображения, требуются автоматизированные методы аннотации, которые могут работать в контекстах с участием множества свободно движущихся людей, которые не ограничены и не обременены носимыми устройствами; контексты, которые мы для простоты называем «естественными», поскольку поведение людей не ограничено, а класс художественных занятий не был специально структурирован или оборудован/очищен для записи. Здесь мы представляем «ADVANCE» – автоматизированный конвейер для отслеживания и повторной идентификации людей после периодов перекрытия (например, когда человек перекрыт другим человеком или объектом), преодолевающий некоторые ограничения, связанные с альтернативными методами с открытым исходным кодом. Мы также демонстрируем полезность этих методов для последующего анализа, классифицируя позу человека как сидячую или стоячую. Он также предоставляет ряд ключевых преимуществ по сравнению с существующими альтернативами, которые для любого данного видео либо имеют тенденцию переоценивать количество уникальных людей, либо требуют значительного набора размеченных вручную примеров для каждого человека. Таким образом, подход снижает клиническую нагрузку и повышает этологическую достоверность, предлагая масштабируемые решения для анализа поведения в естественных условиях.
Методы
Описание набора видеоданных
Мы использовали набор данных из более чем 150 видео, снятых во время сеансов арт-терапии, проводимых федерально лицензированным арт-терапевтом в дневном центре под эгидой Отделения психиатрии Университетской больницы Лозанны (CHUV). Видео были записаны в рамках более широкого клинического исследовательского проекта и после получения письменного информированного согласия родителей или законных представителей детей. Все процедуры записи были одобрены кантональным этическим комитетом по исследованиям на людях (протокол CERVD № 202201488) и соответствовали Хельсинкской декларации. Видео были сняты с помощью камеры Microsoft Azure Kinect, установленной в верхнем углу художественной студии, обеспечивая обзор сцены (Рис. 1). Эти еженедельные записи охватывают 20–24 недели и в общей сложности включают 14 детей в возрасте 7–12 лет на момент записи (более подробная информация приведена ниже). У этих детей были диагностированы СДВГ, РАС, трудности в обучении и поведенческие нарушения, подтвержденные стандартизированными диагностическими анкетами и клиническими наблюдениями лицензированных психологов и психиатров Отделения детской и подростковой психиатрии в составе Отделения психиатрии Университетской больницы Лозанны и Университета Лозанны.
Рис. 1 Пример видеокадров RGB, демонстрирующих обстановку, в которой производились записи, и подчеркивающих сложность сцены и поведения человека. Видео включали нескольких человек в различных положениях/ориентациях относительно камеры, случаи выхода и повторного входа в поле зрения, а также сложные взаимодействия с объектами (например, ношение картонной коробки, как в среднем кадре). На изображении видео были размыты и заблюрены для защиты личностей.
В общей сложности для целей настоящего исследования было проанализировано 36 видеосессий. Двенадцать из них содержали двух человек, восемь — трех, восемь — четырех и восемь — пять человек. Среди этих видео были 15 уникальных детей (все мальчики; возраст 7–12 лет; семь белых и восемь других) и шесть уникальных взрослых (все женщины; возраст 25–50 лет; пять белых и одна другая). Помимо ребенка/детей, присутствовавших в художественной студии, были также 1–2 взрослых, по крайней мере один из которых был федерально лицензированным арт-терапевтом. На Рисунке 1 показаны примеры сложных сцен, которые рассматривались. Студия художественных занятий оснащена несколькими столами, стульями и предметами. Дети участвовали в индивидуальных или групповых сеансах арт-терапии в рамках предписанного стандартного ухода. Обработанный видеопример с взрослыми в студии, а также предполагаемые скелеты и соответствующее сопоставление идентификаторов доступны онлайн (https://osf.io/xrsnw/files/osfstorage?view_only=9f09d98040d24616bf1c30af18ff31a3), что демонстрирует достоверность методов, разработанных в данном исследовании.
