Интересное сегодня


Введение
Английский язык богат вероятностными фразами, такими как «вероятно» или «возможно», которые используются для передачи информации о вероятности событий. Успешная коммуникация зависит от того, насколько точно слушатель понимает, что хочет сказать говорящий. В этом исследовании мы сравниваем, как люди и GPT-4 (Large Language Model от OpenAI) интерпретируют такие фразы в координационной игре.
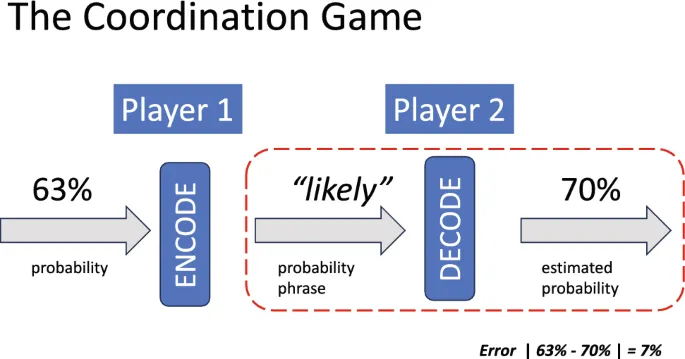
Координационная игра
Координационная игра — это ситуация, где два участника должны согласовать свои действия на основе общих знаний о неопределенности. В нашем случае первый участник (например, врач или финансовый консультант) использует вероятностную фразу, а второй (человек или GPT-4) оценивает, какую вероятность или неоднозначность она передает.
Методы
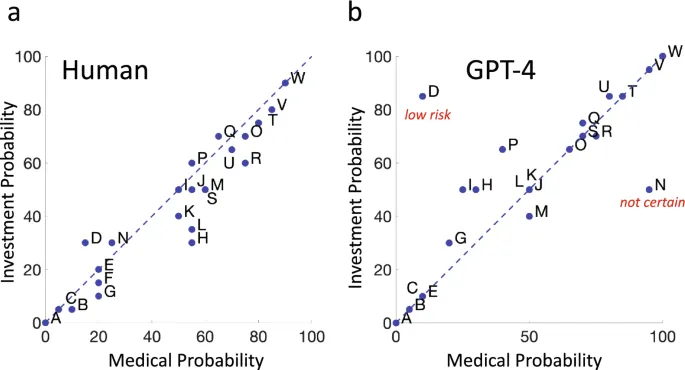
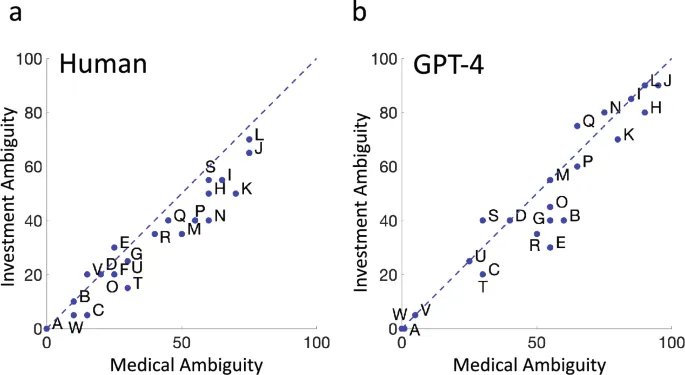
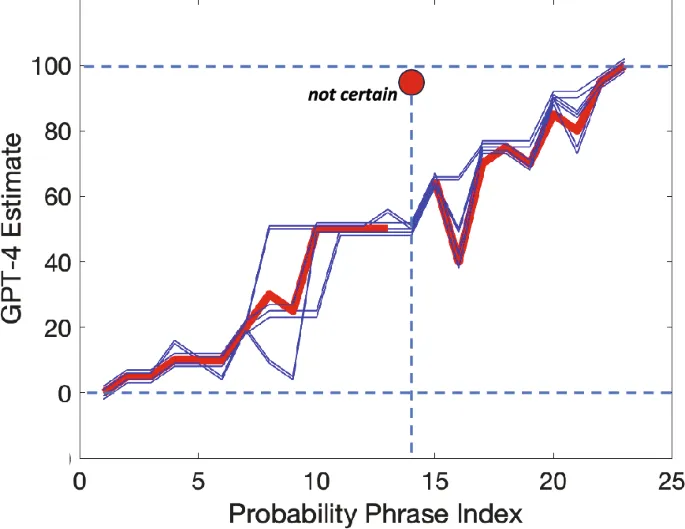
Мы провели два эксперимента: один в контексте медицинских советов, другой — инвестиционных. Участники (25 человек в каждом контексте) и GPT-4 оценивали 23 вероятностные фразы по шкале от 0% до 100%.
