
Интересное сегодня


Введение в проблему моторного обучения
Несколько исследователей выдвинули гипотезу о том, что моторное обучение происходит офлайн — как во время сна, так и в ходе кратковременных периодов бодрствования. Напротив, было предположено, что моторное последовательное обучение происходит одновременно с выполнением задачи (то есть онлайн обучение). Различение между этими и связанными с ними гипотезами должно иметь фундаментальные последствия для свойств лежащей в основе нервной системы.
Предполагаемое моторное обучение во время периодов бодрствования, как полагают, involves facilitating microconsolidation (способствует микроконсолидации), в отличие от стабилизирующей консолидации (то есть защиты от забывания и интеграции памяти), которая, как считается, происходит при декларативном обучении. Вывод в пользу этой гипотезы основан на findings что: (1) часто наблюдается отрицательное или отсутствующее улучшение времени реакции при повторениях моторной последовательности within a performance trial, (2) производительность в начале trial часто лучше, чем в конце предыдущего trial, и (3) нейронные свидетельства hippocampal replay (повторного воспроизведения в гиппокампе) появляются во время периодов отдыха.
Вызов гипотезы микроконсолидации
Однако гипотеза микроконсолидации была оспорена. Были представлены доказательства диаметрально противоположной модели обучения, которая предполагает: (1) что все обучение происходит онлайн, одновременно с выполнением задачи, и (2) что reactive inhibition (RI) — реактивное торможение — накапливается в течение последовательностей within a trial и рассеивается с течением времени во время перерывов. Хотя механизм, лежащий в основе RI, плохо установлен, empirical effect (эмпирический эффект), который он описывает, был воспроизведен в исследованиях, охватывающих более 80 лет. Тем не менее, это явление не играло центральной роли в недавних исследованиях facilitating microconsolidation.
Методология исследования
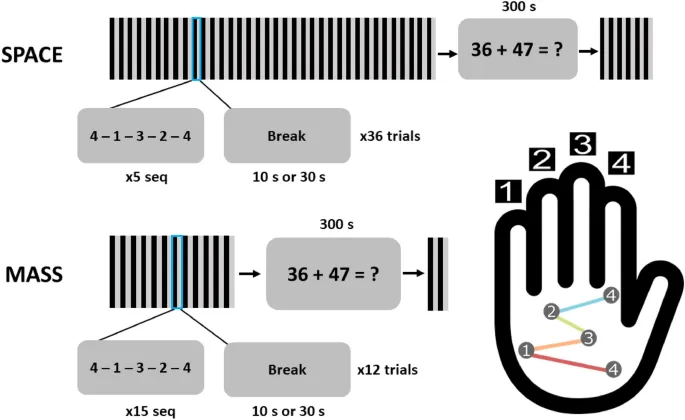
Исследование использовало стандартное задание на пальцевое tapping, где участники repeatedly typed a five-key sequence (повторяли набор пятиклавишной последовательности) своей недоминантной рукой. Было четыре группы, сочетающие 10 или 30 секунд на performance trial с 10 или 30-секундным перерывом между trials, при общем одинаковом времени выполнения задачи. После фазы обучения был 5-минутный период отдыха, за которым следовали дополнительные trials.
Результаты показали сильные свидетельства как накопления, так и рассеивания RI во всех группах во время обучения.
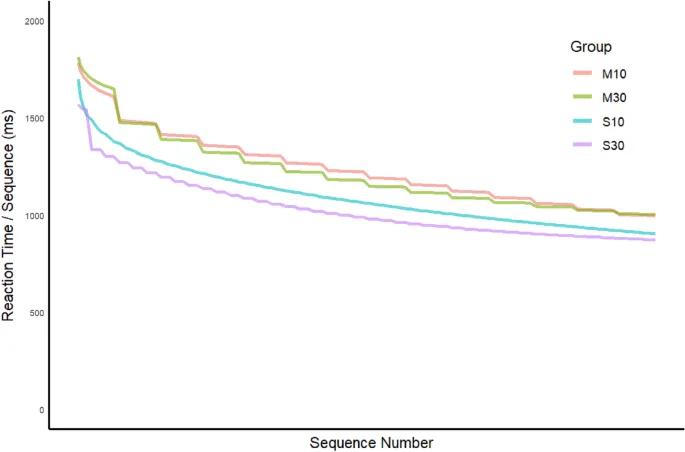
Наибольшее уменьшение времени реакции (RT gain) при правильном выполнении последовательности наблюдалось в группе с 30 секундами работы и 10-секундным перерывом, а наименьшее — в группе с 10 секундами работы и 30-секундным перерывом. Эти результаты согласуются с гипотезой о том, что RI существенно накапливается в ходе training trials в первой группе (поскольку 10-секундные перерывы были недостаточны для полного разрешения накопления RI during each 30-секундном trial), но largely resolved during breaks в последней группе.