В этой обстановке дети могли взаимодействовать с различными материалами (например, карандашами, ручками, красками, глиной, песком и т. д.), создавать конструкции из переработанных материалов, играть с традиционными игрушками (фигурками или Lego), заниматься символическими играми, готовить простые хлеб или выпечку, или взаимодействовать с музыкальными инструментами. Сессии содержали либо полуструктурированные мероприятия, предложенные терапевтом, либо были инициированы ребенком. Дети приходили в студию, стояли или сидели за большим столом в центре комнаты и занимались деятельностью в течение примерно 30–45 минут. В зависимости от типа деятельности во время сеанса ребенок перемещался по студии, чтобы достать материалы из шкафов или различных стеллажей, и работал над одним или несколькими типами проектов. Сессии состояли либо из одного взрослого с одним ребенком, либо из 1–2 взрослых с 2–3 детьми. Примечательно, что все взрослые также активно участвовали в мероприятиях, либо создавая что-то сами, либо помогая детям с различными материалами. Виды деятельности, выполняемые как детьми, так и взрослыми на этих видео, включали: рисование и живопись, конструирование из Lego, изготовление масок, лепку из глины, игру на музыкальных инструментах, символическую игру и т. д. Эти сессии включали широкий спектр занятий, а также большое количество потенциальных перекрытий как объектами, так и другими людьми.
Вычислительные аспекты
Мы протестировали подход на машине под управлением Ubuntu 22.04 LTS с NVIDIA 2080ti, 126 ГБ ОЗУ и процессором Intel i99900K 3,6 ГГц. Время выполнения различных этапов системы тестировалось на видео продолжительностью 42 секунды, состоящем из 1282 кадров с частотой 30 кадров в секунду, с разрешением 568 × 320, с участием двух уникальных человек. Результаты показывают, что без оценки позы скелета процесс повторной идентификации ADVANCE работает со скоростью в 1,7 раза быстрее реального времени. В отличие от этого, StrongSORT (также использующий YOLOv8 для обнаружения людей) обрабатывает видео с двумя уникальными людьми на том же оборудовании со скоростью в 0,8 раза быстрее реального времени. Когда OpenPose (Cao et al., 2018) используется для оценки позы скелета, время обработки ADVANCE составляет 6,9 раз быстрее реального времени. Это время обработки пропорционально увеличивается с количеством людей.
Обзор инструментария
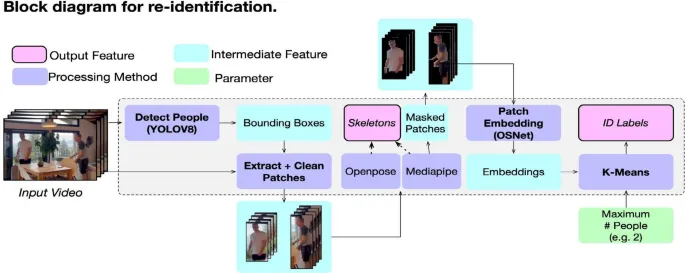
В отличие от существующих методов, инструментарий ADVANCE требует только указания максимального количества уникальных идентичностей в видео, тем самым избегая переоценки количества людей и необходимости в размеченных примерах. На Рисунке 2 показана высокоуровневая диаграмма конвейера для отслеживания людей и оценки скелета. Здесь мы представляем краткое изложение. Код для конвейера повторной идентификации доступен по адресу https://osf.io/4mfsk/.
Рис. 2 Конвейер для повторной идентификации людей в видео.
- YOLOv8 (Varghese & Sambath, 2024) (реализация Ultralytics; https://github.com/ultralytics/ultralytics) сначала используется для обнаружения присутствия людей на каждом кадре и извлечения местоположений ограничивающих рамок для каждого человека (мы используем модель yolov8x.pt, доступную через репозиторий Ultralytics). На этом этапе отслеживание не производилось. Ограничивающие рамки используются для извлечения фрагментов изображения для областей изображения, содержащих обнаруженных людей. Фон в этих фрагментах изображения затем маскируется с использованием Mediapipe (Lugaresi et al., 2019). Маскирование важно для последующей кластеризации, чтобы предотвратить влияние изменений фона (например, мебели, цвета стен и т. д.) на кластеризацию фрагмента изображения, которая должна основываться исключительно на внешнем виде человека, а не на его окружении.
