Интересное сегодня
Прогнозирование риска депрессии у пожилых людей в сельском Китае с помощью машинного обучения
Депрессия — это серьезное расстройство настроения, которое значительно ухудшает физическое и психическое здоровье человека, повседневное функционирование и качество жизни, а также способствует повышенной смертности от физических заболеваний [1, 2]. Депрессивные симптомы, такие как подавленное настроение, бессонница и усталость, являются субклиническими проявлениями депрессии [3]. Пациенты с большим депрессивным расстройством подвержены пожизненному риску суицида [4].
Во всем мире депрессия стала серьезной проблемой общественного здравоохранения с растущей пожизненной распространенностью [5, 6]. По состоянию на 2017 год от нее страдали более 300 миллионов человек по всему миру [7], а Всемирная организация здравоохранения определила депрессию как ведущую причину нетрудоспособности [8]. Согласно исследованию «Глобальное бремя болезней» (Global Burden of Disease study), психические расстройства, включая депрессию, входят в число основных факторов, способствующих глобальному бремени болезней [9]. В Китае депрессия также является ведущей причиной самоубийств [10] и зависит от различных факторов, таких как демографические характеристики, состояние здоровья, образ жизни, семейная среда и социальное обеспечение [11,12,13,14].
Особые проблемы сельских районов Китая
Примечательно, что выраженный разрыв между городскими и сельскими районами Китая способствует существенным различиям в социально-экономических условиях, государственных услугах и доступе к здравоохранению [15,16,17]. Эти структурные дисбалансы связаны со значительно более высокой распространенностью депрессии среди людей среднего и пожилого возраста в сельских районах по сравнению с их городскими сверстниками [18, 19]. Помимо экономических неравенств и неравенства в доступе к здравоохранению, сельское население сталкивается с дополнительными структурными и контекстуальными проблемами [20,21,22]. Социальные барьеры, включая ограниченную осведомленность о психическом здоровье, стигматизацию и недостаточный доступ к профессиональной помощи, еще больше препятствуют раннему выявлению и лечению депрессивных симптомов. В то же время демографические сдвиги, такие как старение населения и снижение рождаемости, уменьшили устойчивость сельских сообществ. Кроме того, крупномасштабная миграция из сельских районов в города привела к фрагментации традиционных семейных структур, в то время как быстрая урбанизация продолжает концентрировать ресурсы и услуги в городах. Эти пересекающиеся факторы коллективно подрывают сети социальной поддержки и увеличивают психологическую уязвимость сельских пожилых людей.
Общенациональное кросс-секционное исследование, проведенное в 2018 году, показало, что распространенность депрессивных симптомов среди сельского пожилого населения Китая в возрасте 45 лет и старше составляла 34,8%, что значительно выше, чем 22,3% среди их городских сверстников [23].
Необходимость новых инструментов прогнозирования
Следовательно, раннее выявление и вмешательство при депрессивных симптомах в экономически слаборазвитых сельских районах Китая имеют важное значение для предотвращения их прогрессирования в клиническую депрессию и снижения общего бремени болезней. Однако в настоящее время существует нехватка эффективных инструментов для скрининга лиц, подверженных риску развития депрессивных симптомов в будущем. Разработка простого, быстрого и доступного метода оценки риска для выявления лиц из группы высокого риска, таким образом, имеет решающее значение для продвижения усилий по профилактике и управлению депрессией в сельских китайских общинах.
Применение машинного обучения в здравоохранении
В последние годы стремительный прогресс технологий искусственного интеллекта (ИИ) подчеркнул растущую ценность машинного обучения (ML) в здравоохранении [24,25,26,27]. Модели машинного обучения, особенно Random Forest (RF — Случайный лес), хорошо подходят для обработки сложных нелинейных взаимосвязей, высокоразмерных и несбалансированных данных, а также пропущенных значений, одновременно автоматически ранжируя важность переменных [28, 29]. Более того, они эффективны, масштабируемы и недороги, что делает скрининг на основе RF особенно привлекательным в условиях ограниченных ресурсов сельских районов, где обычная психиатрическая оценка часто непрактична.
Традиционная диагностика депрессии обычно основывается на индивидуальных клинических интервью, проводимых обученными специалистами, иногда дополненных стандартизированными шкалами оценки или лабораторными тестами [30, 31]. Однако эти процедуры требуют профессиональной экспертизы и диагностической инфраструктуры, которых часто не хватает в сельских регионах. Кроме того, такие оценки обычно являются ретроспективными или кросс-секционными, выявляя лиц, уже имеющих депрессивные симптомы. Они не предназначены для прогнозирования будущих рисков, что ограничивает их полезность для проактивного вмешательства и профилактики в уязвимых группах населения.
На международном уровне многие исследования по прогнозированию депрессии опираются на электронные медицинские карты или интервью с врачами [32,33,34]; хотя такие входные данные эффективны, они дороги и их трудно получить за пределами систем с достаточными ресурсами. В отличие от этого, наш подход использует структурированные, легко собираемые данные анкет, предлагая практичную и адаптируемую к сообществу альтернативу для выявления сельских пожилых людей, подверженных риску будущих депрессивных симптомов.