Количественные модели обучения
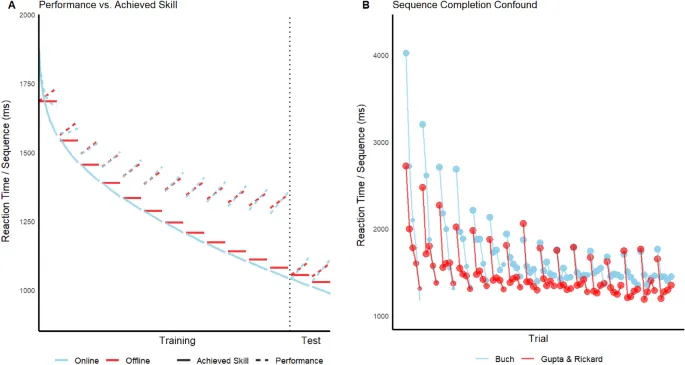
Мы разработали новую framework количественного моделирования, которая включает reactive inhibition и в которой могут быть реализованы три account обучения. Все модели, включающие RI, имеют identical quantitative implementation. Все модели feature a variant of a skill function для отображения обучения на время выполнения правильной последовательности (далее — время реакции, или RT).
Предыдущая работа по skill learning указывает, что для задач, которые не exhibit major strategy shifts with practice, выигрыш RT за trials является гладкой, отрицательно ускоряющейся функцией повторения. Мы приняли это assumption здесь. Поскольку exact mathematical function, управляющая acquired skill, неизвестна для моторного последовательного обучения, мы adopted a flexible function, которая сочетает power and exponential terms.
Типы моделей обучения
Онлайн модель навыков
Модель онлайн обучения предполагает, что обучение начинается immediately на первой последовательности trial и продолжается до завершения последней последовательности, так что during breaks обучения не происходит. В этой модели RT для underlying skill является solely a function of cumulative sequences за фазы обучения и тестирования (S).
Офлайн модель
Эта модель предполагает, что обучение происходит исключительно during breaks и что amount of learning эквивалентно во всех breaks equal duration. Предложенный account микроконсолидации согласуется с обоими assumptions, учитывая, что hippocampal replay occurs at the same rate across all breaks.
Гибридные модели
Третий класс моделей предполагает, что обучение может происходить как онлайн, так и офлайн. Это assumption правдоподобно, потому что multiple systems, вероятно, лежат в основе моторного последовательного обучения. Рассматриваются три варианта: HybridJ, HybridE и HybridP.
- HybridJ: Целью модели HybridJ является оценка relative proportion обучения, обусловленного офлайн и онлайн компонентами.
- HybridE: В модели HybridE экспоненциальное улучшение RT происходит офлайн, а степенное улучшение RT происходит онлайн.
- HybridP: Модель HybridP предполагает обратное.
Результаты исследования
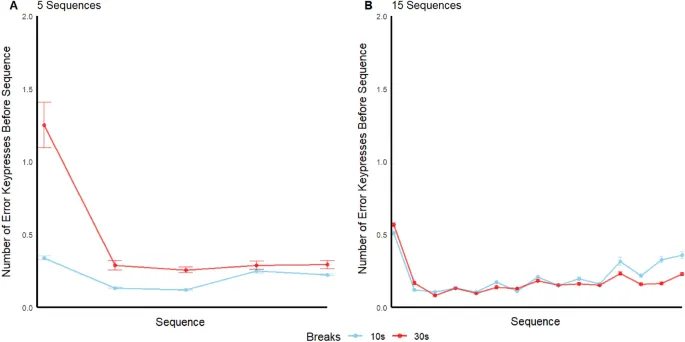
Средняя частота ошибок по последовательностям, trials и участникам в фазе обучения составила 0,17, 0,20, 0,39 и 0,20 нажатий неверных клавиш в группах M30, M10, S30 и S10 соответственно. Факторный дисперсионный анализ (ANOVA) на frequency ошибок не выявил влияния ни типа trial (massed vs. spaced), ни времени перерыва (10 с vs. 30 с), и не было взаимодействия.
Средние frequency ошибок across sequences withintrial, усредненные по training trials и participants, изображены на рисунке. Частота ошибок prior to the first sequence была относительно высокой для всех групп, что suggests a "warmup effect" на производительность в начале каждого trial.