- Именно на этом этапе оцениваются позиции скелета людей в маскированных фрагментах изображения с использованием OpenPose (Cao et al., 2018). Следует отметить, однако, что эти скелеты не используются для отслеживания. Затем маскированные фрагменты встраиваются с использованием OSNet из библиотеки torchreid (Zhou & Xiang, 2019). OSNet — это модель, предварительно обученная на задачах повторной идентификации, и поэтому мы ожидаем, что она будет встраивать признаки, дискриминативные по отношению к внешнему виду людей. Действительно, мы также пробовали общие сети классификации изображений, включая вариации ResNet (He et al., 2016), но без такого успеха. Используемая предварительно обученная версия — модель ‘osnet ain x1.0 msmt17’, доступная через репозиторий torchreid (Zhou & Xiang, 2019).
- Затем мы используем реализацию алгоритма k-средних из scikit-learn (Pedregosa et al., 2011) для кластеризации этих встраиваний фрагментов изображений с использованием стандартных гиперпараметров (инициализация kmeans++; автоматическое определение количества запусков алгоритма с различными центроидами; допуск 0,0001; 300 максимальных итераций). Именно алгоритм k-средних принимает максимальное количество уникальных людей в качестве параметра для количества кластеров. После назначения мы проводим некоторые базовые проверки, чтобы убедиться, что назначение кластеров уникально для каждого кадра (т. е. два человека на одном кадре не могут быть назначены одной и той же идентичности, и если это происходит, присвоение идентичности/кластера помечается как ошибочное).
- Наконец, если требуются семантически значимые метки, исследователь также может предоставить сопоставление числовых меток кластеров (например, 0, 1) с метками, такими как «Терапевт» и «Пациент». Обратите внимание, что на протяжении всего этого процесса исследователи должны предоставить как минимум одну ключевую информацию — количество уникальных людей в видео — и, при желании, вторую, которая представляет собой сопоставление меток кластеров с семантически значимыми метками.
После выполнения повторной идентификации по описанному выше процессу исследователь может использовать извлеченные скелеты для ряда последующих задач. Мы приводим пример того, как их можно использовать для классификации поз (сидя или стоя), но на этом этапе существует широкий спектр возможностей. Самое главное, что фрагменты изображения, ограничивающие рамки и извлеченные признаки (такие как скелеты) могут быть последовательно назначены правильному человеку на протяжении всего видео, тем самым обеспечивая обработку, специфичную для каждого человека.
Результаты
Предыдущие подходы и их ограничения
В качестве эталона мы сначала использовали широко известный инструмент с открытым исходным кодом для отслеживания (StrongSORT (Du et al., 2023)). StrongSORT — это популярный метод многообъектного отслеживания, который включает как сходство внешнего вида, так и движение для отслеживания. Однако, несмотря на его общую эффективность при решении задач отслеживания, мы обнаружили, что этот вариант не предоставляет готовых средств для жесткого ограничения количества обнаруженных людей. Более проблематично для нашего сценария использования видео с людьми, которые входят и выходят из поля зрения камеры, StrongSORT чувствителен к длительным перекрытиям и, следовательно, испытывает трудности с повторной идентификацией человека, который выходит и снова входит в поле зрения камеры. StrongSORT обеспечивал успешную краткосрочную идентификацию (т. е. последовательное отслеживание в периоды без существенных перекрытий), но постоянно переоценивал количество идентичностей. После периодов длительных перекрытий StrongSORT присваивал совершенно новые идентичности ранее отслеживаемым людям, что приводило к переоценке количества уникальных людей в видео. Это явление обобщено в Таблице 1. В худшем случае обнаруживалось на 10 «лишних» человек больше, чем было на самом деле (N = 4). В лучшем случае было обнаружено на 4 «лишних» человека больше (N = 2).
Альтернатива, DeepLabCut (Lauer et al., 2022; Mathis et al., 2018), не была жизнеспособным вариантом, в основном потому, что она требует ручной аннотации примерно 50–200 кадров на видео и, таким образом, противоречит нашей цели автоматизации и масштабирования. Наконец, psifx (Rochette & Vowels, 2024), инструментарий для извлечения признаков с открытым исходным кодом, предназначенный для анализа поведения человека, не включает опции многопользовательского отслеживания или классификации поз.