Материалы и методы
Источник данных
China Health and Retirement Longitudinal Study (CHARLS) — комплексный междисциплинарный проект обследования, проводимый Национальной школой развития Пекинского университета. Обследование охватывает 150 уездов и 450 общин (деревень) в 28 провинциях, собирая продольные данные от национально представительной выборки лиц в возрасте старше 45 лет посредством личных интервью. Эти данные охватывают различные аспекты, включая социально-экономический статус и состояние здоровья, обеспечивая прочную основу для исследований в области геронтологии. Данное исследование проводилось на основе данных, извлеченных из общедоступной базы данных CHARLS, и все методы выполнялись в соответствии с соответствующими руководящими принципами и правилами. Письменное информированное согласие было получено от всех участников или их законных представителей до начала любого исследовательского процесса. Этическое одобрение на сбор данных CHARLS было получено Комитетом по биомедицинскому этическому обзору Пекинского университета (IRB0000105211015). Подробные описания, включая процедуры отбора проб, анкету и необработанные данные, доступны на https://charls.pku.edu.cn и в дополнительных материалах (S1 и S2).
Исследуемая популяция
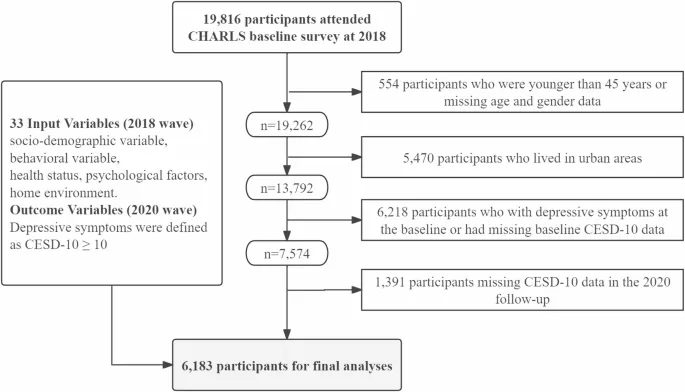
В данном исследовании использовались данные CHARLS, собранные в период с 2018 по 2020 год. Участники были исключены по следующим критериям: (1) 554 участника моложе 45 лет или с отсутствующими данными о возрасте и поле; (2) 5 470 участников, проживавших в городских районах; (3) 6 218 участников с депрессивными симптомами на исходном уровне или отсутствующими данными CESD10 на исходном уровне; (4) 1 391 участник с отсутствующими данными CESD10 при последующем наблюдении в 2020 году. После применения этих критериев в окончательный анализ было включено всего 6 183 сельских жителя среднего и пожилого возраста. Подробный процесс отбора участников проиллюстрирован на Рис. 1.

Исследовательские переменные
Результативная переменная
Диагноз депрессивных симптомов определялся с использованием шкалы CES-D10 (Center for Epidemiologic Studies Depression Scale 10-item version) [36] в CHARLS 2020, которая известна своей высокой надежностью и валидностью, особенно при оценке симптомов депрессии у пожилых людей [37,38,39]. Шкала состоит из 10 пунктов и использует 4-балльную систему оценки по Ликерту. Возможные суммарные баллы варьируются от 0 до 30, причем более высокие баллы отражают большую выраженность депрессивных симптомов, а пороговое значение 10 указывает на положительный результат скрининга на депрессию [40].
Кандидатные предикторы
Опираясь на предыдущую литературу, структуру доступного набора данных и специфический социокультурный и медицинский контекст сельского Китая, в качестве кандидатных предикторов было выбрано в общей сложности 33 базовых переменные из волны опроса CHARLS 2018 года. Эти переменные были выбраны из-за их простоты, возможности сбора в условиях ограниченных ресурсов и теоретической релевантности к депрессивным симптомам. Переменные были сгруппированы в пять концептуальных доменов: социодемографические, поведенческие, состояние здоровья, психологические факторы и домашняя среда. Всем переменным были присвоены описания, как подробно указано в Дополнительной таблице S1.
- Социодемографические переменные: возраст, пол, уровень образования, семейное положение, статус занятости. Образование было категоризировано на четыре уровня: ниже начальной школы, начальная школа, неполная средняя школа, полная средняя школа и выше. Семейное положение было сгруппировано как «состоящие в браке/партнерстве» и «разведенные/вдовы/никогда не состоявшие в браке/другие». Статус занятости различал «работающие в настоящее время» и «пенсионеры».
- Поведенческие переменные: текущий статус курения, привычки к употреблению алкоголя, привычки к физическим упражнениям (физическая активность), продолжительность сна и количество социальных мероприятий. Физическая активность (привычки к упражнениям) была самоотчетной. Продолжительность сна — среднее количество часов сна за ночь. Социальная активность основывалась на количестве различных видов деятельности.
- Переменные состояния здоровья: самоотчетная инвалидность, слух, проблемы с памятью, боль, количество хронических заболеваний, опыт падений, функциональные ограничения и использование вспомогательных устройств. Инвалидность, боль, опыт падений и использование вспомогательных устройств регистрировались как бинарные переменные (да/нет). Слух и память основывались на самооценке. Количество хронических заболеваний определялось на основе самоотчетов о диагнозах, поставленных врачом. Функциональные ограничения измерялись с помощью вопросников по повседневной деятельности (Activities of Daily Living — ADL) и инструментальной повседневной деятельности (Instrumental Activities of Daily Living — IADL).
- Психологические переменные: удовлетворенность жизнью и самооценка здоровья, категоризированные как «хорошо», «удовлетворительно» и «плохо».