Оценка вероятности и неоднозначности
Участники сначала оценивали вероятность, а затем неоднозначность (размытость) каждой фразы. GPT-4 выполнял те же задачи, но мы анализировали только его первый ответ, чтобы избежать искажений.
Результаты
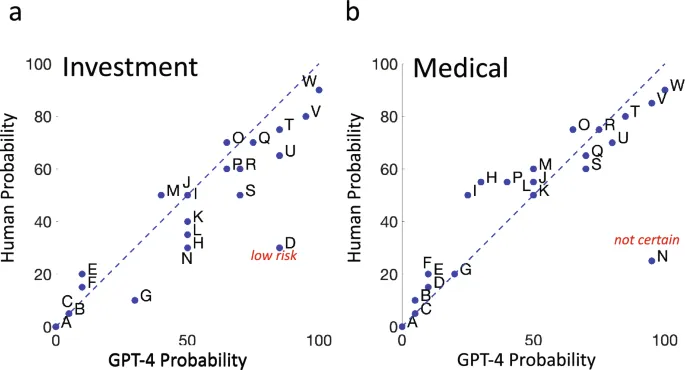
1. Сравнение оценок вероятности
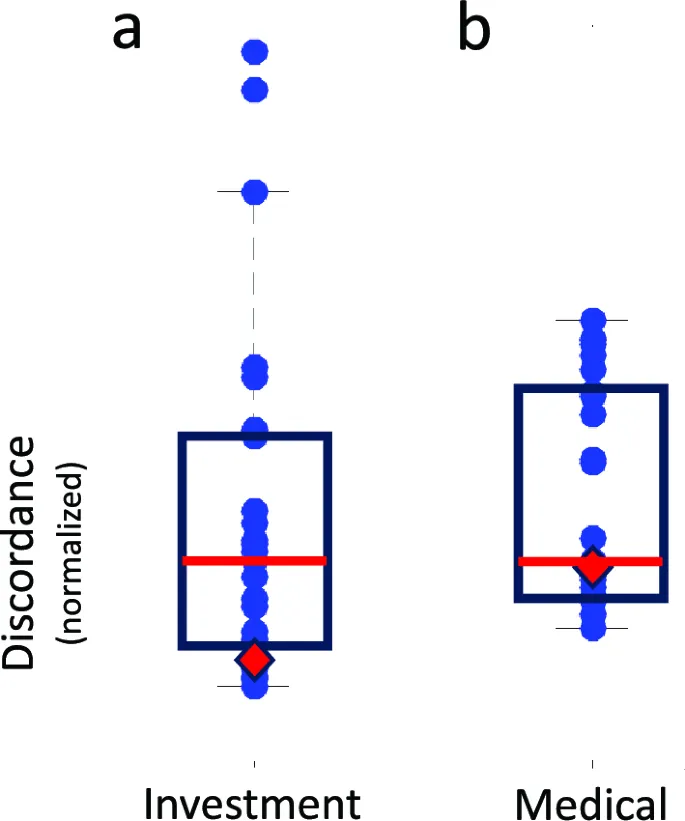
GPT-4 показал результаты, близкие к медианным человеческим оценкам, но с небольшими систематическими отклонениями. В обоих контекстах человеческие оценки были «сжаты» относительно GPT-4 на коэффициент ~0.8.
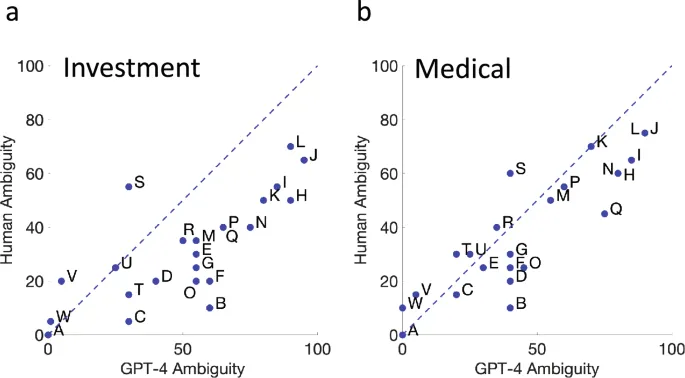
2. Сравнение оценок неоднозначности
Здесь различия были более заметны: человеческие оценки сжимались в 2 раза относительно GPT-4. Однако, поскольку нет стандартной шкалы неоднозначности, это может отражать разницу в интерпретации.
3. Влияние контекста
И люди, и GPT-4 демонстрировали схожие оценки вероятности в медицинском и инвестиционном контекстах. Это означает, что фраза «вероятно» передает одинаковую информацию в обоих случаях.
Выводы
GPT-4 успешно справляется с координационной игрой, но его оценки вероятности и неоднозначности отличаются от человеческих. Эти различия могут быть связаны с когнитивными искажениями у людей. Методы на основе координационных игр полезны для оценки возможностей языковых моделей.