Таблица 1 Столбец «Ground Truth (N)» указывает истинное количество людей в видео, тогда как столбец «StrongSORT Result» указывает, сколько уникальных людей было обнаружено StrongSORT (Du et al., 2023). При запуске подхода повторной идентификации StrongSORT наблюдается постоянное «переобнаружение» количества уникальных людей. В отличие от этого, наш метод не испытывает никаких трудностей, поскольку количество людей является единственным необходимым параметром, указанным заранее.
Точная повторная идентификация нескольких людей
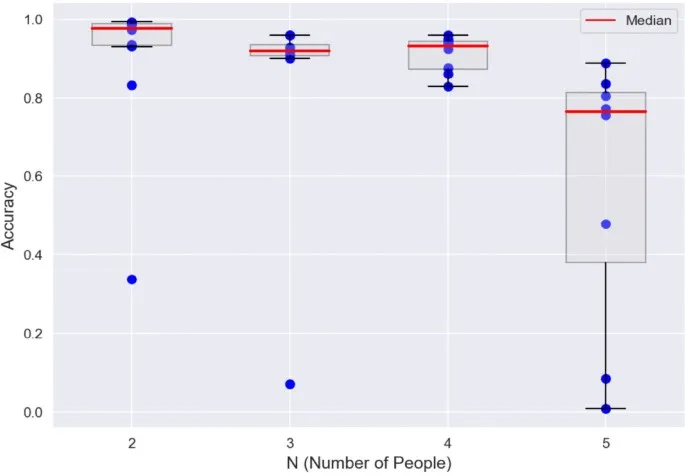
В целом, наш конвейер (схематично показанный на Рис. 2) оказался успешным в (повторной) идентификации, когда видео содержали от 2 до 5 человек, несмотря на то, что они были перекрыты, выходили и снова входили в кадр, и двигались мимо друг друга. Для получения результатов для подхода повторной идентификации мы применили наш конвейер ко всем кадрам этих видео и наложили результаты на исходные кадры, экспортировав видео. Затем мы равномерно случайно выбрали около 7000 кадров из этих видео и с помощью человека-аннотатора оценили правильность присвоенных идентификаций. На Рисунке 3 представлены результаты повторной идентификации. Сплошные красные линии указывают медианную точность идентификации человека (т. е. 97,6 % для 1750 кадров и N = 2, 91,9 % для 1207 кадров и N = 3, 93,1 % для 1540 кадров и N = 4, и 76,4 % для 1893 кадров и N = 5). Таблица 2 предоставляет дальнейшую разбивку этих результатов и выделяет общее количество кадров во всех видео, которые были оценены на предмет корректности (> 7000 кадров), а также среднюю точность для любого заданного количества уникальных людей. Отдельные значения, указанные на Рисунке 3 (синие точки), в основном тексте подчеркивают, что нисходящая предвзятость обусловлена некоторыми особо сложными видео. Мы выделяем успешный и неудачный случай на Рисунке 4, который включает матрицы ошибок для повторно идентифицируемых людей. В неудачном случае высокая схожесть между одеждой ребенка и одного из терапевтов привела к регулярной неправильной классификации.
Рис. 3 Точность повторной идентификации для каждого из 36 тестовых видео (синие точки) в зависимости от общего количества уникальных людей (N), содержащихся в каждом видео. Набор данных включает 12 видео с 2 людьми, 8 видео с 3 людьми, 8 видео с 4 людьми и 8 видео с 5 людьми. Диаграммы «ящик с усами» показывают медиану (красная линия), межквартильный диапазон (IQR, ящик) и наибольшие или наименьшие значения в пределах 1,5-кратного IQR (верхние и нижние усы соответственно).
Таблица 2 Результаты повторной идентификации в 36 видео с разным количеством уникальных людей.
Рис. 4 Успешный (слева) и неудачный (справа) случаи повторной идентификации, включая матрицы ошибок для каждого человека. Матрицы показывают количество раз, когда каждая предсказанная идентификация (ось X) сравнивается с истинной идентификацией (ось Y). Например, в успешном случае (слева) идентификация P3 была предсказана 74 раза, и во всех 74 случаях она была правильной. В отличие от этого, в неудачном случае (справа) было 66 случаев, когда метод предсказал идентификацию T2, когда истинной идентификацией была P1. Неудачи, как правило, возникают, когда два человека одеты в похожую одежду, что подчеркивает зависимость от внешнего вида для различения и повторной идентификации людей. Изображения были размыты и заблюрены для защиты личностей.