- Переменные домашней среды: оценивали физическую инфраструктуру и условия проживания. К ним относились: использование жилья для бизнеса; тип конструкции здания; год постройки дома; доступ к проточной воде; доступ к угольному газу или природному газу; наличие телефонной связи и доступа в Интернет; наличие очистителя воздуха; а также показатели опрятности дома и условий температуры.
Модель Случайного леса (Random Forest)
Для решения проблемы несбалансированности классов в наборе данных, где только 26,3% участников имели депрессивные симптомы через три года, применялся метод Adaptive Synthetic Sampling (ADASYN) для генерации дополнительных синтетических выборок депрессивных симптомов [41, 42]. Этот метод генерирует синтетические экземпляры для миноритарного класса, фокусируясь на образцах, которые труднее классифицировать, тем самым улучшая баланс классов и устойчивость модели (см. Приложение S5 Методы для получения подробной информации). Набор данных был случайным образом разделен на обучающий набор (70%) и тестовый набор (30%). ADASYN-оверсемплинг применялся только к обучающему набору, чтобы избежать утечки информации, в то время как тестовый набор сохранил свое исходное распределение классов, чтобы обеспечить беспристрастную оценку обобщаемости модели.
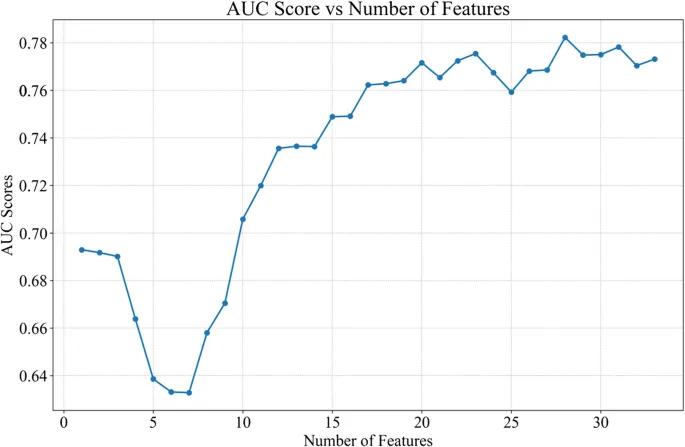
Для выявления наиболее информативных предикторов применялось рекурсивное исключение признаков (Recursive Feature Elimination — RFE) с использованием алгоритма Random Forest (RFRFE) [43], который ранжирует переменные на основе их оценок важности и итеративно удаляет наименее информативные для получения оптимального подмножества. По сравнению с методами на основе регуляризации, такими как LASSO, RFRFE более совместим с древовидными алгоритмами, такими как Random Forest, что делает его более подходящим подходом к отбору признаков для данного исследования [44, 45].
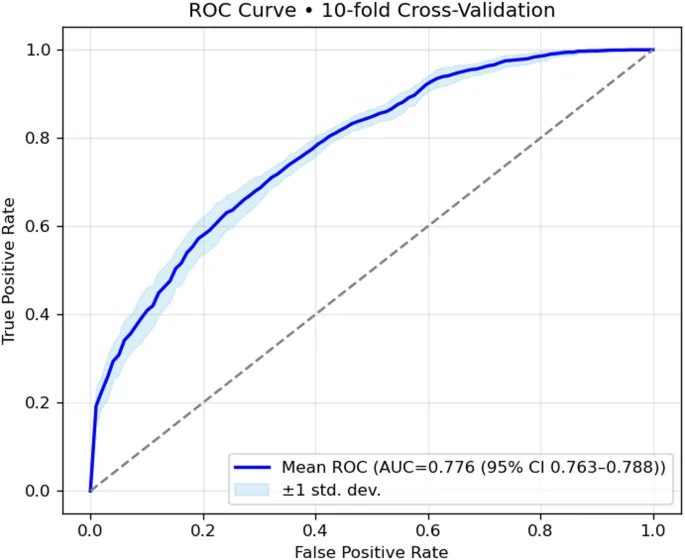
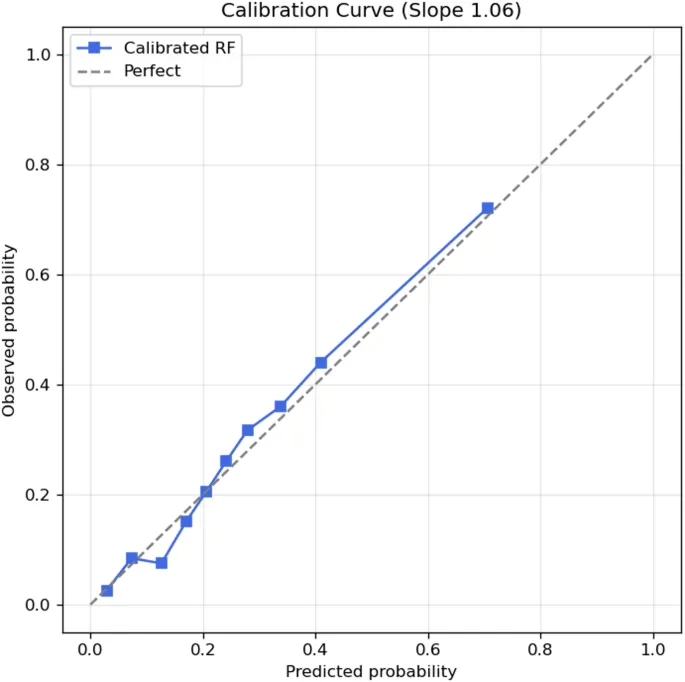
Выбранные признаки использовались для всех последующих разработок моделей, настройки гиперпараметров и валидации. Настройка гиперпараметров для классификатора Random Forest проводилась с помощью поиска по сетке (grid search) в рамках вложенной перекрестной валидации (nested crossvalidation), где поиск по сетке выполнялся во внутреннем цикле, а производительность модели оценивалась во внешнем цикле с использованием 10-кратной стратифицированной перекрестной валидации на всем наборе данных. Площадь под характеристической рабочей кривой (Area Under the Receiver Operating Characteristic Curve — AUC) использовалась в качестве основного критерия оптимизации [46]. Метрики производительности с коррекцией на оптимизм, включая точность (accuracy), прецизионность (precision), полноту (recall), F1-меру (F1-score), AUC, оценку Брайера (Brier score) и наклон калибровки (calibration slope), сообщались как среднее ± стандартное отклонение по внешним фолдам и сравнивались при нескольких репрезентативных пороговых значениях принятия решений. Оптимальный порог для классификации определялся путем максимизации F1-меры в рамках перекрестной валидации. Полнота