Анализ времени реакции
Как показано в Приложении 1, первая последовательность каждого training and test trial имела RT, которые были значительно longer, чем для других последовательностей, mirroring the higher error rate prior to those sequences. Эти outlier sequences были удалены prior to model fitting.
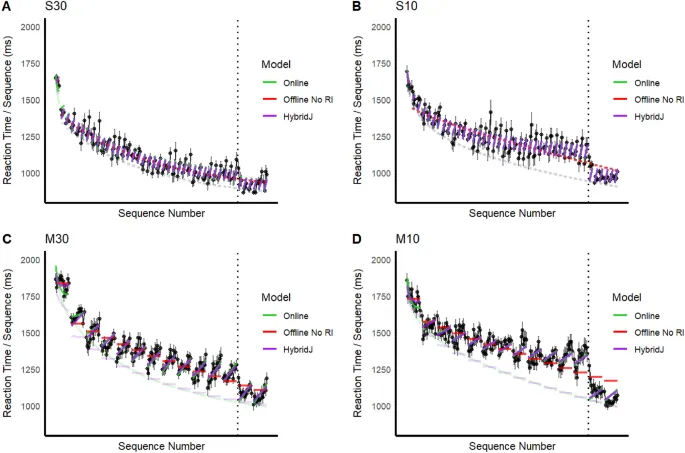
Средние sequence RTs по участникам показаны на рис. 3 для всех групп, вместе с fits онлайн модели, офлайн модели version 1, которая assumes no RI, и модели HybridJ. Версия 1 офлайн модели не способна capture ни pronounced RI effects (увеличение RT) over sequences withintrial, ни prominent residual RI effect across trials, особенно для massed groups.
Однако онлайн и HybridJ модели также смогли capture эти и другие major patterns в данных.
Обсуждение результатов
Мы исследовали три гипотезы обучения в ходе времени explicit motor sequence practice. Модели различаются относительно того, происходит ли обучение онлайн, офлайн или и то, и другое. Каждая модель включает flexible function для отображения обучения на RT, которая включает both exponential and power rate parameters. Каждая involves the same quantitative treatment как withintrial, так и residual RI (за исключением офлайн модели version 1), с assumed constant magnitude withintrial and residual RI effects across training and test phases.
Сравнение референсных офлайн моделей, которые учитывали и не учитывали RI, подтвердило, что inclusion including RI дает much better fits. По всем моделям, которые включали RI, quality fit по значениям BIC differed. Модель HybridJ подходила лучше всего, что suggests both online and offline learning occur.
Роль реактивного торможения
Хотя мы expected текущее finding, что residual RI over trials будет наибольшим в группе M10 и наименьшим в группе S30, мы были agnostic about the relative magnitude этого эффекта в группах M30 vs S10, потому что relative rate of RI accrual during performance vs. RI resolution during a break не был известен. Мы наблюдали greater residual RI buildup в группе M30, чем в группе S10, что указывает на то, что difference in accrual of RI для 15 vs. 5 sequences per trial превышает difference in the resolution of RI для 10-секундного vs. 30-секундного перерыва.
Ограничения исследования
Текущее исследование subject to нескольким limitations. Во-первых, оно не объясняет slower than expected RTs across the first several sequences на первом test trial. Мы assume, что это связано с extended "warmup" effect. Мы также не объясняем mechanistic basis pronounced first sequence "warmup" effect, который наблюдался на всех trials.
Наш подход к анализу, в котором those initial events of a trial игнорируются, не является уникальным в литературе, и он не appears to compromise our main conclusions. Во-вторых, наш вывод, что lower rate of RI buildup over sequences withintrial в massed groups может быть результатом speedaccuracy tradeoff, является спекулятивным.
Направления будущих исследований
Окончательное различение среди candidate models и оценка relative influence онлайн и офлайн обучения, likely require эксперименты, которые designed to specifically differentiate between parameter values, и переход к statespace modeling, вместе с datasets с decreased error variance.
Statespace modeling further elucidate how changes in learning and performance unfold over time. В текущем контексте есть по крайней мере три процесса, которые могут происходить исключительно с течением времени: dissipation of RI during breaks, saturation of offline learning during breaks, и saturation of online learning over time в отмеченной альтернативной online account, в котором обучение triggered immediately by performance но runs to completion during the break.
Заключение
Были tested три класса моделей, основанных на том, когда происходит моторное обучение: онлайн, офлайн и гибридные. Мы показали necessity включения RI как central component в любой такой модели. Результаты favor a hybrid model, в котором occur both online and offline learning. Описанная здесь framework количественного моделирования provides researchers с новым systematic and integrated approach для исследования mechanisms, лежащих в основе моторного последовательного обучения и производительности.