Точное отслеживание движений и оценка позы
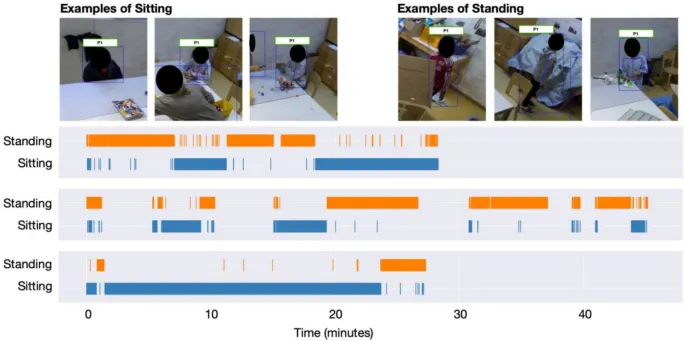
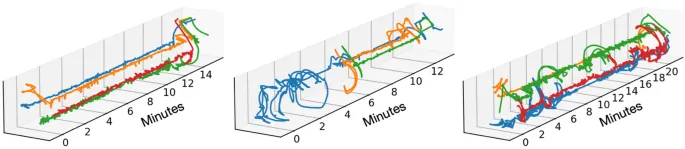
Позиция и поза также успешно отслеживались путем автоматической аннотации конфигурации скелета. С одной стороны, мы определяли, двигался ли (и где) каждый человек в пространстве, а с другой — классифицировали его позу как сидячую или стоячую. На Рисунке 5 приведен график положения xy пиксельных координат центра ограничивающей рамки обнаружения человека во времени для каждого человека из трех разных примеров сессий. Наряду с повторной идентификацией мы также оценили положения скелетов с использованием OpenPose 2.0 (Cao et al., 2018). Мы использовали эти скелеты для предсказания ряда поз, включая, было ли каждое лицо сидячим или стоячим. Для этого мы использовали набор вручную аннотированных меток «сидя» и «стоя», примененных к данным из 10 сессий. Истинные данные для этих меток были сгенерированы человеком-аннотатором с использованием Elan (Lausberg & Sloetjes, 2009). Мы извлекли примерно 237 000 кадров из этих видео и обучили классификатор XGBoost (Chen & Guestrin, 2016), используя процесс разбиения на группы k-fold, где мы обучали на всех кадрах и метках, за исключением данных из отложенного тестового видео. Использовались стандартные гиперпараметры (т. е. без настройки). В частности, мы обучались на скелетах из кадров, отобранных из 9 из 10 видео, и делали тестовые прогнозы на десятом видео. Затем мы повторили процесс, пока не получили результаты для всех возможных комбинаций обучающих/отложенных видео (т. е. процесс перекрестной проверки с групповым k-fold). По всему набору данных поза «сидя» предсказывалась с точностью (precision) = 0,78 ± 0,33, полнотой (recall) = 0,61 ± 0,32 и F1 = 0,63 ± 0,34 (среднее ± стандартное отклонение, рассчитанное по 10 видео с ручной аннотацией). Аналогично, поза «стоя» предсказывалась с точностью (precision) = 0,67 ± 0,25, полнотой (recall) = 0,85 ± 0,23 и F1 = 0,72 ± 0,23. Эти метрики взвешены по количеству кадров в каждом видео, а F1 — это гармоническое среднее точности и полноты. В общей сложности было 135 000 кадров для «сидя» и 102 000 кадров для «стоя». Рисунок 6 показывает примеры кадров, где люди либо сидят, либо стоят, подчеркивая сложность сцен. Рисунок также содержит три графика событий для позы трех примерных людей, выделяя периоды, когда они классифицируются как сидящие или стоячие с использованием наших методов. Эти классификации затем могут использоваться, например, для количественной оценки времени, проведенного стоя или сидя, или для фильтрации сессий по позе ребенка для целей последующего анализа.
Рис. 5 Показаны три примера групповых сессий xy пиксельных координат/траекторий людей, отслеживаемых в течение сессии. Каждый человек обозначен разным цветом. Они генерируются путем случайной выборки результатов из процесса повторной идентификации и ручной проверки личностей.