использовалась в качестве вторичной метрики для приоритизации выявления сельских жителей среднего и пожилого возраста из группы высокого риска, учитывая важность минимизации пропущенных случаев при скрининге депрессии для этой популяции. Кривые ROC и калибровочные графики использовались для оценки дискриминации и калибровки модели соответственно. Дополнительно, для облегчения клинической интерпретации, положительная прогностическая ценность (Positive Predictive Value — PPV) и отрицательная прогностическая ценность (Negative Predictive Value — NPV) оценивались при каждом пороге при различных сценариях распространенности.
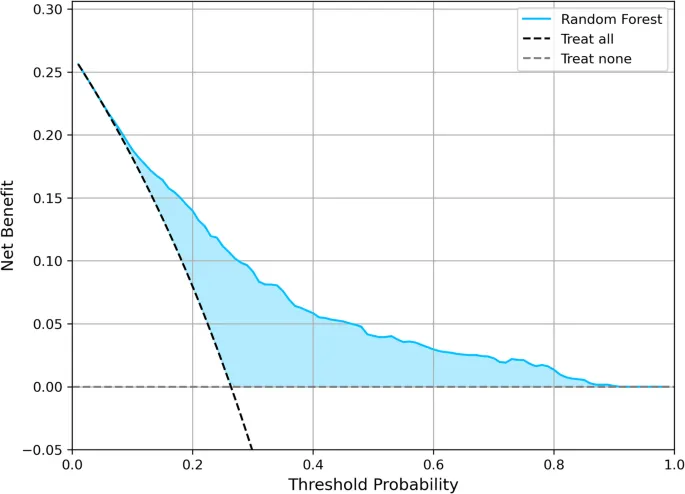
Для оценки клинической полезности предиктивной модели и учета потенциального вреда от ложноположительных и ложноотрицательных результатов был проведен анализ кривой принятия решений (Decision Curve Analysis — DCA) [47]. Этот метод оценивает чистую выгоду в диапазоне пороговых вероятностей, позволяя сравнивать с использованием стратегий по умолчанию, таких как «лечить всех» (treat all) или «не лечить никого» (treat none). Наконец, для повышения интерпретируемости прогнозов модели были рассчитаны значения SHapley Additive exPlanations (SHAP) на основе обучающего набора [48, 49]. Основанные на теории кооперативных игр, значения SHAP количественно определяют вклад каждого признака в прогноз, предлагая детальное понимание того, как отдельные предикторы влияют на риск депрессивных симптомов у сельских жителей среднего и пожилого возраста.
Статистический анализ
Для обработки и анализа данных использовались SPSS 26.0 и Python 3.9. Пропущенные значения в предикторах были импутированы с помощью MissForest [50], метода на основе случайного леса, подходящего для данных смешанного типа и способного улавливать нелинейные взаимосвязи. Чтобы избежать потенциальной утечки данных, импутация выполнялась строго в пределах каждого обучающего фолда во время перекрестной валидации, гарантируя, что информация из валидационного фолда не использовалась во время обучения модели или предварительной обработки. Этот подход улучшает надежность по сравнению с импутацией средним или модальным значением. Подробности о пропущенных данных приведены в Дополнительной таблице 1.
Тесты Хи-квадрат (Chi-square tests) использовались в качестве унивариантного анализа для сравнения частотных распределений категориальных переменных между участниками с и без развития депрессивных симптомов. Переменные со значением p < 0,05 считались статистически значимыми.
Результаты
Характеристики участников
В общей сложности 6 183 сельских жителя среднего и пожилого возраста были включены в окончательный анализ. Как показано в Таблице 1, медианный возраст участников составил 60 лет (межквартильный диапазон [IQR]: 52-68), 48,9% были женщинами, а 73,7% были женаты/имели партнера. Средний уровень образования составлял 4,9 ± 3,1 года. Подавляющее большинство (88,2%) имели доступ к проточной воде, а 62,4% имели доступ к угольному или природному газу. Почти половина (49,5%) сообщили о наличии хронических заболеваний, а 37,9% имели функциональные ограничения.
За трехлетний период наблюдения у 1 629 (26,35%) участников развились депрессивные симптомы. Унивариантный анализ выявил значительные различия между группами с депрессивными симптомами и без них по многим переменным, включая возраст, пол, уровень образования, семейное положение, статус занятости, курение, употребление алкоголя, физическую активность, продолжительность сна, количество социальных мероприятий, самооценку инвалидности, слуха, памяти, боли, количество хронических заболеваний, опыт падений, функциональные ограничения, использование вспомогательных устройств, самооценку здоровья, удовлетворенность жизнью, доступ к проточной воде, угольному/природному газу, телефону и Интернету.

Результаты моделирования
В таблице 2 представлены результаты многофакторной логистической регрессии для прогнозирования развития депрессивных симптомов. Модель с учетом всех переменных показала, что пол (женский), возраст, наличие боли, неудовлетворенность жизнью, проблемы с памятью, функциональные ограничения (ADL/IADL), опыт падений, плохое самочувствие и плохой слух были связаны с повышенным риском депрессивных симптомов. Напротив, мужской пол, более высокий уровень образования, достаточная продолжительность сна (6-8 часов или >8 часов по сравнению с <6 часов), доступ в Интернет и наличие угольного/природного газа были связаны с пониженным риском.
Ключевые предикторы:
- Повышенный риск: Женский пол, старший возраст, наличие боли, низкая удовлетворенность жизнью, проблемы с памятью, функциональные ограничения (ADL/IADL), опыт падений, плохое самочувствие, плохой слух.
- Сниженный риск: Мужской пол, высокий уровень образования, достаточная продолжительность сна, доступ в Интернет, наличие угольного/природного газа.
Модель Random Forest (RF) продемонстрировала более высокую эффективность в прогнозировании, чем логистическая регрессия, особенно после применения ADASYN для устранения дисбаланса классов. После настройки гиперпараметров и выбора признаков с помощью RFE, модель RF показала следующие результаты на тестовом наборе (Таблица 3):
- Точность (Accuracy): 0.736
- Прецизионность (Precision): 0.499
- Полнота (Recall): 0.607
- F1-мера: 0.548
- AUC (площадь под ROC-кривой): 0.776 (95% доверительный интервал [CI]: 0.763–0.788)
- Оценка Брайера: 0.163 ± 0.006
Эти показатели свидетельствуют о хорошей общей калибровке и дискриминационной способности модели RF для выявления лиц, подверженных риску развития депрессивных симптомов.

Возрастная стратификация
Анализ, стратифицированный по возрасту, выявил различия в факторах риска между группами среднего (45-59 лет) и пожилого (≥60 лет) возраста (Таблицы 4 и 5).
Для лиц среднего возраста (45-59 лет):
- Повышенный риск: плохое самочувствие, проблемы с памятью, функциональные ограничения (ADL/IADL), плохой слух, хронические заболевания, опыт падений, боль.
- Сниженный риск: достаточная продолжительность сна, наличие угольного/природного газа, использование Интернета.
Для пожилых людей (≥60 лет):
- Повышенный риск: неудовлетворенность жизнью, плохой слух, функциональные ограничения (ADL/IADL), боль, опыт падений, плохое самочувствие, проблемы с памятью.
- Сниженный риск: мужской пол, наличие угольного/природного газа, достаточная продолжительность сна.
Примечательно, что плохой слух и функциональные ограничения были сильными предикторами риска депрессии в обеих возрастных группах. Однако неудовлетворенность жизнью была более выраженным фактором риска среди пожилых людей, тогда как проблемы с памятью и хронические заболевания оказали большее влияние на группу среднего возраста.

Анализ прогностической ценности
Анализ положительной прогностической ценности (PPV) и отрицательной прогностической ценности (NPV) при различных порогах классификации и уровнях распространенности (Таблица 6) показал, что при исходной распространенности депрессивных симптомов в 26,3% оптимальный порог (0.43) обеспечивал PPV 0,499 и NPV 0,844. При увеличении порога до 0.50 PPV увеличивался до 0.598, но NPV снижался до 0.810. При дальнейшем увеличении порога до 0.60 PPV достигал 0.728, но NPV снижался до 0.773.
При увеличении распространенности до 30%, PPV улучшался при всех порогах (0.610, 0.544 и 0.447 соответственно), в то время как NPV снижался, но оставался высоким (>0,78). Эта тенденция подчеркивает важность учета местной распространенности заболевания при интерпретации положительных и отрицательных прогнозов в условиях первичной медико-санитарной помощи в сельских районах.


Анализ кривой принятия решений (Decision Curve Analysis)
Результаты анализа кривой принятия решений (Decision Curve Analysis — DCA) для модели RF (Рис. 6) продемонстрировали явную чистую клиническую выгоду. Модель превосходила как стратегии «лечить всех», так и «не лечить никого» при пороговых вероятностях от примерно 0,05 до 0,30, достигая пиковой чистой выгоды около 0,26. Модель продолжала давать положительную чистую выгоду (превосходя стратегию «не лечить никого») до порога примерно 0,80, что подтверждает ее полезность для информирования о профилактических вмешательствах в широком диапазоне клинически приемлемых уровней риска.