Рис. 6 Верхние левые три: примеры кадров, где человек сидит. Верхние правые три: примеры, где человек стоит. Эти кадры подчеркивают сложность сцен и возможность перекрытий, которые, тем не менее, преодолеваются нашим конвейером. Нижние три горизонтальных графика показывают примеры графиков событий, когда человек классифицируется как сидящий или стоящий в течение видео.
Точное отслеживание точек скелета
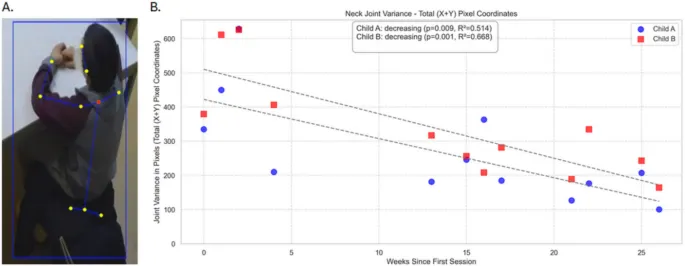
Скелеты также отслеживались как в пределах одного видео, так и между видео для одних и тех же двух человек в течение 26 недель. Это позволяет количественно характеризовать конкретные суставы/точки скелета в качестве индекса движения ребенка в различных временных масштабах и его изменчивости. На Рисунке 7 мы показываем изменчивость координат X и Y шейного сустава (красная точка на Рис. 7a) и анализ изменений этой изменчивости в последовательных сессиях видеозаписи. Мы демонстрируем, как отслеживание и оценка полной позы скелета по кадрам, реализованные в инструментарии ADVANCE, могут использоваться для оценки потенциально клинически значимых индексов из видео. Здесь OpenPose захватил 25 анатомических ключевых точек, включая голову, шею, плечи, туловище, бедра и конечности, для каждого кадра видео для двух примерных детей. На основе этих оценок мы применили вышеупомянутый классификатор «сидя/стоя» для сегментации записей и извлечения только кадров, когда ребенок сидел, тем самым гарантируя, что изменения позы не исказят наш анализ. Это также демонстрирует, как промежуточные категории поз могут быть использованы для выделения соответствующих сегментов поведения в более длинных записях. Для каждого кадра «сидя» мы измеряли координаты X и Y шейной точки и вычисляли их дисперсию за одну видеосессию, суммируя по обеим размерностям для получения общей меры дисперсии. Дисперсия шейного сустава отражает степень движения головы во время сидения, при этом более высокие значения указывают на более частые или большие движения, а более низкие значения — на большую неподвижность. Отображая эту дисперсию на протяжении нескольких видеосессий для каждого ребенка, мы оценили, как физическое движение во время сидячих задач менялось со временем. Оба ребенка в этом примере показали статистически значимое снижение дисперсии шейного сустава в течение 26 недель их сессий, что предполагает снижение движений во время сидения. Хотя это и является исследовательским, такой показатель может служить клинически значимым маркером моторной регуляции и, как следствие, вовлеченности и/или внимания ребенка, обеспечивая объективное дополнение к качественным клиническим наблюдениям.
Рис. 7 Панель A показывает один кадр с примерным ребенком и идентифицированные точки скелета. В этом анализе мы рассматривали шейную точку (красная точка). Обратите внимание, что лицо ребенка на рисунке заблюрено и размыто. Панель B показывает дисперсию шейного сустава, суммированную по координатам X и Y, для каждой записанной сессии двух детей; временной диапазон составлял 26 недель. В случае обоих детей наблюдалось значительное снижение этой дисперсии с течением времени (см. врезку).