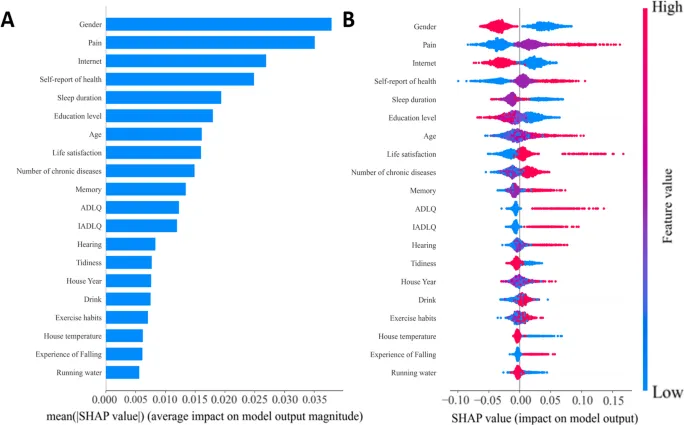
Объяснение важности признаков (SHAP analysis)
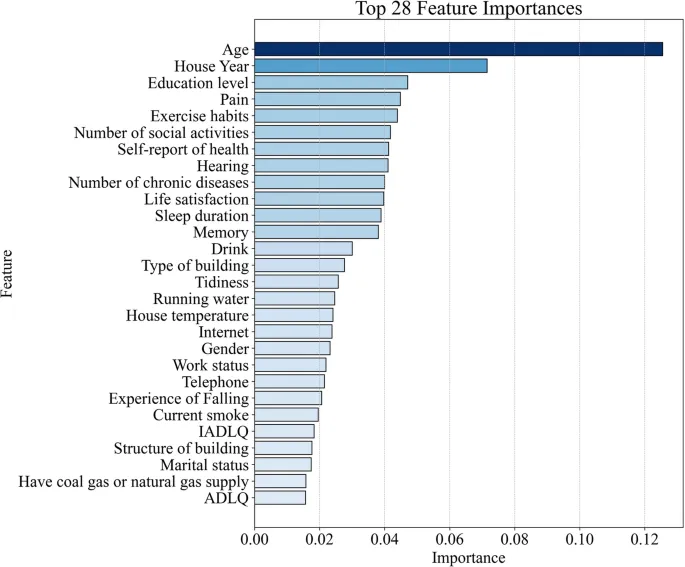
Для понимания вклада отдельных признаков в прогнозирование депрессивных симптомов был проведен SHAP-анализ модели Random Forest, с рассмотрением 20 наиболее влиятельных предикторов.
Глобальная важность этих признаков, определяемая их средними абсолютными значениями SHAP, представлена на Рис. 7A. Этот анализ показал, что «пол», «боль», «Интернет», «самооценка здоровья» и «продолжительность сна» были пятью основными факторами, способствующими прогностической эффективности модели, указывая на их существенное общее влияние на различение между лицами с депрессивными симптомами и без них.
Дополнительное понимание направления и величины этих влияний на уровне индивидуального прогноза предоставляется сводным графиком SHAP (Рис. 7B). Быть женщиной и испытывать «плохую» боль были последовательно связаны с увеличением значений SHAP, способствуя более высокому прогнозируемому риску депрессии. И наоборот, больший доступ к «Интернету», более благоприятный статус «самооценки здоровья», более длительная «продолжительность сна» и более высокий «уровень образования» обычно соответствовали снижению значений SHAP, тем самым снижая прогнозируемый риск депрессии. Более «старший» возраст также последовательно положительно влиял на значения SHAP, указывая на его связь с повышенным прогнозируемым риском. Распределения также подчеркивают, что для таких признаков, как «удовлетворенность жизнью» и «количество хронических заболеваний», существует четкое разделение, где более низкая удовлетворенность и большее количество заболеваний подталкивают значения SHAP к прогнозированию более высокого риска депрессии.
Эти SHAP-выводы в совокупности определяют ключевые движущие силы прогнозирования депрессии в модели, количественно определяя как общую важность каждого признака, так и конкретное влияние его различных уровней на оценку индивидуального риска.

Обсуждение
В данном исследовании изучался потенциал алгоритма Random Forest для разработки 3-летней прогностической модели инцидентных депрессивных симптомов среди людей среднего и пожилого возраста в сельском Китае. Из когорты 6 183 сельских участников, опрошенных в период с 2018 по 2020 год, у 1 629 (26,35%) развились депрессивные симптомы в течение 3-летнего периода наблюдения. После корректировки порогового значения принятия решений для оптимизации F1-меры (оптимальный порог = 0,43) наша прогностическая модель достигла точности 0,736, прецизионности 0,499, полноты 0,607, F1-меры 0,548 и AUC 0,776 (95% CI: 0,763–0,788). Средняя оценка Брайера составила 0,163 ± 0,006, что указывает на хорошую общую калибровку. DCA далее продемонстрировал явную чистую клиническую выгоду в соответствующем диапазоне пороговых вероятностей, поддерживая полезность модели для выявления лиц с повышенным риском.
Ключевыми предикторами, связанными с более низким риском развития депрессивных симптомов, были: мужской пол, более высокий уровень образования, оптимальная продолжительность сна (6–8 часов или >8 часов по сравнению с <6 часов), доступ в Интернет и наличие угольного/природного газа. Напротив, старший возраст, плохое самочувствие, более низкая удовлетворенность жизнью, нарушение памяти, функциональные ограничения (ADL/IADL), боль, история падений и плохой слух были значимыми факторами риска инцидентных депрессивных симптомов в этой сельской китайской популяции.
Сравнение с предыдущими исследованиями
До этого исследования многочисленные исследователи использовали машинное обучение для прогнозирования риска депрессивных симптомов в специфических популяциях. Например, Вэй [53] прогнозировал риск депрессии у китайских пациентов с эпилепсией с помощью ML, достигнув AUC 0,86. Чжан [54] прогнозировал депрессию у беременных женщин с AUC 0,88, в то время как Али [55] прогнозировал депрессию у женщин в период менопаузы с точностью 97,11%. Стефания [56] прогнозировала депрессивные симптомы у пожилых людей с точностью и прецизионностью 87%. Эти исследования часто использовали широкий спектр комплексных предиктивных индикаторов, включая подробные социодемографические переменные, обширные истории психологического здоровья, специфические медицинские коморбидности, назначения лекарств и детализированные клинические характеристики, что, вероятно, способствовало их высоким показателям прогностической точности (например, AUC обычно превышают 0,85).
Однако прямое сравнение этих моделей с нашей моделью (AUC = 0,779) требует тщательного рассмотрения нескольких основополагающих факторов. По-видимому, более высокая производительность в некоторых из этих исследований, таких как Вэй и др. [53], может быть в первую очередь связана с ключевыми различиями в их целевых популяциях (например, специфические группы пациентов, такие как страдающие эпилепсией, которые могут иметь более однородный профиль риска или отличительные предикторы) и самой природой используемых признаков. Исследования, посвященные клиническим когортам, например, часто имеют доступ к более подробным медицинским записям и биомаркерам, которые недоступны в широких общественных условиях, особенно в сельских районах с ограниченными ресурсами.
В отличие от этого, наше исследование сознательно шло на компромисс между максимизацией прогностической точности и обеспечением практической применимости и интерпретируемости в условиях сельских районов Китая, характеризующихся ограниченным экономическим развитием и дефицитом медицинских ресурсов. Наша модель целенаправленно выбрала 28 предиктивных индикаторов, которые легко получить с помощью личных интервью и проверенных шкал, тем самым минимизируя нагрузку как на системы здравоохранения, так и на участников. Этот подход соответствует другим исследованиям машинного обучения, которые разрабатывали предиктивные модели для исходов в области здравоохранения на основе в основном данных анкет или аналогично доступных признаков, которые показали AUC в целом в диапазоне от примерно 0,72 до 0,84 [27, 57,58,59]. Хотя этот акцент на легкодоступных данных может способствовать несколько более скромному AUC по сравнению с исследованиями с более обширными и сложными наборами признаков, он подчеркивает жизненно важную полезность модели для раннего скрининга и вмешательства в недостаточно обслуживаемые группы населения. Кроме того, различия в размере выборки, распространенности депрессивных симптомов и конкретных определениях исходов в различных когортах исследований также могут влиять на сообщаемую производительность модели.
Торговля между прецизионностью и полнотой:
Примечательно, что наши результаты показывают, что снижение порога классификации для максимизации полноты существенно увеличивает количество ложноположительных результатов, что отражается в снижении прецизионности и PPV при различных порогах. В условиях первичной медико-санитарной помощи в сельских районах этот компромисс может быть приемлемым, поскольку максимизация выявления случаев часто является приоритетом, чтобы избежать пропущенных лиц из группы высокого риска, особенно при наличии ресурсов для последующей оценки. Однако возросшая нагрузка от ложноположительных результатов должна быть тщательно сбалансирована с местными возможностями здравоохранения и потенциальными последствиями как ложноположительных, так и ложноотрицательных результатов.
Последствия для профилактических мер
Хотя инициативы общественного здравоохранения поддерживают сельских пожилых людей в Китае, сохраняющиеся депрессивные симптомы свидетельствуют о том, что текущие меры могут не в полной мере учитывать специфические местные факторы риска. Наш анализ логистической регрессии (Таблица 2) выявил несколько ключевых модифицируемых факторов риска инцидентных депрессивных симптомов в этой сельской популяции, подчеркивая эти пробелы и направляя нашу предложенную стратегию вмешательства, основанную на данных, поэтапную, для усиления текущих усилий.
Например, наши результаты совпадают с более широкими эпидемиологическими данными, указывающими на более высокую распространенность депрессии у женщин по сравнению с мужчинами [60], потенциально связанную с психосоциальными факторами, такими как стресс от ролей и более низкий социальный статус, особенно на репродуктивных и более поздних этапах жизни [61]. Аналогично, наблюдаемое увеличение депрессивных симптомов с возрастом в сельских районах [62, 63], как видно в нашей когорте, может быть связано со снижением физиологических функций, снижением психологической устойчивости и сопутствующими неудобствами образа жизни. Кроме того, в соответствии с предыдущими исследованиями [64, 65], наше исследование выявило более низкий уровень образования как значимый фактор риска. Более низкий уровень образования у сельских жителей среднего и пожилого возраста часто связан с худшими экономическими условиями, сниженной социальной поддержкой и ограниченным доступом к медицинской информации, что препятствует эффективным стратегиям преодоления жизненных стрессоров и проблем со здоровьем. Такие факторы, как отсутствие использования Интернета в нашем исследовании, отражают более широкие проблемы социальной вовлеченности. Действительно, многочисленные исследования подтверждают, что регулярное социальное взаимодействие является важным защитным фактором против депрессии [66,67,68], и наши данные также предполагают связь между увеличением социальной активности и снижением вероятности депрессивных симптомов.