Обсуждение
Инструментарий ADVANCE позволяет повторно идентифицировать и отслеживать позы людей в естественных условиях, преодолевая ограничения, связанные с альтернативными методами с открытым исходным кодом. ADVANCE хорошо работает, несмотря на загроможденные среды, множественное количество людей, перекрытия и изменчивость движений. Это достигается за счет комбинации YOLOv8 (Varghese & Sambath, 2024), MediaPipe (Lugaresi et al., 2019), OSNet (Zhou & Xiang, 2019) и k-средних кластеризации, при этом не требуется никакого ручного контроля. Оценка скелетов OpenPose (Cao et al., 2018) и классификатор XGBoost (Chen & Guestrin, 2016) успешно маркировали позы (сидя или стоя). Инструментарий ADVANCE работает в естественных условиях, не требуя от людей выполнения набора заранее определенных задач или нахождения в предписанных положениях, при этом они взаимодействуют и перемещаются в пространстве (здесь, в классе), которое не было предварительно сконфигурировано для ограничения или поощрения конкретных действий. Имея возможность правильно идентифицировать людей в такой обстановке, мы предвидим расширение этой работы путем анализа отслеживания движений в пределах пространства комнаты, количества и типов взаимодействий между людьми и объектами или людьми с другими людьми, а также времени, затраченного на конкретные задачи.
Помимо этологической достоверности, неограниченные сценарии снижают текущую нагрузку на клиническую инфраструктуру и персонал. Записи не требуют присутствия клиницистов или времени для оценки, освобождая их для проведения лечения и оказания медицинской помощи. Автоматизированная и количественная аннотация, кроме того, дает метрики, которые даже обученный человеческий глаз не может легко измерить (например, скорость движений, тип движения, время и траектория взаимодействий с объектами или людьми, или направление взгляда). Инкапсуляция этих методов в удобный для пользователя инструментарий является текущей задачей, направленной на обеспечение их широкой доступности. Не менее важным является тот факт, что такие данные, как видеозаписи детей или клинических популяций, не могут быть легко загружены на облачные серверы или публичные репозитории, что серьезно ограничивает набор аналитических инструментов, доступных исследователям и клиницистам, работающим с такими данными. Таким образом, инструментарий ADVANCE предоставляет конвейер, который может работать локально безопасным способом, соответствующим институциональным и нормативным требованиям. В более широком смысле, эти методы могут способствовать параллельным усилиям по оценке поз и видеоаннотации поведения как в лаборатории, так и в полевых условиях.
Несмотря на то, насколько важной является богатая поведенческая информация для понимания и улучшения понимания поведения человека и клинического лечения, Bulling et al. отмечают, что ручное кодирование наблюдений, как основной инструмент для получения такой информации, непомерно дорого по затратам времени и обучения (Bulling et al., 2023). Оно требует, чтобы аннотаторы сначала были обучены выявлять и записывать интересующее явление или явления предписанным и последовательным образом. Затем многие процессы аннотации требуют, чтобы аннотаторы просматривали и аннотировали итеративно, секунда за секундой или кадр за кадром, различные поведения по мере их разворачивания в записи. Кроме того, по своей сути сложно обеспечить последовательные и непредвзятые оценки между аннотаторами, что затрудняет гарантирование совместимости, эффективного сотрудничества и унификации наборов данных от различных исследовательских групп. Эти расходы сопутствующим образом негативно сказываются на размере выборки и статистической мощности, поскольку они требуют выделения средств, которые в противном случае могли бы быть использованы для привлечения дополнительных участников. Следовательно, ручное кодирование наблюдений плохо масштабируется для больших наборов данных. Эти соображения серьезно препятствуют прогрессу в исследованиях, включающих анализ видеозаписей, например, в контексте исследований психического здоровья или образовательных наук, тем самым также влияя на разработку эффективных вмешательств, обучение, а также распространение и обмен данными. Разрабатывая инструментарий ADVANCE, мы стремимся изменить этот статус-кво для более широкого научного и клинического сообщества.
Альтернативой, которую мы рассматривали, было модифицировать существующие алгоритмы для улучшения их производительности в сценариях, подобных представленным нами. Мы (без успеха) предприняли попытки настроить гиперпараметры этих алгоритмов для оптимизации их для длинных траекторий отслеживания, тем самым минимизируя вероятность того, что ранее идентифицированному человеку будет присвоена новая идентичность после перекрытия. Действительно, результаты для StrongSORT, представленные здесь (который также использует YOLOv8 в своей реализации для выполнения первоначального обнаружения людей), являются результатом попыток настройки алгоритма и представляют собой лучшее, чего мы смогли достичь с этим альтернативным методом. По нашему мнению, было более продуктивно получить относительно простое решение, специально разработанное для нашего случая использования и показавшее хорошие результаты, чем предпринимать значительные модификации существующих подходов, которые «из коробки» работали плохо. Мы полагаем, что наш алгоритм работает значительно лучше, чем эти альтернативы, по двум основным причинам. Во-первых, для нашего подхода нет требования реального времени. Таким образом, мы можем подавать кадры целых сессий в алгоритм кластеризации, тем самым предоставляя доступ к как можно большему количеству примеров репрезентативной информации об идентичности для данного видео перед назначением идентичностей этим кластерам. Во-вторых, мы смогли заранее указать общее количество уникальных идентичностей в ходе видео. В отличие от этого, StrongSORT (Du et al., 2023) не имеет такого предопределенного числа идентичностей, что является сильной стороной с одной стороны, но не может быть использовано для приложений, где общее количество уникальных идентичностей заранее фиксировано для каждого видео.
Существует несколько других популярных алгоритмов отслеживания, таких как ByteTrack (Zhang et al., 2022) и DeepSORT (Wojke et al., 2017). Однако мы отмечаем, что ByteTrack и DeepSORT имеют значительные ограничения в качестве сравнительных эталонных альтернатив. Во-первых, ByteTrack не обладает постоянством идентификации или возможностями повторной идентификации (т. е. если человек, который ранее отслеживался, перекрыт в течение длительного периода, ему будет очень маловероятно быть успешно переназначенным к той же траектории). Во-вторых, хотя DeepSORT был новаторским для своего времени, его производительность заметно ниже, чем у альтернатив. Следовательно, StrongSORT представляет собой ближайший текущий эквивалент нашего подхода с точки зрения как его актуальности, так и его реализации с YOLOv8.
Стоит рассмотреть, в какой степени инструментарий ADVANCE может быть применен к другим сценариям, где записывается поведение человека. Хотя здесь это эмпирически не тестировалось, сами методы «агностичны» по отношению к пространству. Фактически, мы намеренно выбрали стандартный класс художественных занятий, полагая, что такое пространство относительно загромождено объектами различных размеров, форм и цветов. Мы также намеренно позволили детям и терапевтам свободно перемещаться в пространстве, не прося их изменять естественное движение или поведение в соответствии с ограничениями записи. Таким образом, инструментарий ADVANCE должен легко работать в более стерильных условиях, таких как типичные клинические оценки/записи, и в более широком смысле в других неограниченных, естественных и загроможденных условиях. Однако будущие исследования потребуются для эмпирической проверки этого предположения.
Будущая работа также может использовать интеграцию многокамерных потоков для улучшения оценки поз и возможностей отслеживания (Lee et al., 2022). Многокамерные установки предлагают преимущество захвата людей с нескольких точек зрения, что может смягчить проблемы, связанные с перекрытием или ограниченными видами с одной камеры. Однако этот подход создает ряд трудностей, таких как необходимость синхронизации потоков данных между камерами, сложность слияния данных скелета из нескольких датчиков и вычислительные накладные расходы на обработку многовидовых данных. Помимо этих соображений, существуют также логистические и практические аспекты, такие как затраты на оснащение помещений таким образом, а также минимизация впечатления «наблюдения» у участников (особенно у педиатрических популяций). Тем не менее, такой подход может не только повысить надежность отслеживания, но и позволить анализировать более широкий спектр поведения и с более высоким разрешением, например, изучать направление взгляда в отношении конкретных объектов или людей (Erel et al., 2022, 2023), мелкую моторику рук или других конечностей, и другие тонкие жесты, которые трудно уловить человеку-аннотатору. Продолжающиеся инновации в этом отношении помогут использовать видеозаписи для оценки особенностей мультимодальной коммуникации, включая, но не ограничиваясь, жестами, мультисенсорными речевыми сигналами, показателями совместного внимания и т. д. В более общем плане, эти разработки обещают дальнейшее повышение этологической достоверности и полезности автоматизированных систем наблюдения за поведением. Учитывая повсеместное распространение видеозаписей для наблюдения за поведением и межличностными взаимодействиями, инструментарий ADVANCE готов катализировать аннотацию и преодолеть многие трудности ручной аннотации.