Влияние состояния здоровья:
Критически важно, что наша логистическая регрессия показала, что плохое самочувствие, наличие хронических заболеваний, инвалидность (ADLQ, IADLQ), нарушения слуха, распространенная боль и опыт падений тесно связаны с повышенным риском депрессивных симптомов. Это согласуется с обширной литературой, подтверждающей состояние здоровья как критический предиктор [69,70,71]. Снижение здоровья часто приводит к каскаду негативных последствий, включая снижение качества жизни, функциональные ограничения, увеличение повседневных трудностей и усиление психологического стресса, порождая чувства беспомощности и отчаяния [72, 73].
Возрастная специфика вмешательств:
Кроме того, наши стратифицированные по возрасту логистические регрессионные анализы (Таблицы 3 и 4) подчеркивают необходимость адаптации психологических вмешательств к конкретным возрастным группам. Для пожилых людей (≥60 лет) вмешательства должны быть особенно сосредоточены на смягчении психологического воздействия функциональных ограничений (трудности с ADLQ и IADLQ) и улучшении условий проживания (например, опрятность, доступ к основным коммунальным услугам, таким как газоснабжение). Решение этих проблем может включать усиление поддержки на дому, предоставление вспомогательных устройств и общественные инициативы по улучшению безопасности и комфорта окружающей среды. В отличие от этого, для людей среднего возраста (45–59 лет) психологические вмешательства могут быть более эффективными, если они нацелены на проблемы, связанные с когнитивным здоровьем (такие как устранение проблем с памятью, потенциально посредством когнитивных тренировок или раннего скрининга) и стратегии профилактики падений. Признание этих возрастных уязвимостей позволяет более целенаправленную и потенциально более эффективную поддержку психического здоровья среди сельского населения Китая.
Эти сложные взаимодействия между социодемографическими факторами, образом жизни, состоянием здоровья и психическим благополучием, особенно выраженные в сельских районах с ограниченными ресурсами, подчеркивают необходимость целенаправленных и многогранных вмешательств. Следовательно, наша предложенная стратегия вмешательства, основанная на данных, поэтапная и регионально дифференцированная, направлена на решение этих выявленных уязвимостей:
- Первый этап нашей стратегии соответствует национальной инициативе «Здоровый Китай» (Healthy China), которая уже реализована в относительно благополучных сельских районах юго-восточного Китая. Этот этап включает программы повышения медицинской грамотности на уровне сообществ (ориентированные на лиц с более низким уровнем образования), усилия по обеспечению цифровой инклюзивности (решение проблемы отсутствия доступа в Интернет) и продвижение самоменеджмента хронических заболеваний, профилактики боли и падений, а также осведомленности о слухе.
- Второй этап направлен на расширение этих усилий путем улучшения доступа к первичной медико-санитарной помощи, продвижения лучшей инфраструктуры (например, бытового газоснабжения) и укрепления сетей социальной поддержки для повышения удовлетворенности жизнью и снижения функциональных ограничений.
Этот подход разработан с учетом разнообразных ресурсных ландшафтов сельского Китая и для информирования практических улучшений текущих инициатив в области общественного здравоохранения.
Ограничения исследования
Однако данное исследование имеет несколько ограничений. Во-первых, для практической применимости в сельских районах с ограниченными ресурсами наша модель прагматично исключила подробные клинические симптомы и физиологические показатели. Хотя они имеют большое значение для депрессии [74,75,76], их сбор в контексте сельского здравоохранения создал бы непомерную нагрузку. Следовательно, несмотря на высокую доступность, диагностическая глубина нашей модели может быть ограничена отсутствием таких клинически тонких данных.
Во-вторых, использование данных самоотчетов может вносить систематические ошибки воспоминания и социальной желательности, приводя к недооценке социально осуждаемых поведений или недиагностированных состояний. Например, количество хронических заболеваний может быть занижено, что потенциально влияет на точность предикторных переменных и производительность модели.
В-третьих, степень тяжести депрессии не оценивалась, что ограничивает способность модели различать уровни симптоматического бремени. Будущие исследования должны включать клинически валидированные данные и степень тяжести симптомов для улучшения прогнозирования и стратификации рисков.
В-четвертых, наша модель была разработана и валидирована исключительно в когорте CHARLS. Следовательно, внешняя валидация в независимых сельских когортах, желательно из различных географических регионов Китая или последующих волн CHARLS, необходима для подтверждения ее обобщаемости и надежности перед более широким применением. Будущие исследования также должны изучать региональные факторы риска для разработки индивидуальных предиктивных моделей для депрессивных симптомов в различных сельских китайских населенных пунктах, учитывая потенциальные социокультурные и экономические различия.
Заключение
Разработанная в данном исследовании прогностическая модель эффективно оценивает риск депрессивных симптомов среди людей среднего и пожилого возраста в сельском Китае в течение 3 лет. Используя данные CHARLS и алгоритм Random Forest, модель продемонстрировала сильную прогностическую эффективность. Ключевыми факторами, влияющими на депрессивные симптомы, являются возраст, уровень образования, продолжительность сна, социальная активность, хронические заболевания, самооценка здоровья, привычки к физическим упражнениям, удовлетворенность жизнью, нарушения слуха и инвалидность. Эта модель представляет собой ценный инструмент для целенаправленных вмешательств, направленных на снижение распространенности депрессии и облегчение связанного с ней экономического и медицинского бремени среди сельского населения Китая.